適用対象: Azure Logic Apps (従量課金プラン + Standard)
あらゆる統合アーキテクチャに言えることですが、依存システムに起因するダウンタイムや問題の適切な処理方法には難しい問題が伴うことがあります。 問題やエラーを円滑に処理する堅牢で回復力の高い統合を構築しやすいよう、Azure Logic Apps には、エラーと例外の処理に関してきわめて優れた機能が用意されています。
再試行ポリシー
最も基本的な例外とエラー処理では、HTTP アクションなどのトリガーまたはアクションにこの機能が存在する場合は、再試行ポリシーを使用できます。 トリガーまたはアクションの元の要求がタイムアウトまたは失敗し、408、429、または 5xx 応答が発生した場合は、ポリシー設定に従ってトリガーまたはアクションで要求を再送信するよう、再試行ポリシーで指定します。
再試行ポリシーの制限
再試行ポリシー、設定、制限、および他のオプションについて詳しくは、「再試行ポリシーの制限」をご覧ください。
再試行ポリシーの種類
再試行ポリシーをサポートするコネクタ操作では、別の再試行ポリシーを選択しない限り、既定のポリシーが使用されます。
| 再試行ポリシー | 説明 |
|---|---|
| 既定値 | ほとんどの操作では、既定の再試行ポリシーは指数間隔ポリシーです。これは、"指数関数的に増加する" 間隔で最大 4 回の再試行を送信します。 これらの間隔の増加係数は 7.5 秒であり、下限と上限はそれぞれ 5 秒と 45 秒です。 いくつかの操作では、固定間隔ポリシーなど、別の既定の再試行ポリシーが使用されます。 詳細については、既定の再試行ポリシーの種類を確認してください。 |
| なし | 要求を再送信しません。 詳細については、「なし - 再試行ポリシーなし」を参照してください。 |
| 指数間隔 | このポリシーでは、指数関数的に増加する範囲から選ばれたランダムな間隔だけ待ってから、次の要求を送信します。 詳細については、指数間隔ポリシーの種類を確認してください。 |
| 固定間隔 | このポリシーは、指定された間隔を待ち時間として、次の要求を送信します。 詳細については、固定間隔ポリシーの種類を確認してください。 |
デザイナーで再試行ポリシーの種類を変更する
Azure portal で、ロジック アプリ リソースを開きます。
リソース サイドバーで、次の手順に従って、ロジック アプリに基づいてワークフロー デザイナーを開きます。
消費: [開発ツール] で、デザイナーを選択してワークフローを開きます。
標準
ワークフロー で ワークフロー を選択します。
[ ワークフロー ] ページで、ワークフローを選択します。
[ ツール] で、デザイナーを選択してワークフローを開きます。
再試行ポリシーの種類を変更するトリガーまたはアクションで、次の手順に従って設定を開きます。
デザイナーで操作を選択します。
操作情報ウィンドウで、[ 設定] を選択します。
[ ネットワーク] の [ 再試行ポリシー] で、目的のポリシーの種類を選択します。
コード ビュー エディターで再試行ポリシーの種類を変更する
デザイナーで前の手順を完了して、トリガーまたはアクションが再試行ポリシーをサポートしているかどうかを確認します。
コード ビュー エディターでロジック アプリ ワークフローを開きます。
トリガーまたはアクションの定義で、
retryPolicyJSON オブジェクトをトリガーまたはアクションのinputsオブジェクトに追加します。retryPolicyオブジェクトが存在しない場合、トリガーまたはアクションはdefault再試行ポリシーを使用します。"inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}必須
プロパティ 値 タイプ 説明 type<リトライポリシータイプ> 糸 使用する再試行ポリシーの種類: default、none、fixed、またはexponentialcount<リトライ試行> 整数 fixedとexponentialのポリシーの種類では、再試行の回数 (1 から 90 の値)。 詳しくは、固定間隔と指数間隔に関する説明をご覧ください。interval<retry-interval> 糸 fixedとexponentialのポリシーの種類では、再試行の間隔の値 (ISO 8601 形式)。exponentialポリシーの場合は、必要に応じて最大と最小の間隔を指定することもできます。 詳しくは、固定間隔と指数間隔に関する説明をご覧ください。
従量課金: 5 秒 (PT5S) から 1 日 (P1D)。
Standard: ステートフル ワークフローの場合、5 秒 (PT5S) から 1 日 (P1D)。 ステートレス ワークフローの場合、1 秒 (PT1S) から 1 分 (PT1M)。省略可能
プロパティ 値 タイプ 説明 maximumInterval<最大間隔> 糸 exponentialポリシーで、ランダムに選ばれる間隔の最大値です (ISO 8601 形式)。 既定値は 1 日 (P1D) です。 詳しくは、指数間隔に関する説明をご覧ください。minimumInterval<minimum-interval> 糸 exponentialポリシーで、ランダムに選ばれる間隔の最少値です (ISO 8601 形式)。 既定値は 5 秒 (PT5S) です。 詳しくは、指数間隔に関する説明をご覧ください。
既定の再試行ポリシー
再試行ポリシーをサポートするコネクタ操作では、別の再試行ポリシーを選択しない限り、既定のポリシーが使用されます。 ほとんどの操作では、既定の再試行ポリシーは指数間隔ポリシーです。これは、"指数関数的に増加する" 間隔で最大 4 回の再試行を送信します。 これらの間隔の増加係数は 7.5 秒であり、下限と上限はそれぞれ 5 秒と 45 秒です。 いくつかの操作では、固定間隔ポリシーなど、別の既定の再試行ポリシーが使用されます。
ワークフロー定義では、トリガーまたはアクションの定義で既定のポリシーが明示的に定義されませんが、次の例は、HTTP アクションに対する既定の再試行ポリシーの動作を示しています。
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
なし - 再試行ポリシーなし
失敗した要求を再試行しないようアクションまたはトリガーに指定するには、<retry-policy-type> を none に設定します。
固定間隔の再試行ポリシー
指定した間隔の経過後に次の要求を送信するようアクションまたはトリガーに指定するには、<retry-policy-type> を fixed に設定します。
例
この再試行ポリシーは、最新のニュースを取得する要求が失敗した後、2 回の再試行を行います。それぞれの再試行間には 30 秒の延期期間が設けられます。
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
指数間隔の再試行ポリシー
指数間隔の再試行ポリシーでは、次の要求を送信する前に、トリガーまたはアクションがランダムな間隔だけ待つことを指定します。 このランダムな間隔は、指数関数的に増加する範囲から選ばれます。 必要に応じて、従量課金または Standard のどちらのロジック アプリ ワークフローを使用しているのかに基づいて、独自の最小間隔と最大間隔を指定することにより、既定の最小間隔と最大間隔をオーバーライドできます。
| 名前 | 従量課金の制限 | Standard の制限 | Notes |
|---|---|---|---|
| 最大遅延 | 既定値: 1 日 | 既定値: 1 時間 | 従量課金ロジック アプリ ワークフローの既定の制限を変更するには、再試行ポリシー パラメーターを使います。 Standard ロジック アプリ ワークフローの既定の制限を変更するには、「シングルテナントの Azure Logic Apps でロジック アプリのホストとアプリの設定を編集する」を参照してください。 |
| 最小遅延 | 既定値: 5 秒 | 既定値: 5 秒 | 従量課金ロジック アプリ ワークフローの既定の制限を変更するには、再試行ポリシー パラメーターを使います。 Standard ロジック アプリ ワークフローの既定の制限を変更するには、「シングルテナントの Azure Logic Apps でロジック アプリのホストとアプリの設定を編集する」を参照してください。 |
ランダム変数の範囲
次の表では、指数間隔の再試行ポリシーについて、再試行ごとに指定された範囲内で一様なランダム変数を生成するために Azure Logic Apps で使われる一般的なアルゴリズムを示します。 範囲では、最大の再試行回数 (その値を含む) を指定できます。
| 再試行回数 | 最小間隔 | 最大間隔 |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * インターバル, <最大インターバル>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <最大間隔>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * interval, <maximum-interval>) |
| .... | .... | .... |
"実行条件" の動作を管理する
ワークフロー デザイナーでアクションを追加するときは、それらのアクションを実行するためのシーケンスを暗黙的に宣言します。 アクションの実行が完了した後、そのアクションは Succeeded、Failed、Skipped、TimedOut などの状態でマークされます。 つまり、先行アクションは、後続アクションを実行する前に、許可されているいずれかの状態で最初に終了する必要があります。
既定では、デザイナーに追加したアクションは、上記のアクションが成功状態で完了 した 場合にのみ実行されます。 この 実行後 の動作は、ワークフロー内のアクションの実行順序を正確に指定します。
デザイナーでは、アクションの [後に実行] の設定を編集することで、アクションの既定の "実行後" 動作を変更できます。 この設定は、ワークフローの最初のアクションに続く後続のアクションでのみ使用できます。 ワークフローの最初のアクションは、トリガーが正常に実行された後に常に実行されます。 そのため、[ 実行後に実行 ] 設定は使用できないため、最初のアクションには適用されません。
アクションの基になる JSON 定義では、[ 実行後に実行 ] 設定は runAfter プロパティと同じです。 このプロパティは、後続アクションを実行する前に、特定の許可された状態で最初に終了する必要がある 1 つ以上の先行アクションを指定します。 runAfter プロパティは、後続アクションを実行する前に完了する必要があるすべての先行アクションを指定できるため、柔軟性を提供する JSON オブジェクトです。 このオブジェクトは、許容可能な状態の配列も定義します。
たとえば、アクション A が成功した後、およびアクションの JSON 定義で作業しているときにアクション B が成功または失敗した後にアクションを実行するには、次の runAfter プロパティを設定します。
{
// Other parts in action definition
"runAfter": {
"Action A": ["Succeeded"],
"Action B": ["Succeeded", "Failed"]
}
}
エラー処理の "実行後" の動作
アクションが未処理エラーまたは例外をスローした場合、アクションは Failed としてマークされ、後続処理アクションはすべて Skipped としてマークされます。 並列分岐があるアクションに対してこの動作が発生した場合、Azure Logic Apps エンジンはその他の分岐に従い、完了状態を確認します。 たとえば、分岐が Skipped アクションで終了した場合、その分岐の完了状態はそのスキップされたアクションの先行処理状態に基づきます。 ワークフローの実行が完了すると、すべての分岐の状態を評価することによって、実行全体の状態がエンジンによって決定されます。 分岐のいずれかが失敗すると、ワークフローの実行全体が Failed としてマークされます。

先行処理の状態にかかわらずアクションを引き続き実行できるようにするには、アクションの "実行条件" 動作を変更して、先行処理の失敗状態を処理できます。 それにより、先行処理の状態が Succeeded、Failed、Skipped、TimedOut、またはこれらすべての状態のときに、アクションが実行されます。
たとえば、Excel Online の行をテーブルに追加先行処理アクションが Succeeded ではなく Failed とマークされた後で、Office 365 Outlook のメール送信アクションを実行するには、デザイナーまたはコード ビュー エディターを使って "実行条件" 動作を変更します。
デザイナーで "実行条件" の動作を変更する
Azure portal で、ロジック アプリ リソースを開きます。
リソース サイドバーで、次の手順に従って、ロジック アプリに基づいてワークフロー デザイナーを開きます。
消費: [開発ツール] で、デザイナーを選択してワークフローを開きます。
標準
リソースサイドバーの[ワークフロー]で、[ ワークフロー]を選択 します。
[ ワークフロー ] ページで、ワークフローを選択します。
[ ツール] で、デザイナーを選択してワークフローを開きます。
"実行後" の動作を変更するトリガーまたはアクションで、次の手順に従って操作の設定を開きます。
デザイナーで操作を選択します。
操作情報ウィンドウで、[ 設定] を選択します。
[ 実行後に実行 ] セクションには、[ アクションの選択 ] ボックスの一覧が含まれています。この一覧には、現在選択されている操作で使用可能な先行操作が表示されます。次に例を示します。
![[先行操作を含むアクションの選択] の一覧を示すスクリーンショット。](media/error-exception-handling/predecessor-operations.png)
[ アクションの選択 ] ボックスの一覧で、現在の先行操作 (この例では HTTP ) を展開します。
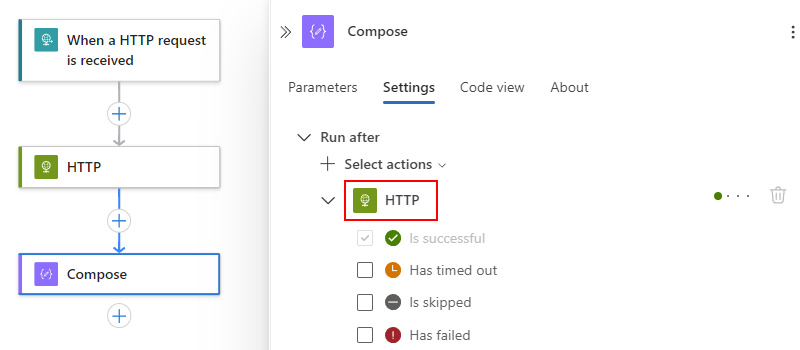
既定では、"実行条件" の状態は [に成功しました] に設定されています。 この値は、現在のアクションを実行する前に先行操作が正常に完了する必要があります。
![状態が [成功] に設定された後の現在の実行を示すスクリーンショット。](media/error-exception-handling/default-run-after-status.png)
"実行条件" の動作を希望の状態に変更するには、それらの状態を選択します。
次の例では、[に失敗しました] が選ばれています。
![[Has failed]\(失敗しました\) に設定された動作の後の現在の実行を示すスクリーンショット。](media/error-exception-handling/failed-run-after-status.png)
先行操作が [失敗、[スキップ]、または [タイムアウト] の状態で完了した場合にのみ現在の操作を実行するように指定するには、これらの状態を選択し、既定の状態をクリアします。次に例を示します。
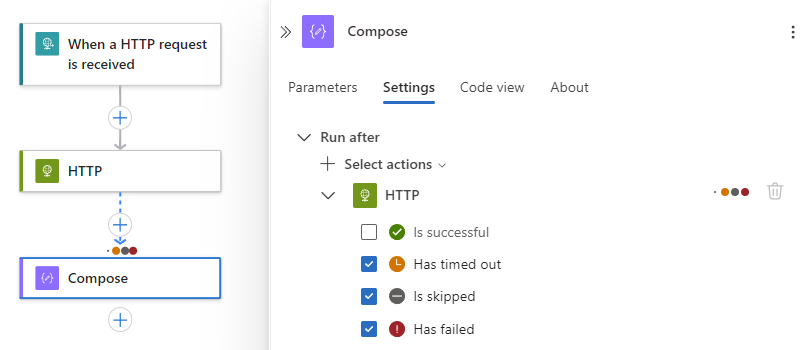
Note
既定の状態をクリアする前に、最初に別の状態を選択してください。 常に少なくとも 1 つの状態が選択されている必要があります。
複数の先行操作を実行して完了するように要求するには、それぞれ独自の "実行後" 状態を持つ、次の手順に従います。
[ アクションの選択 ] ボックスの一覧を開き、必要な先行操作を選択します。
各操作の "実行後" の状態を選択します。
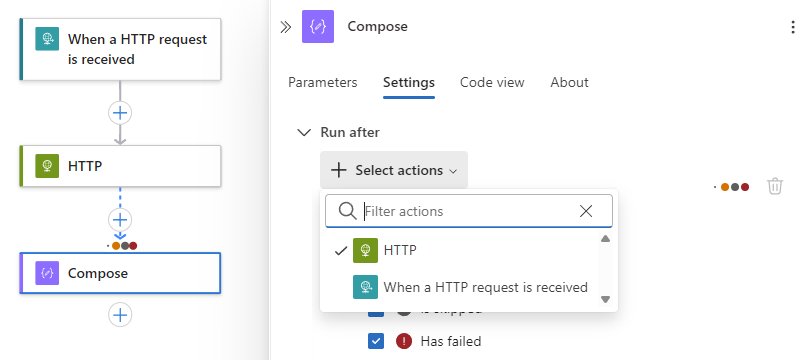
完了したら、操作情報ウィンドウを閉じます。
![[先行操作を含むアクションの選択] の一覧を示すスクリーンショット。](media/error-exception-handling/predecessor-operations.png#lightbox)

![状態が [成功] に設定された後の現在の実行を示すスクリーンショット。](media/error-exception-handling/default-run-after-status.png#lightbox)
![[Has failed]\(失敗しました\) に設定された動作の後の現在の実行を示すスクリーンショット。](media/error-exception-handling/failed-run-after-status.png#lightbox)


コード ビュー エディターで "実行条件" の動作を変更する
リソース サイドバーで、次の手順に従って、ロジック アプリに基づいてコード ビュー エディターを開きます。
使用状況: [開発ツール]でコードビューを選択して、JSONエディターでワークフローを開きます。
標準
ワークフロー で ワークフロー を選択します。
[ ワークフロー ] ページで、ワークフローを選択します。
[ ツール] でコード ビューを選択し、JSON エディターでワークフローを開きます。
アクションの JSON 定義で、次のような構文の
runAfterプロパティを編集します。"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }たとえば、
runAfterプロパティをSucceededからFailedに変更します。"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }先行処理アクションが
Failed、SkippedまたはTimedOutとしてマークされている場合にアクションを実行するように指定するには、その他の状態を追加します。"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
スコープとその結果を使用してアクションを評価する
"実行条件" の設定で個々のアクションの後の手順を実行するのと同じように、アクションをスコープ内にまとめることができます。 アクションを論理的にグループ化し、スコープの集合的な状態を調査し、その状態に基づいてアクションを実行する場合は、スコープを使用できます。 そのスコープ内のすべてのアクションの実行が完了すると、スコープが独自の状態を取得します。
スコープの状態を調べるには、ワークフローの実行状態を調べるのと同じ条件 (Succeeded や Failed など) を使用できます。
既定では、スコープのすべてのアクションが成功すると、そのスコープの状態は Succeeded とマークされます。 スコープの最後のアクションが Failed または Aborted とマークされると、スコープの状態は Failed とマークされます。
Failed スコープの例外をキャッチして、そのエラーを処理するアクションを実行するには、その Failed スコープの"実行条件" の設定を使用できます。 このように、スコープ内の "いずれかの" アクションが失敗したときに、そのスコープに対して "実行条件" の設定を使用している場合、エラーをキャッチする 1 つのアクションを作成できます。
スコープの制限については、制限と構成に関するページをご覧ください。
例外処理用に "実行条件" を使用してスコープを設定する
Azure portal のデザイナーで、ロジック アプリ リソースとワークフローを開きます。
このワークフローには、ワークフローを開始するトリガーが既にある必要があります。
[スコープ] アクションで、次の例のような一般的な手順に従って実行するアクションを追加します。
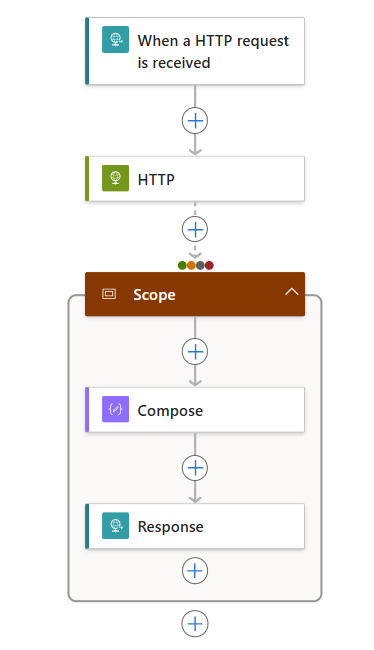
次の一覧に、[スコープ] アクション内に含められる可能性のあるアクションの例をいくつか示します。
- API からデータを取得します。
- データを処理します。
- データベースにデータを保存します。
ここで、スコープ内でアクションを実行するための "実行条件" ルールを定義します。
デザイナーで、[スコープ] タイトルを選択します。 スコープの情報ペインが開いたら、[設定] を選びます。
ワークフローに複数の先行処理アクションがある場合は、[アクションの選択] の一覧から、スコープ付きアクションを実行するアクション条件を選択します。
選択したアクションの場合は、スコープ付きアクションを実行できるすべてのアクションの状態を選択します。
つまり、アクションを選択することで選択された状態のいずれかによってスコープ内のアクションが実行されます。
次の例では、スコープ付きアクションは、 HTTP アクションが完了し、選択された状態のいずれかが完了した後に実行されます。
![スコープ アクションの [設定] タブ、実行条件セクション、スコープ付きアクションを実行する選択されたアクションの状態を示すスクリーンショット。](media/error-exception-handling/set-run-after-in-scope.png)
エラーのコンテキストと結果を取得する
スコープからエラーをキャッチするのは便利ですが、正確な失敗したアクションとエラーまたは状態コードを把握するには、さらにコンテキストが必要になる場合もあります。 result() 関数は、スコープ付きアクションの最上位レベルのアクションからの結果を返します。 この関数は、パラメーターとしてスコープの名前だけを受け取り、それらの最上位レベルのアクションの結果を含む配列を返します。 これらのアクションのオブジェクトには、actions() 関数によって返される属性と同じ属性 (アクションの開始時刻、終了時刻、状態、入力、相関 ID、出力など) があります。
Note
result() 関数からは、最上位レベルのアクションからの結果 "だけ" が返され、スイッチ アクションや条件アクションなど、より深い入れ子のアクションからは返されません。
スコープ内の失敗したアクションに関するコンテキストを取得するには、スコープの名前と "実行条件" の設定を指定した @result() 式を使用します。 返された配列を、Failed 状態のアクションに絞り込むには、配列のフィルター処理アクションを追加できます。 返された失敗アクションに対してアクションを実行するには、返されたフィルター処理済みの配列を取得し、For each ループを使用します。
次の JSON の例では、My_Scope というスコープ アクション内で失敗したすべてのアクションの応答本文を含む HTTP POST 要求が送信されます。 例の後に詳細な説明があります。
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
次の手順では、この例で行われていることを説明します。
My_Scope 内のすべてのアクションの結果を取得するため、配列のフィルター処理アクションでは、
@result('My_Scope')というフィルター式が使用されます[配列のフィルター処理] の条件は、状態が
@result()と等しいすべてのFailed要素です。 この条件により、My_Scope のすべてのアクションの結果を含む配列がフィルター処理され、失敗したアクションの結果のみを抽出した配列が得られます。"
For_each" の出力に対して ループ アクションを実行します。 このステップでは、フィルター処理済みの失敗したアクションの結果ごとに特定のアクションが実行されます。スコープ内の 1 つのアクションが失敗した場合、
For_eachループ内のアクションは 1 回だけ実行されます。 失敗したアクションが複数ある場合は、エラーごとに 1 つのアクションが実行されます。For_each項目の応答本文すなわち@item()['outputs']['body']式で HTTP POST を送信します。@result()項目の構造は@actions()と同じであり、同じ方法で解析することができます。@item()['name']と@item()['clientTrackingId']という 2 つのカスタム ヘッダーが含まれます。前者は失敗したアクションの名前、後者は失敗した実行のクライアント追跡 ID です。
参考例として、前述の例で解析した @result()、name、body の各プロパティを含む 1 つの clientTrackingId 要素を次に示します。 For_each アクションの外側では、@result() によってこれらのオブジェクトの配列が返されます。
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
この記事の前出の式を使用することで、さまざまな例外処理パターンを実行できます。 フィルターで抽出したエラーの配列全体を、スコープ外の単一の例外処理アクションに渡して実行してもかまいません。その場合、For_each は不要です。 前述した \@result() の応答には、他にも便利なプロパティがあるので、それらを含めることもできます。
Azure Monitor ログを設定する
上記のパターンは、実行内で発生したエラーと例外を処理する便利な方法です。 ただし、実行とは別に発生したエラーを特定して対応することもできます。 ログやメトリックを監視したり、それらを好きな監視ツールに発行したりすることによって、実行の状態を評価することができます。
たとえば、Azure Monitor では、すべての実行とアクションの状態など、すべてのワークフロー イベントを宛先に送信する効率的な方法が提供されます。 Azure Monitor では、特定のメトリックとしきい値のアラートを設定できます。 ワークフロー イベントを Log Analytics ワークスペース または Azure ストレージ アカウントに送信することもできます。 または、すべてのイベントを Azure Event Hubs 経由で Azure Stream Analytics にストリーミングすることもできます。 Stream Analytics では、診断ログから得られる異常、平均値、またはエラーに基づいて適宜必要なクエリを記述できます。 Stream Analytics を使用して、キュー、トピック、SQL、Azure Cosmos DB、Power BI などのその他のデータ ソースに情報を送信できます。
詳細については、「Azure Monitor ログを設定し、Azure Logic Apps の診断データを収集する」を参照してください。