Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure AI Search can extract and index both text and images from PDF documents stored in Azure Blob Storage. This tutorial shows you how to build a multimodal indexing pipeline that chunks data based on document structure and uses image verbalization to describe images. Cropped images are stored in a knowledge store, and visual content is described in natural language and ingested alongside text in a searchable index. Chunking is based on the Azure AI Document Intelligence Layout model that recognizes document structure.
To get image verbalizations, each extracted image is passed to the GenAI Prompt skill (preview) that calls a chat completion model to generate a concise textual description. These descriptions, along with the original document text, are then embedded into vector representations using Azure OpenAI’s text-embedding-3-large model. The result is a single index containing searchable content from both modalities: text and verbalized images.
In this tutorial, you use:
A 36-page PDF document that combines rich visual content, such as charts, infographics, and scanned pages, with traditional text.
An indexer and skillset to create an indexing pipeline that includes AI enrichment through skills.
The Document Layout skill (preview) for extracting text and normalized images with its
locationMetadatafrom various documents, such as page numbers or bounding regions.The GenAI Prompt skill (preview) that calls a chat completion model to create descriptions of visual content.
A search index configured to store extracted text and image verbalizations. Some content is vectorized for vector-based similarity search.
Prerequisites
Azure AI services multi-service account. This account provides access to the Document Intelligence Layout model used in this tutorial. You must use an Azure AI multi-service account for skillset access to this resource.
Azure AI Search. Configure your search service for role-based access control and a managed identity. Your service must be on the Basic tier or higher. This tutorial isn't supported on the Free tier.
Azure Storage, used for storing sample data and for creating a knowledge store.
Azure OpenAI with a deployment of
A chat completion model hosted in Azure AI Foundry or another source. The model is used to verbalize image content. You provide the URI to the hosted model in the GenAI Prompt skill definition. You can use any chat completion model.
A text embedding model deployed in Azure AI Foundry. The model is used to vectorize text content pull from source documents and the image descriptions generated by the chat completion model. For integrated vectorization, the embedding model must be located in Azure AI Foundry, and it must be either text-embedding-ada-002, text-embedding-3-large, or text-embedding-3-small. If you want to use an external embedding model, use a custom skill instead of the Azure OpenAI embedding skill.
Visual Studio Code with a REST client.
Limitations
- The Document Layout skill has limited regional availability. For a list of supported regions, see Document Layout skill> Supported regions.
Prepare data
The following instructions apply to Azure Storage which provides the sample data and also hosts the knowledge store. A search service identity needs read access to Azure Storage to retrieve the sample data, and it needs write access to create the knowledge store. The search service creates the container for cropped images during skillset processing, using the name you provide in an environment variable.
Download the following sample PDF: sustainable-ai-pdf
In Azure Storage, create a new container named sustainable-ai-pdf.
Create role assignments and specify a managed identity in a connection string:
Assign Storage Blob Data Reader for data retrieval by the indexer. Assign Storage Blob Data Contributor and Storage Table Data Contributor to create and load the knowledge store. You can use either a system-assigned managed identity or a user-assigned managed identity for your search service role assignment.
For connections made using a system-assigned managed identity, get a connection string that contains a ResourceId, with no account key or password. The ResourceId must include the subscription ID of the storage account, the resource group of the storage account, and the storage account name. The connection string is similar to the following example:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }For connections made using a user-assigned managed identity, get a connection string that contains a ResourceId, with no account key or password. The ResourceId must include the subscription ID of the storage account, the resource group of the storage account, and the storage account name. Provide an identity using the syntax shown in the following example. Set userAssignedIdentity to the user-assigned managed identity The connection string is similar to the following example:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
Prepare models
This tutorial assumes you have an existing Azure OpenAI resource through which the skills a chat completion model for GenAI Prompt and also a text embedding model for vectorization. The search service connects to the models during skillset processing and during query execution using its managed identity. This section gives you guidance and links for assigning roles for authorized access.
You also need a role assignment for accessing the Document Intelligence Layout model via an Azure AI multi-service account.
Assign roles in Azure AI multi-service
Sign in to the Azure portal (not the Foundry portal) and find the Azure AI multi=service account. Make sure it's in a region that provides the Document Intelligence Layout model.
Select Access control (IAM).
Select Add and then Add role assignment.
Search for Cognitive Services User and then select it.
Choose Managed identity and then assign your search service managed identity.
Assign roles in Azure OpenAI
Sign in to the Azure portal (not the Foundry portal) and find the Azure OpenAI resource.
Select Access control (IAM).
Select Add and then Add role assignment.
Search for Cognitive Services OpenAI User and then select it.
Choose Managed identity and then assign your search service managed identity.
For more information, see Role-based access control for Azure OpenAI in Azure AI Foundry Models.
Set up your REST file
For this tutorial, your local REST client connection to Azure AI Search requires an endpoint and an API key. You can get these values from the Azure portal. For alternative connection methods, see Connect to a search service.
For authenticated connections that occur during indexer and skillset processing, the search service uses the role assignments you previously defined.
Start Visual Studio Code and create a new file.
Provide values for variables used in the request. For
@storageConnection, make sure your connection string doesn't have a trailing semicolon or quotation marks. For@imageProjectionContainer, provide a container name that's unique in blob storage. Azure AI Search creates this container for you during skills processing.@searchUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @searchApiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @cognitiveServicesUrl = PUT-YOUR-AZURE-AI-MULTI-SERVICE-ENDPOINT-HERE @openAIResourceUri = PUT-YOUR-OPENAI-URI-HERE @openAIKey = PUT-YOUR-OPENAI-KEY-HERE @chatCompletionResourceUri = PUT-YOUR-CHAT-COMPLETION-URI-HERE @chatCompletionKey = PUT-YOUR-CHAT-COMPLETION-KEY-HERE @imageProjectionContainer=sustainable-ai-pdf-imagesSave the file using a
.restor.httpfile extension. For help with the REST client, see Quickstart: Full-text search using REST.
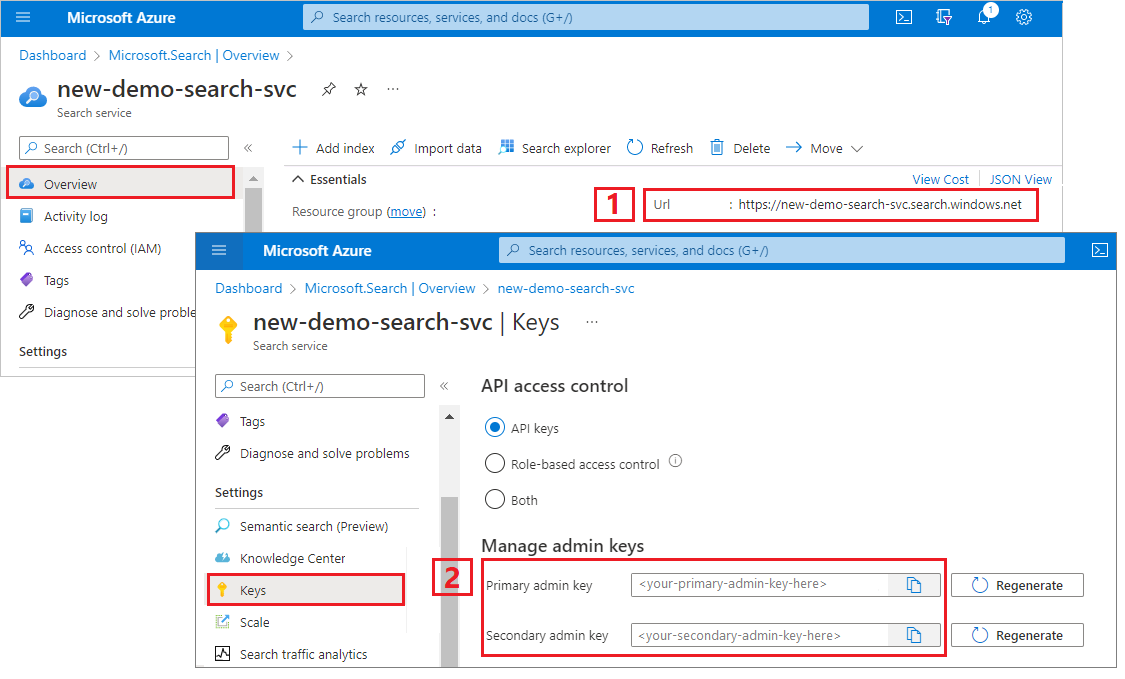
To get the Azure AI Search endpoint and API key:
Sign in to the Azure portal, navigate to the search service Overview page, and copy the URL. An example endpoint might look like
https://mydemo.search.windows.net.Under Settings > Keys, copy an admin key. Admin keys are used to add, modify, and delete objects. There are two interchangeable admin keys. Copy either one.
Create a data source
Create Data Source (REST) creates a data source connection that specifies what data to index.
### Create a data source using system-assigned managed identities
POST {{searchUrl}}/datasources?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-ds",
"description": "A data source to store multi-modality documents",
"type": "azureblob",
"subtype": null,
"credentials":{
"connectionString":"{{storageConnection}}"
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Send the request. The response should look like:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-multimodal-embedding-ds')?api-version=2025-05-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-multimodal-embedding-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Create an index
Create Index (REST) creates a search index on your search service. An index specifies all the parameters and their attributes.
For nested JSON, the index fields must be identical to the source fields. Currently, Azure AI Search doesn't support field mappings to nested JSON, so field names and data types must match completely. The following index aligns to the JSON elements in the raw content.
### Create an index
POST {{searchUrl}}/indexes?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "demo-vectorizer"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "demo-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
Key points:
Text and image embeddings are stored in the
content_embeddingfield and must be configured with appropriate dimensions, such as 3072, and a vector search profile.location_metadatacaptures bounding polygon and page number metadata for each text chunk and normalized image, enabling precise spatial search or UI overlays.For more information on vector search, see Vectors in Azure AI Search.
For more information on semantic ranking, see Semantic ranking in Azure AI Search
Create a skillset
Create Skillset (REST) creates a skillset on your search service. A skillset defines the operations that chunk and embed content prior to indexing. This skillset uses the Document Layout skill to extract text and images, preserving location metadata which is useful for citations in RAG applications. It uses Azure OpenAI Embedding skill to vectorize text content.
The skillset also performs actions specific to images. It uses the GenAI Prompt skill to generate image descriptions. It also creates a knowledge store that stores intact images so that you can return them in a query.
### Create a skillset
POST {{searchUrl}}/skillsets?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-skillset",
"description": "A sample skillset for multi-modality using image verbalization",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "document-cracking-skill",
"description": "Document Layout skill for document cracking",
"context": "/document",
"outputMode": "oneToMany",
"outputFormat": "text",
"extractionOptions": ["images", "locationMetadata"],
"chunkingProperties": {
"unit": "characters",
"maximumLength": 2000,
"overlapLength": 200
},
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "text_sections",
"targetName": "text_sections"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Azure Open AI Embedding skill for text",
"context": "/document/text_sections/*",
"inputs": [
{
"name": "text",
"source": "/document/text_sections/*/content"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verbalizedImage-embedding-skill",
"description": "Azure Open AI Embedding skill for verbalized image embedding",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='my_container_name/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "doc-intelligence-image-verbalization-index",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/text_sections/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/text_sections/*/text_vector"
},
{
"name": "content_text",
"source": "/document/text_sections/*/content"
},
{
"name": "location_metadata",
"source": "/document/text_sections/*/locationMetadata"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "doc-intelligence-image-verbalization-index",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "location_metadata",
"source": "/document/normalized_images/*/locationMetadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"identity": null,
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
This skillset extracts text and images, verbalizes images, and shapes the image metadata for projection into the index.
Key points:
The
content_textfield is populated in two ways:From document text extracted and chunked using the Document Layout skill.
From image content using the GenAI Prompt skill, which generates descriptive captions for each normalized image
The
content_embeddingfield contains 3072-dimensional embeddings for both page text and verbalized image descriptions. These are generated using the text-embedding-3-large model from Azure OpenAI.content_pathcontains the relative path to the image file within the designated image projection container. This field is generated only for images extracted from documents whenextractOptionis set to["images", "locationMetadata"]or["images"], and can be mapped from the enriched document from the source field/document/normalized_images/*/imagePath.The Azure OpenAI embeddings skill enables embedding of textual data. For more information, see Azure OpenAI Embedding skill.
Create and run an indexer
Create Indexer creates an indexer on your search service. An indexer connects to the data source, loads data, runs a skillset, and indexes the enriched data.
### Create and run an indexer
POST {{searchUrl}}/indexers?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"dataSourceName": "doc-intelligence-image-verbalization-ds",
"targetIndexName": "doc-intelligence-image-verbalization-index",
"skillsetName": "doc-intelligence-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
Run queries
You can start searching as soon as the first document is loaded.
### Query the index
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true
}
Send the request. This is an unspecified full-text search query that returns all of the fields marked as retrievable in the index, along with a document count. The response should look like:
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-05-01-preview "
}
100 documents are returned in the response.
For filters, you can also use Logical operators (and, or, not) and comparison operators (eq, ne, gt, lt, ge, le). String comparisons are case -sensitive. For more information and examples, see Examples of simple search queries.
Note
The $filter parameter only works on fields that were marked filterable during index creation.
### Query for only images
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (only populated for text chunks), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
Reset and rerun
Indexers can be reset to clear execution history, which allows a full rerun. The following POST requests are for reset, followed by rerun.
### Reset the indexer
POST {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/reset?api-version=2025-05-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Run the indexer
POST {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/run?api-version=2025-05-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Check indexer status
GET {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/status?api-version=2025-05-01-preview HTTP/1.1
api-key: {{searchApiKey}}
Clean up resources
When you're working in your own subscription, at the end of a project, it's a good idea to remove the resources that you no longer need. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
You can use the Azure portal to delete indexes, indexers, and data sources.
See also
Now that you're familiar with a sample implementation of a multimodal indexing scenario, check out: