Extract, transform, and load (ETL)
A common problem that organizations face is how to gather data from multiple sources, in multiple formats. Then you'd need to move it to one or more data stores. The destination might not be the same type of data store as the source. Often the format is different, or the data needs to be shaped or cleaned before loading it into its final destination.
Various tools, services, and processes have been developed over the years to help address these challenges. No matter the process used, there's a common need to coordinate the work and apply some level of data transformation within the data pipeline. The following sections highlight the common methods used to perform these tasks.
Extract, transform, load (ETL) process
extract, transform, load (ETL) is a data pipeline used to collect data from various sources. It then transforms the data according to business rules, and it loads the data into a destination data store. The transformation work in ETL takes place in a specialized engine, and it often involves using staging tables to temporarily hold data as it is being transformed and ultimately loaded to its destination.
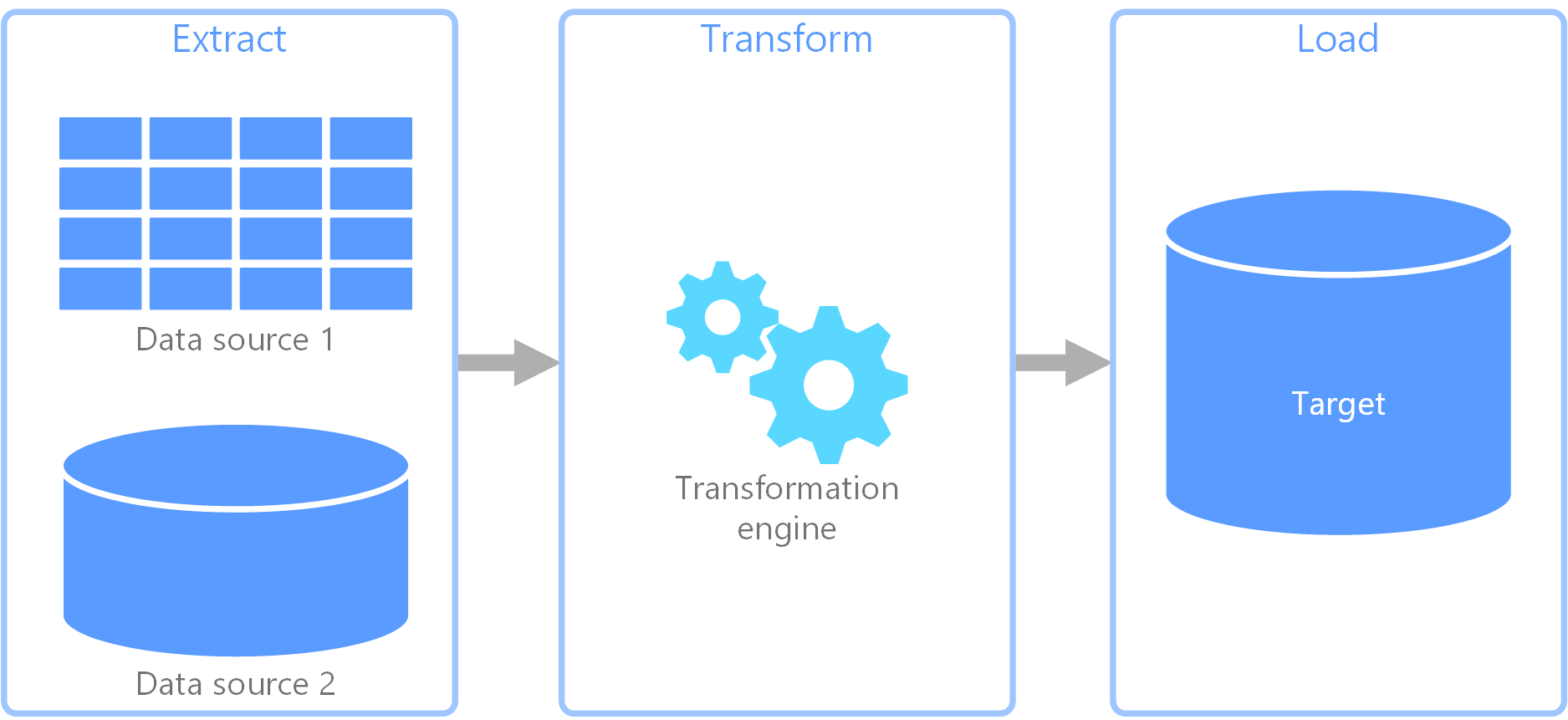
The data transformation that takes place usually involves various operations, such as filtering, sorting, aggregating, joining data, cleaning data, deduplicating, and validating data.
Often, the three ETL phases are run in parallel to save time. For example, while data is being extracted, a transformation process could be working on data already received and prepare it for loading, and a loading process can begin working on the prepared data, rather than waiting for the entire extraction process to complete.
Relevant service:
Other tools:
Extract, load, transform (ELT)
Extract, load, transform (ELT) differs from ETL solely in where the transformation takes place. In the ELT pipeline, the transformation occurs in the target data store. Instead of using a separate transformation engine, the processing capabilities of the target data store are used to transform data. This simplifies the architecture by removing the transformation engine from the pipeline. Another benefit to this approach is that scaling the target data store also scales the ELT pipeline performance. However, ELT only works well when the target system is powerful enough to transform the data efficiently.
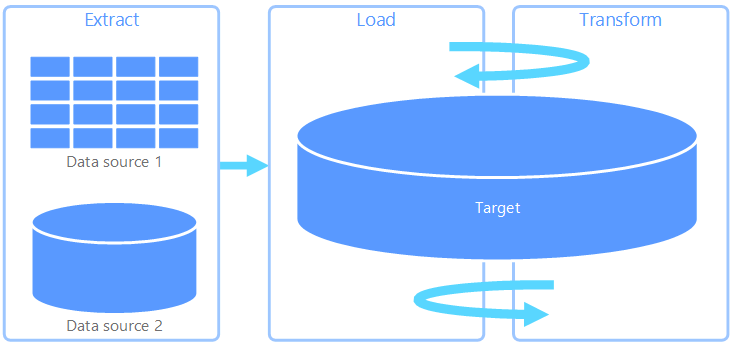
Typical use cases for ELT fall within the big data realm. For example, you might start by extracting all of the source data to flat files in scalable storage, such as a Hadoop Distributed File System, an Azure blob store, or Azure Data Lake gen 2 (or a combination). Technologies, such as Spark, Hive, or PolyBase, can then be used to query the source data. The key point with ELT is that the data store used to perform the transformation is the same data store where the data is ultimately consumed. This data store reads directly from the scalable storage, instead of loading the data into its own proprietary storage. This approach skips the data copy step present in ETL, which often can be a time consuming operation for large data sets.
The final phase of the ELT pipeline is typically to transform the source data into a final format that is more efficient for the types of queries that need to be supported. For example, the data may be partitioned. Also, ELT might use optimized storage formats like Parquet, which stores row-oriented data in a columnar fashion and provides optimized indexing.
Relevant Microsoft service:
Data flow and control flow
In the context of data pipelines, the control flow ensures the orderly processing of a set of tasks. To enforce the correct processing order of these tasks, precedence constraints are used. You can think of these constraints as connectors in a workflow diagram, as shown in the image below. Each task has an outcome, such as success, failure, or completion. Any subsequent task does not initiate processing until its predecessor has completed with one of these outcomes.
Control flows execute data flows as a task. In a data flow task, data is extracted from a source, transformed, or loaded into a data store. The output of one data flow task can be the input to the next data flow task, and data flows can run in parallel. Unlike control flows, you cannot add constraints between tasks in a data flow. You can, however, add a data viewer to observe the data as it is processed by each task.
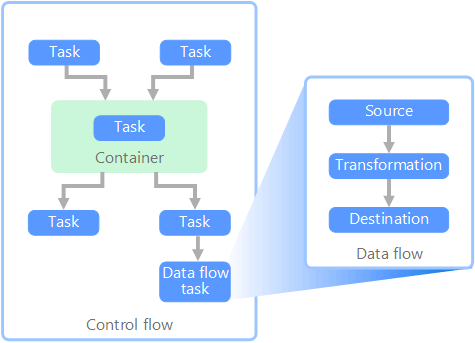
In the diagram above, there are several tasks within the control flow, one of which is a data flow task. One of the tasks is nested within a container. Containers can be used to provide structure to tasks, providing a unit of work. One such example is for repeating elements within a collection, such as files in a folder or database statements.
Relevant service:
Streaming data and hot path architectures (push, transform, and load)
When you have a need for Lambda hot path or Kappa architectures, another option is to subscribe to various data sources as data is being generated. Unlike ETL or ELT, which operate on datasets in scheduled batches, real-time streaming processes data as it arrives, enabling immediate insights and actions.
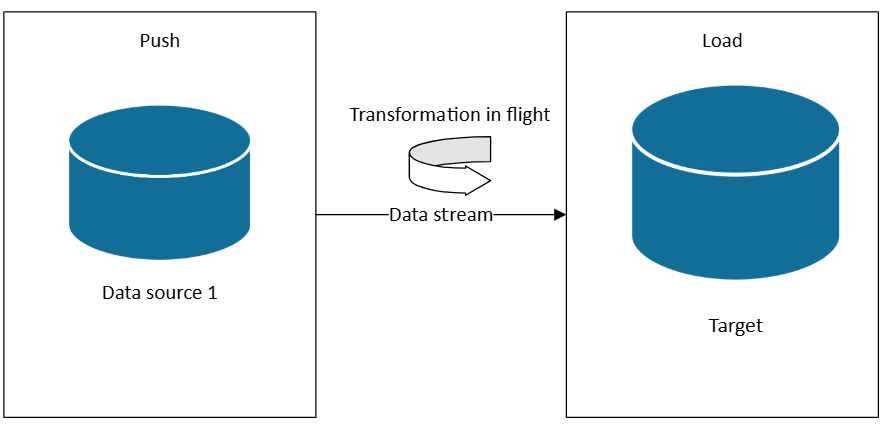
In a streaming architecture, data is ingested from event sources into a message broker or event hub (e.g., Azure Event Hubs, Kafka), then processed by a stream processor (e.g., Fabric Real-Time Intelligence, Azure Stream Analytics, Apache Flink). The processor applies transformations such as filtering, aggregating, enriching, or joining with reference data—all in motion—before routing the results to downstream systems like dashboards, alerts, or databases.
This approach is ideal for scenarios where low latency and continuous updates are critical, such as:
- Monitoring manufacturing equipment for anomalies
- Detecting fraud in financial transactions
- Powering real-time dashboards for logistics or operations
- Triggering alerts based on sensor thresholds
Technology choices
- Online Transaction Processing (OLTP) data stores
- Online Analytical Processing (OLAP) data stores
- Data warehouses
- Pipeline orchestration
Next steps
Related resources
The following reference architectures show end-to-end ELT pipelines on Azure: