变形金刚
如今的生成式 AI 应用程序由语言模型提供支持,这是一种专用的机器学习模型,可用于执行自然语言处理 (NLP) 任务,包括:
- 确定情绪或以其他方式对自然语言文本进行分类。
- 汇总文本。
- 比较多个文本源的语义相似性。
- 生成新的自然语言。
虽然这些语言模型背后的数学原理可能比较复杂,但对用于实现它们的体系结构有基本的了解可以帮助你从概念上了解它们的工作原理。
Transformer 模型
自然语言处理的机器学习模型已经过多年的演变。 当今最先进的大型语言模型基于 Transformer 体系结构,该体系结构基于一些技术并进行了扩展,这些技术已被证明可以成功地对词汇表进行建模,以支持 NLP 任务,特别是在生成语言方面。 Transformer 模型使用大量文本进行训练,使它们能够表示单词之间的语义关系,并使用这些关系来确定可能有意义的文本序列。 Transformer 模型拥有大量词汇,足以生成与我们人类相似的自然语言响应。
Transformer 模型体系结构包含两个组件(或块):
- 编码器块,用于创建训练词汇的语义表示形式。
- 解码器块,用于生成新的语言序列。
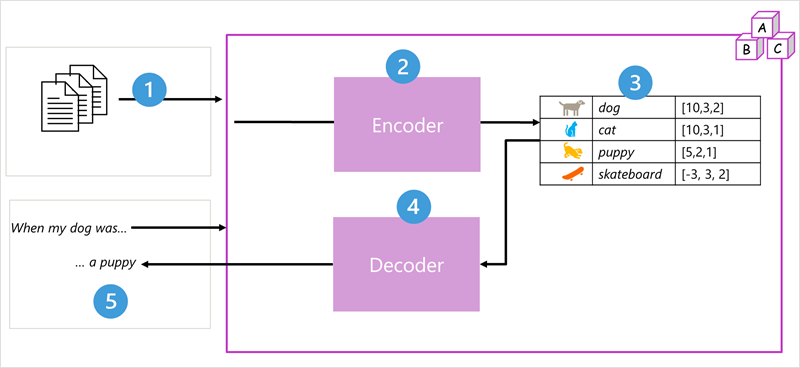
- 该模型使用大量自然语言文本进行训练,这些文本通常来自 Internet 或其他公共文本源。
- 文本序列被分解成标记(例如单个字词),然后编码器块使用一种称为“注意”的技术来处理这些标记序列,以确定标记之间的关系(例如,哪些标记影响序列中其他标记的存在,哪些不同的标记通常在同一上下文中使用,等等)。
- 编码器的输出是一组矢量(多值数值数组),其中矢量的每个元素代表标记的语义属性。 这些矢量称为嵌入。
- 解码器块处理新的文本标记序列,并使用编码器生成的嵌入来生成适当的自然语言输出。
- 例如,给定一个输入序列(如
"When my dog was"),模型可以使用自注意力技术来分析输入词元和嵌入中编码的语义属性,以预测正确完成的句子,如"a puppy"。
实际上,体系结构的具体实现各不相同,例如,Google 开发的用于支持其搜索引擎的基于 Transformers 的双向编码表征 (Bidirectional Encoder Representations from Transformers, BERT) 模型仅使用编码器块,而 OpenAI 开发的生成式预训练 Transformer 模型仅使用解码器块。
虽然对 Transformer 模型各个方面的完整解释超出了本模块的范围,但对 Transformer 中的一些关键元素的解释有助于你了解它们如何支持生成式 AI。
词汇切分
训练 Transformer 模型的第一步是将训练文本分解为标记,也就是标识每个唯一的文本值。 为简单起见,可以将训练文本中的每个不同单词视为一个标记(但实际上,可以为部分单词生成多个标记,或者将单词和标点符号组合起来)。
例如,考虑以下句子:
I heard a dog bark loudly at a cat
若要标记此文本,可以标识每个离散单词,并为其分配标记 ID。 例如:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- ("a" is already tokenized as 3)
- cat (8)
现在可以使用以下标记来表示这句话:{1 2 3 4 5 6 7 3 8}。 同样,"I heard a cat" 这句话可以表示为 {1 2 3 8}。
在继续训练模型时,训练文本中的每个新标记都会添加到具有相应标记 ID 的词汇中:
- meow (9)
- skateboard (10)
- *and so on...*
使用足够大的训练文本集,可以编译包含数千个标记的词汇。
嵌入
虽然可以将标记表示为简单的 ID(主要是为词汇表中的所有单词创建索引),但通过这种方式,我们无从知晓单词的含义或各单词之间的关系。 为了创建可封装标记之间的语义关系的词汇,我们为其定义了上下文向量(称为嵌入)。 向量是信息的多值数值表示形式,例如 [10, 3, 1],其中每个数值元素都表示信息的一个特定属性。 对于语言标记,标记向量的每个元素表示该标记的某种语义属性。 语言模型中向量元素的特定类别在训练期间取决于单词一起使用或在类似上下文中的常用程度。
矢量表示多维空间中的线条,描述沿多个轴的方向和距离(可以通过调用这些幅度和量级来给数学家朋友们留下深刻的印象)。 将标记的嵌入向量中的各个元素,视为在多维空间中沿路径的步骤,这种思维方式很有用。 例如,具有三个元素的矢量表示三维空间中的路径,其中元素值指示向前/向后、向左/向右和向上/向下行进的单位数。 总体来说,矢量描述路径从原点到终点的方向和距离。
嵌入空间中的标记的每个元素都代表标记的某个语义属性,因此语义相似的标记应该生成具有相似方向的矢量 - 换句话说,它们指向相同的方向。 一种称为余弦相似度的技术用于确定两个矢量是否具有相似的方向(无论距离如何),如果是则代表语义相关的单词。 举个简单的例子,假设标记的嵌入由包含三个元素的向量组成,例如:
- 4 ("dog"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("puppy"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
我们可以在三维空间中绘制这些矢量,如下所示:
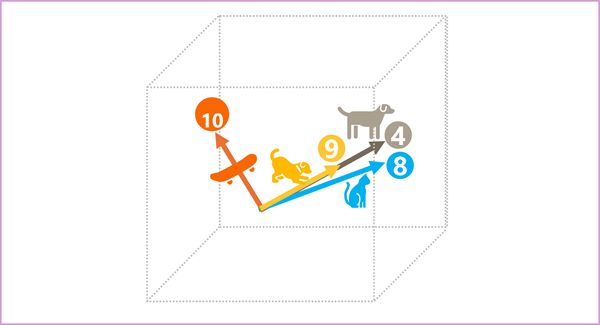
“"dog"”和“"puppy"”的嵌入向量描述了几乎相同方向的路径,这与“"cat"”的方向也很相似。 然而,嵌入向量 "skateboard" 描述了通向截然不同方向的旅程。
注释
上面的示例演示了一个简单的示例模型,其中每个嵌入只有三个维度。 而真实的语言模型具有更多维度。
有多种方法可以计算给定标记集的适当嵌入,包括语言建模算法(如 Word2Vec 或 Transformer 模型中的编码器块)。
注意力
Transformer 模型中的编码器块和解码器块包括构成模型的神经网络的多个层。 我们不需要深入了解所有这些层的详细信息,但有必要考虑在这两个块中使用的注意力层这一层类型。 注意力是一种技术,可用于检查文本标记序列并尝试量化它们之间的关系强度。 具体而言,自注意力需要考虑某个特定标记周围的其他标记如何影响该标记的含义。
在编码器块中,在上下文中仔细检查每个令牌,并为其矢量嵌入确定适当的编码。 向量值基于该标记与它经常出现的其他标记之间的关系。 这种注重上下文环境的方法意味着同一个词可能具有多个嵌入,具体取决于其使用的上下文,例如,“"the bark of a tree"”的含义与“"I heard a dog bark"”不同。
在解码器块中,注意力层用于预测序列中的下一个标记。 对于生成的每个标记,模型都有一个注意力层,该层会考虑截至该点为止的标记序列。 在考虑下一个标记时,模型会考虑哪些标记最具影响力。 例如,给定序列“"I heard a dog"”,在考虑序列中的下一个单词时,注意力层可能会为标记“"heard"”和“"dog"”分配更大的权重:
I *heard* a *dog* {*bark*}
请记住,注意力层使用的是标记的数值向量表示形式,而不是实际文本。 在解码器中,该过程从一系列表示要完成的文本的标记嵌入开始。 发生的第一件事是,另一个位置编码层会向每个嵌入添加一个值,以指示其在序列中的位置:
- [1,5,6,2](I)
- [2,9,3,1](听到)
- [3,1,1,2](a)
- [4,10,3,2](狗)
在训练期间,目标是根据前面的标记预测序列中最终标记的向量。 注意力层会将数字权重分配给目前为止序列中的每个标记。 它会使用该值对加权向量执行计算,生成可用于计算下一个标记的可能向量的注意力分数。 在实际中,一种称为“多头注意力”的技术会使用嵌入的不同元素来计算多个注意力分数。 然后,使用神经网络来评估所有可能的标记,以确定要继续该序列的最可能标记。 对于序列中的每个标记,该过程都会以迭代方式继续,到目前为止的输出序列会以回归方式用作下一次迭代的输入,实质上是一次生成一个标记的输出。
以下动画演示了其工作原理的简化表示,实际上,注意力层执行的计算要复杂得多;但可以简化这些原理,如下所示:

- 标记嵌入的序列被馈送到注意力层。 每个标记都表示为数值的向量。
- 解码器的目标是预测序列中的下一个标记,该标记也是一个向量,与模型词汇中的嵌入一致。
- 注意力层会评估到目前为止的序列,并将权重分配给每个标记,以表示它们对下一个标记的相对影响。
- 权重可用于计算具有注意力分数的下一个标记的新向量。 多头注意力在嵌入中使用不同的元素来计算多个备用标记。
- 完全连接的神经网络使用计算向量中的分数来预测整个词汇表中最有可能的标记。
- 预测的输出将附加到到目前为止的序列中,用作下一次迭代的输入。
在训练期间,标记的实际序列是已知的,我们只是会屏蔽序列中比当前正在考虑的标记位置出现得更晚的标记。 与在任何神经网络中一样,也需要将标记向量的预测值与序列中下一个向量的实际值进行比较,并计算损失。 然后以增量方式调整权重,以减少损失并改进模型。 当用于推理(预测)的新标记序列时,训练的注意力层会应用权重来预测模型词汇中与序列语义上保持一致的最可能标记。
这一切都意味着,GPT-4(ChatGPT 和 Bing 背后的模型)等 Transformer 模型旨在接收文本输入(称为提示)并生成语法上正确的输出(称为补全)。 实际上,模型的“神奇之处”在于它能够将一个连贯的句子串在一起。 拥有这种能力并不意味着模型有任何“知识”或“智能”;只是有大量的词汇量和生成有意义的单词序列的能力。 然而,像 GPT-4 这样的大型语言模型之所以如此强大,是因为它所训练的数据(来自 Internet 的公共数据和获得许可的数据)的数量庞大以及网络的复杂性。 通过这种方式,模型可以根据训练模型的词汇表中单词之间的关系生成补全;通常会生成与人类对同一提示的回答相似的输出。