适用于:![]() MicrosoftFabric 预览版中的 SQL Server 2016 (13.x) 及更高版本
MicrosoftFabric 预览版中的 SQL Server 2016 (13.x) 及更高版本 ![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例![]() SQL 数据库
SQL 数据库
可以使用标准索引优化对 JSON 文档的查询。
数据类型:
- 普遍适用于 Fabric 中的 Azure SQL 数据库和 SQL 数据库。
- 在配置了 Always-up-to-date 更新策略的 Azure SQL 托管实例中,现已普遍可用。
- 是 SQL Server 2025 (17.x) 预览版的预览版。
Note
在 SQL Server 2025(17.x) 预览版中,可以使用 CREATE JSON INDEX (Transact-SQL) 功能。
索引的工作方式与 varcharnvarchar/ 或本机 json 数据类型中的 JSON 数据的工作方式相同。
数据库索引可提高筛选和排序操作的性能。 如果没有索引,则每次查询数据时,SQL Server 不得不扫描整个表。
通过使用计算列对 JSON 属性编制索引
在 SQL Server 中存储 JSON 数据时,通常希望按 JSON 文档的一个或多个 属性 筛选或排序查询结果。
Example
此示例假定 AdventureWorks.SalesOrderHeader 表包含 Info 列,此列包含关于销售订单的采用 JSON 格式的各种信息。 例如,它包含客户、销售人员、装运和帐单邮寄地址等非结构化数据。 你可以使用 Info 列中的值来筛选客户的销售订单。
默认情况下,使用的列 Info 不存在,可以使用以下代码在 AdventureWorks 数据库中创建它。 以下示例不适用于 AdventureWorksLT 一系列示例数据库。
IF NOT EXISTS (SELECT *
FROM sys.columns
WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]')
AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader]
ADD [Info] NVARCHAR (MAX) NULL;
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c
ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p
ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
要优化的查询
以下示例说明想要使用索引进行优化的查询类型。
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell';
Example index
如果想要对 JSON 文档中的某个属性加快筛选或 ORDER BY 子句的速度,你可以使用已用于其他列的索引。 但是,不能 直接 引用 JSON 文档中的属性。
- 首先创建一个“虚拟列”,用于返回你要用于筛选的值。
- 然后,对该虚拟列创建索引。
下面的示例创建可用于编制索引的计算列。 然后对此新计算列创建索引。 此示例创建一个公开客户名称的列,客户名称存储在 $.Customer.Name 路径中的 JSON 数据内。
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info, '$.Customer.Name');
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName);
此语句将返回以下警告:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
该 JSON_VALUE 函数可能返回最多 8000 字节的文本值(例如,作为 nvarchar(4000) 类型)。 但是,不能为超过 1700 字节的值编制索引。 如果尝试在索引计算列中输入超过 1700 字节的值,数据操作语言 (DML) 操作将失败。
为了提升性能,请尝试将使用计算列公开的值强制转换为最小的适用数据类型。 使用 int 和 datetime2 类型,而不是字符串类型。
关于计算列的详细信息
计算列不是永久性的。 仅当需要重新生成索引时,才会对计算列进行计算。 它不会占用表中的额外空间。
请务必使用你计划在查询中使用的相同表达式来创建计算列 - 在此示例中,此表达式为 JSON_VALUE(Info, '$.Customer.Name')。
你无须重新编写查询。 如果你将表达式与 JSON_VALUE 函数配合使用,如前面的示例查询中所示,则 SQL Server 会认为存在具有相同表达式的等效计算列,并会在可能的情况下应用索引。
此示例的执行计划
下面是此示例中的查询执行计划。
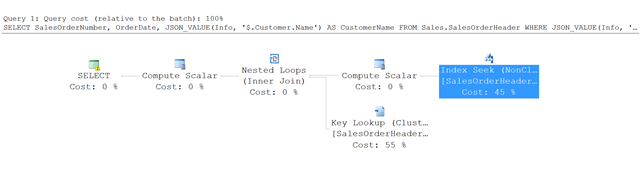
SQL Server 不使用全表扫描,而是使用索引查找非聚集索引并查找满足指定条件的行。 然后它在 SalesOrderHeader 表中使用键查找来提取查询中引用的其他列 - 在此示例中为 SalesOrderNumber 和 OrderDate。
通过包含的列进一步优化索引
如果在索引中添加所需的列,则可以避免在表中进行这种额外的查找。 你可以将这些列添加为标准包含列,如以下示例中所示,这是对前面的 CREATE INDEX 示例的延伸。
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber, OrderDate);
在这种情况下,SQL Server 不必从 SalesOrderHeader 表中读取更多数据,因为它所需的全部内容都包含在非聚集 JSON 索引中。 这种类型的索引是将查询中的 JSON 和列数据结合起来并为工作负载创建最佳索引的好方法。
JSON 索引是可识别排序规则的索引
索引可识别排序规则,这是针对 JSON 数据的一个重要索引功能。 创建计算列时使用的 JSON_VALUE 函数的结果是从输入表达式继承其排序规则的文本值。 因此,将使用源列中定义的排序规则对索引中的值进行排序。
为了证明索引是排序感知索引,以下示例创建了一个具有主键和 JSON 内容的简单集合表。
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR (MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON] CHECK (ISJSON(json) > 0)
);
前一个命令指定 json 列的塞尔维亚西里尔文排序规则。 后面的示例填充此表,并对名称属性创建索引。
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}');
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json, '$.name');
CREATE INDEX idx_name
ON JsonCollection(vName);
前面的命令对计算列 vName 创建标准索引,它表示 JSON $.name 属性中的值。 在塞尔维亚西里尔文代码页中,字母的顺序是 А、Б、В、Г、Д、Ђ、Е 等。索引中的项的顺序符合塞尔维亚西里尔文规则,因为 JSON_VALUE 函数的结果从源列继承其排序规则。 以下示例查询此集合并按名称对结果进行排序。
SELECT JSON_VALUE(json, '$.name'),
*
FROM JsonCollection
ORDER BY JSON_VALUE(json, '$.name');
如果查看实际的执行计划,会发现它使用非聚集索引中经过排序的值。

虽然查询具有 ORDER BY 子句,但执行计划不使用 Sort 运算符。 JSON 索引已按照塞尔维亚西里尔文规则排序。 因此 SQL Server 可使用其中的结果已经过排序的非聚集索引。
但是,如果更改 ORDER BY 表达式的排序规则(例如,如果将 COLLATE French_100_CI_AS_SC 添加到 JSON_VALUE 函数之后),会获得其他查询执行计划。

由于索引中的值顺序不符合法国排序规则,因此 SQL Server 无法使用索引对结果进行排序。 因此,它会添加一个使用法语排序规则对结果进行排序的 Sort 运算符。
Microsoft videos
有关内置 JSON 支持的视觉简介,请参阅以下视频: