机器学习 试验 是所有相关机器学习运行的组织和控制的主要单元。 一次运行对应于模型代码的单次执行。 在 MLflow 中,跟踪基于试验和运行。
机器学习试验允许数据科学家在运行其机器学习代码时记录参数、代码版本、指标和输出文件。 通过试验,还可以可视化、搜索和比较运行,以及下载运行文件和元数据以在其他工具中进行分析。
在本文中,你将了解更多关于数据科学家如何与机器学习试验进行交互并使用这些试验来组织开发过程及跟踪多个运行。
先决条件
- Power BI Premium 订阅。 如果您没有,请参阅如何购买 Power BI Premium。
- 具有分配的高级容量的 Power BI 工作区。
创建试验
可以直接从构造用户界面(UI)或通过编写使用 MLflow API 的代码来创建机器学习试验。
使用 UI 创建试验
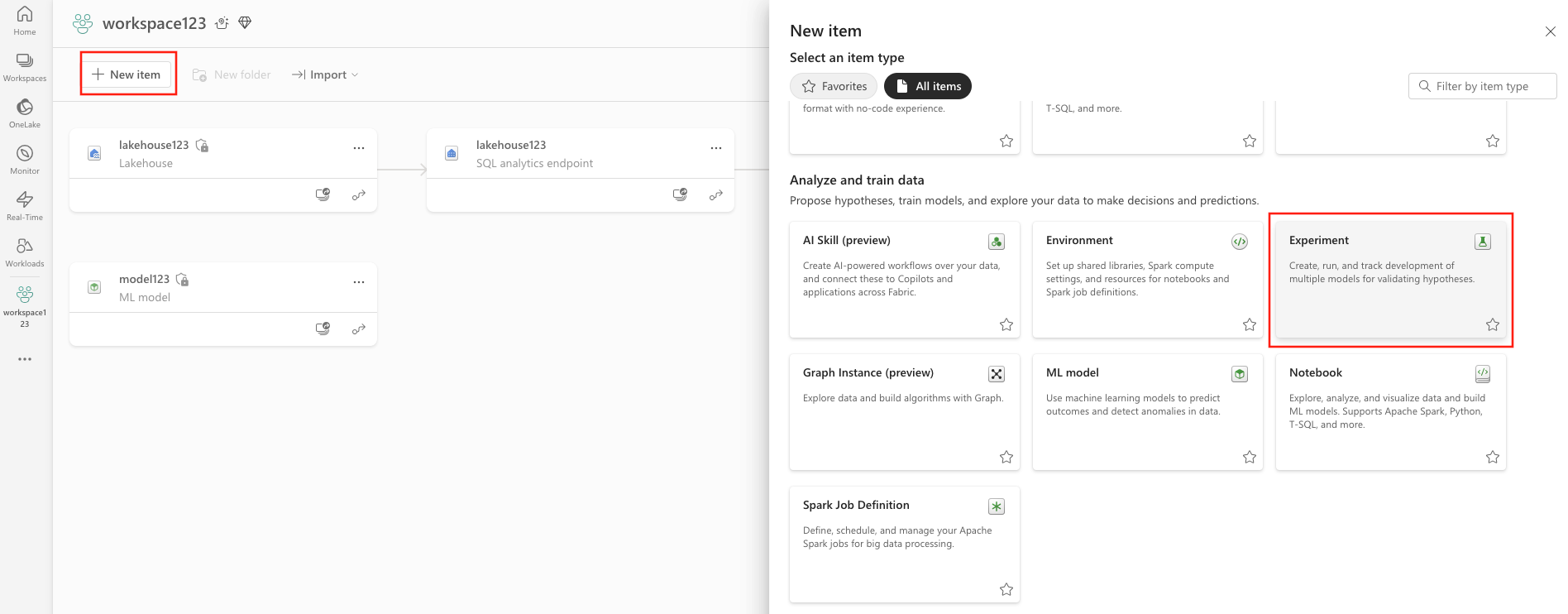
若要从 UI 创建机器学习试验,请执行以下作:
创建新工作区或选择现有工作区。
在工作区左上角,选择“ 新建项”。 在 “分析和训练数据”下,选择“ 试验 ”。
 或
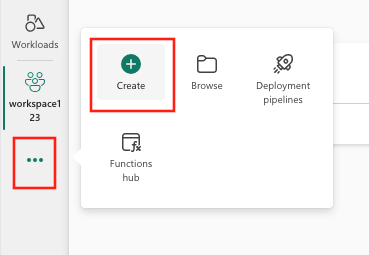
或从垂直菜单中选择“创建”,可在...中找到。
在 “数据科学”下,选择 “试验”。
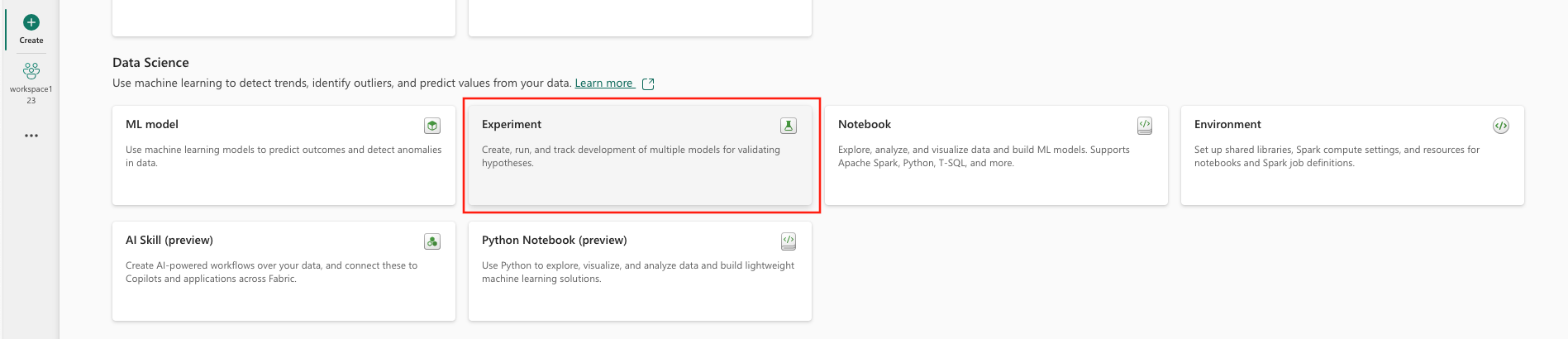
提供试验名称并选择“ 创建”。 此操作会在您的工作区中创建一个空实验。



创建试验后,可以开始添加运行以跟踪运行指标和参数。
使用 MLflow API 创建试验
还可以直接从创作体验中使用 mlflow.create_experiment() 或 mlflow.set_experiment() API 创建机器学习实验。 在以下代码中,将<EXPERIMENT_NAME>替换为您的实验名称。
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
管理实验中的试运行
机器学习实验包含一组实验运行,以便简化跟踪和比较。 在实验中,数据科学家可以在各个运行之间进行导航,探索其基础参数和指标。 数据科学家还可以比较机器学习实验中的运行,以确定哪些参数子集产生所需的模型性能。
若要查看试验的运行,请从试验的视图中选择 “运行”列表 。

从运行列表中,可以通过选择运行名称导航到特定运行的详细信息。
跟踪运行详细信息
机器学习运行对应于模型代码的单个执行。 您可以跟踪每次执行的以下信息:

每个运行都包含以下信息:
- 源:创建运行的笔记本的名称。
- 已注册的版本:指示运行是否保存为机器学习模型。
- 开始日期:运行开始时间。
- 状态:运行进度。
- 超参数:保存为键值对的超参数。 键和值都是字符串。
- 指标:运行保存为键值对的指标。 值为数字。
- 输出文件:以任何格式输出文件。 例如,可以记录图像、环境、模型和数据文件。
- 标记:作为要运行的键值对的元数据。
查看运行列表
可以在 “运行列表 ”视图中查看试验中的所有运行。 此视图允许你跟踪最近的活动,快速跳转到相关的 Spark 应用程序,并根据运行状态应用筛选器。
查看运行列表
可以在 “运行列表 ”视图中查看试验中的所有运行。 此视图允许你跟踪最近的活动,快速跳转到相关的 Spark 应用程序,并根据运行状态应用筛选器。
比较和筛选实例
若要比较和评估机器学习运行的质量,可以比较试验中所选运行之间的参数、指标和元数据。
将标记应用于运行
试验运行的 MLflow 标记允许用户以键值对的形式向其运行添加自定义元数据。 这些标记有助于根据特定属性对运行进行分类、筛选和搜索,从而更轻松地管理和分析 MLflow 平台中的试验。 用户可以利用标记来标记运行,并提供模型类型、参数或任何相关标识符等信息,从而增强试验的整体组织和可跟踪性。
此代码片段启动 MLflow 运行,记录一些参数和指标,并添加标记以对运行进行分类并提供其他上下文。
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
应用标记后,可以直接从嵌入式 MLflow 小组件或运行详情页面查看结果。

警告
警告:在 Fabric 中对 MLflow 实验运行应用标签的限制
- 非空标记:标记名称或值不能为空。 如果尝试应用具有空名称或值的标记,作将失败。
- 标记名称:标记名称长度可达 250 个字符。
- 标记值:标记值长度可达 5000 个字符。
-
受限标记名称:不支持以特定前缀开头的标记名称。 具体而言,以
synapseml、mlflow或trident开头的标记名称受限制,不会被接受。
直观地比较运行
可以在现有试验中直观地比较和筛选运行。 可视化比较使你可以轻松地在多个运行之间导航并对其进行排序。

要比较运行:
- 选择一个包含多个运行的现有机器学习实验。
- 选择“ 视图 ”选项卡,然后转到 “运行列表 ”视图。 或者,也可以从“运行详细信息”视图直接选择“查看运行列表”选项。
- 通过展开“ 自定义列 ”窗格来自定义表中的列。 在这里,可以选择要查看的属性、指标、标记和超参数。
- 展开 “筛选器 ”窗格,根据某些所选条件缩小结果范围。
- 选择多个运行以在指标比较窗格中比较其结果。 在此窗格中,可以通过更改图表标题、可视化效果类型、X 轴、Y 轴等来自定义图表。
使用 MLflow API 比较运行
数据科学家还可以使用 MLflow 在实验中查询和搜索运行。 可以通过访问 MLflow 文档浏览更多 MLflow API 来搜索、筛选和比较运行。
获取所有运行
可以使用 MLflow 搜索 API mlflow.search_runs(),通过在以下代码中用您的试验名称替换 <EXPERIMENT_NAME> 或用您的试验 ID 替换 <EXPERIMENT_ID>,来获取某个试验中的所有运行:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
小窍门
可以通过向experiment_ids参数提供试验 ID 的列表来搜索多个试验。 同样,将实验名称列表提供给experiment_names参数将使MLflow能够跨多个实验进行搜索。 如果想在不同的实验中比较各次运行,这可能会很有帮助。
顺序和限制运行
使用参数max_resultssearch_runs限制返回的运行数。 该 order_by 参数允许列出要排序的列,并且可以包含可选 DESC 或 ASC 值。 例如,以下示例返回试验的最后一次运行。
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
比较 Fabric 笔记本中的实验运行情况
可以在 Fabric 笔记本中使用 MLflow 创作组件来跟踪在每个笔记本单元中生成的 MLflow 运行。 通过小组件,您可以跟踪您的运行、关联的指标、参数和属性,并精确到各个单元格级别。
若要获取视觉比较,还可以切换到 “运行比较 ”视图。 此视图以图形方式呈现数据,有助于快速识别不同运行中的模式或偏差。

将执行结果另存为机器学习模型
运行生成所需结果后,可以通过选择“ 另存为 ML 模型”,将运行另存为模型作为增强型模型进行模型跟踪和模型部署。

监控 ML 实验(预览版)
ML 试验直接集成到 Monitor 中。 此功能旨在更深入地了解 Spark 应用程序和生成的 ML 试验,以便更轻松地管理和调试这些进程。
监测系统中的运行跟踪
用户可以直接从监视器跟踪试验运行,从而提供其所有活动的统一视图。 此集成包括筛选选项,使用户能够专注于过去 30 天或其他指定时间段内创建的试验或运行。

在 Spark 应用程序中跟踪相关的机器学习实验运行
ML 实验直接集成到 Monitor 中,可在其中选择特定的 Spark 应用程序并访问项目快照。 在这里,你将找到该应用程序生成的所有试验和运行的列表。