你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
在 Azure 机器学习中,可以使用自定义容器将模型部署到联机终结点。 自定义容器部署可以使用除 Azure 机器学习使用的默认 Python Flask 服务器以外的 Web 服务器。
使用自定义部署时,可以:
- 使用各种工具和技术,例如 TensorFlow 服务(TF 服务)、TorchServe、Triton Inference Server、Plumber R 包和 Azure 机器学习推理最小映像。
- 仍利用 Azure 机器学习提供的内置监视、缩放、警报和身份验证。
本文介绍如何使用 TF 服务图像来提供 TensorFlow 模型。
Prerequisites
Azure 机器学习工作区。 有关创建工作区的说明,请参阅 “创建工作区”。
Azure CLI 和
ml扩展或 Azure 机器学习 Python SDK v2:若要安装 Azure CLI 和
ml扩展,请参阅安装和设置 CLI(v2)。本文中的示例假定使用 Bash shell 或兼容的 shell。 例如,可以在 Linux 系统或 适用于 Linux 的 Windows 子系统上使用 shell。
包含您的工作区的 Azure 资源组,您或您的服务主体拥有贡献者访问权限。 如果使用 “创建工作区 ”中的步骤配置工作区,则满足此要求。
Docker Engine, installed and running locally. This prerequisite is highly recommended. 在本地部署模型时需要它,这对调试也很有帮助。
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Azure CLI 脚本 | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | 通过扩展 Azure 机器学习 Inference Minimal 映像,将多个模型部署到单个部署。 |
| minimal/single-model | deploy-custom-container-minimal-single-model | 通过扩展 Azure 机器学习推理最小版本的镜像来部署单个模型。 |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | 将两个具有不同 Python 要求的 MLFlow 模型部署到单个终结点后面的两个单独的部署。 使用 Azure 机器学习推理最低限度映像。 |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | 将三个回归模型部署到一个终结点。 使用 Plumber R 包。 |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | 使用 TF 服务自定义容器部署半加二模型。 使用标准模型注册过程。 |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | 使用 TF Serving 自定义容器部署 Half Plus Two (0.5*x + 2) 模型,并将该模型集成到映像中。 |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | 使用 TorchServe 自定义容器部署单个模型。 |
| triton/single-model | deploy-custom-container-triton-single-model | 使用自定义容器部署 Triton 模型。 |
本文介绍如何使用 tfserving/half-plus-two 示例。
Warning
Microsoft支持团队可能无法帮助解决自定义映像导致的问题。 如果遇到问题,系统可能会要求你使用默认映像或Microsoft提供的图像之一来查看问题是否特定于你的映像。
下载源代码
The steps in this article use code samples from the azureml-examples repository. 使用以下命令克隆存储库:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
初始化环境变量
若要使用 TensorFlow 模型,需要多个环境变量。 运行以下命令来定义这些变量:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
下载 TensorFlow 模型
下载并解压缩一个模型,该模型将输入值除以两个,并将两个添加到结果中:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
在本地测试 TF Serving 镜像
使用 Docker 在本地运行映像进行测试:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
向该映像发送活动性和评分请求
发送活性请求以检查容器内的进程是否正在运行。 您应该获得 200 OK 的响应状态码。
curl -v http://localhost:8501/v1/models/$MODEL_NAME
发送评分请求以检查是否可以获取有关未标记数据的预测:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
停止映像
在本地完成测试后,停止映像:
docker stop tfserving-test
将联机终结点部署到 Azure
若要将联机终结点部署到 Azure,请执行以下步骤。
为终结点和部署创建 YAML 文件
可以使用 YAML 配置云部署。 例如,若要配置终结点,可以创建一个名为tfserving-endpoint.yml的 YAML 文件,其中包含以下行:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
若要配置部署,可以创建一个名为tfserving-deployment.yml的 YAML 文件,其中包含以下行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
以下部分讨论了有关 YAML 和 Python 参数的重要概念。
Base image
在 YAML 的 environment 节或 Python 的 Environment 构造函数中,将基础镜像指定为参数。 此示例使用docker.io/tensorflow/serving:latest作为image值。
如果检查容器,可以看到此服务器使用 ENTRYPOINT 命令启动入口点脚本。 该脚本采用环境变量,例如MODEL_BASE_PATH和MODEL_NAME,并公开端口,例如8501。 这些详细信息都与此服务器相关,可以使用此信息来确定如何定义部署。 例如,如果在部署定义中设置 MODEL_BASE_PATH 环境变量, MODEL_NAME 则 TF 服务使用这些值来启动服务器。 同样,如果在部署定义中将每个路由的端口设置为 8501 ,则对这些路由的用户请求将正确路由到 TF Serving 服务器。
此示例基于 TF Serving 案例。 但是,可以使用任何保持运行并能够响应生存性、就绪性和评分路由请求的容器。 若要了解如何形成用于创建容器的 Dockerfile,可以参考其他示例。 某些服务器使用 CMD 指令而不是 ENTRYPOINT 说明。
inference_config 参数
在 environment 节或 Environment 类中, inference_config 是一个参数。 它指定三种类型的路由的端口和路径:活动性、就绪性和评分路由。
inference_config如果要使用托管联机终结点运行自己的容器,则需要此参数。
就绪性路由与活动性路由
某些 API 服务器提供了检查服务器状态的方法。 可以指定两种类型的路由来检查状态:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
在机器学习推理的上下文中,服务器在加载模型之前,可能会对活跃状态请求响应状态代码 200 OK。 只有在将模型加载到内存后,服务器才会响应状态代码 200 OK 的就绪情况请求。
有关实时性和就绪情况探测的详细信息,请参阅 配置实时性、就绪性和启动探测。
选择的 API 服务器确定活动性和就绪性路由。 在本地测试容器时,可以在前面的步骤中标识该服务器。 在本文中,示例部署对实时性和就绪性路由使用相同的路径,因为 TF 服务仅定义一个实时性路由。 有关定义路由的其他方法,请参阅其他示例。
Scoring routes
使用的 API 服务器提供了一种接收并处理有效负载的方法。 在机器学习推理的上下文中,服务器通过特定路由接收输入数据。 在前面的步骤中在本地测试容器时,确定 API 服务器的路由。 定义要创建的部署时,将该路由指定为评分路由。
成功的部署创建也会更新终结点的 scoring_uri 参数。 可以通过运行以下命令来验证此事实: az ml online-endpoint show -n <endpoint-name> --query scoring_uri
定位已装载的模型
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. 装载模型后,无需创建新的 Docker 映像即可部署新版本的模型。 By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
例如,请考虑以下设置:
- 本地计算机上的目录结构为 /azureml-examples/cli/endpoints/online/custom-container
-
half_plus_two的模型名称
假设tfserving-deployment.yml文件在其model部分中包含以下行。 在本部分中,该值 name 指用于在 Azure 机器学习中注册模型的名称。
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
在这种情况下,创建部署时,模型位于以下文件夹下:/var/azureml-app/azureml-models/tfserving-mounted/1。
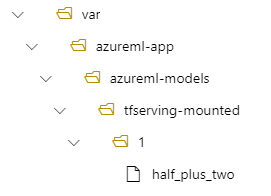
可以选择配置 model_mount_path 值。 通过调整此设置,可以更改模型装载的路径。
Important
该值 model_mount_path 必须是 Linux 中有效的绝对路径(在容器映像的来宾 OS 中)。
Important
model_mount_path 仅在 BYOC(自带容器)方案中可用。 在 BYOC 方案中,联机部署使用的环境必须 inference_config 配置参数 。 可以使用 Azure ML CLI 或 Python SDK 在创建环境时指定 inference_config 参数。 Studio UI 当前不支持指定此参数。
更改值 model_mount_path时,还需要更新 MODEL_BASE_PATH 环境变量。 将 MODEL_BASE_PATH 设置为与 model_mount_path 相同的值,以避免因找不到基本路径而导致部署失败。
例如,您可以将model_mount_path参数添加到您的tfserving-deployment.yml文件中。 还可以更新 MODEL_BASE_PATH 该文件中的值:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
那么,在部署中,模型将位于部署中的 /var/tfserving-model-mount/tfserving-mounted/1。 它不再位于 azureml-app/azureml-models 下,而是位于指定的装载路径下:
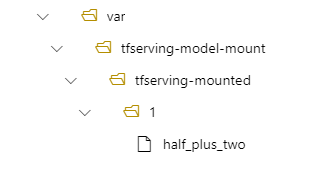
创建终结点和部署
构造 YAML 文件后,使用以下命令创建终结点:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
使用以下命令来创建你的部署。 此步骤可能会运行几分钟。
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
调用终结点
部署完成后,向部署的终结点发出评分请求。
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
删除终结点
如果不再需要终结点,请运行以下命令将其删除:
az ml online-endpoint delete --name tfserving-endpoint