如果你有一个没有多少 I/O 的慢阶段,原因可能是:
- 读取大量小文件
- 编写大量小文件
- 缓慢的 UDF
- 笛卡尔联接
- 分解联接
几乎可以使用 SQL DAG 识别所有这些问题。
打开 SQL DAG
若要打开 SQL DAG,请向上滚动到作业页面顶部,然后单击 关联的 SQL 查询:
现在应该会看到 DAG。 如果没有,稍微滚动一下,你就能看到它。
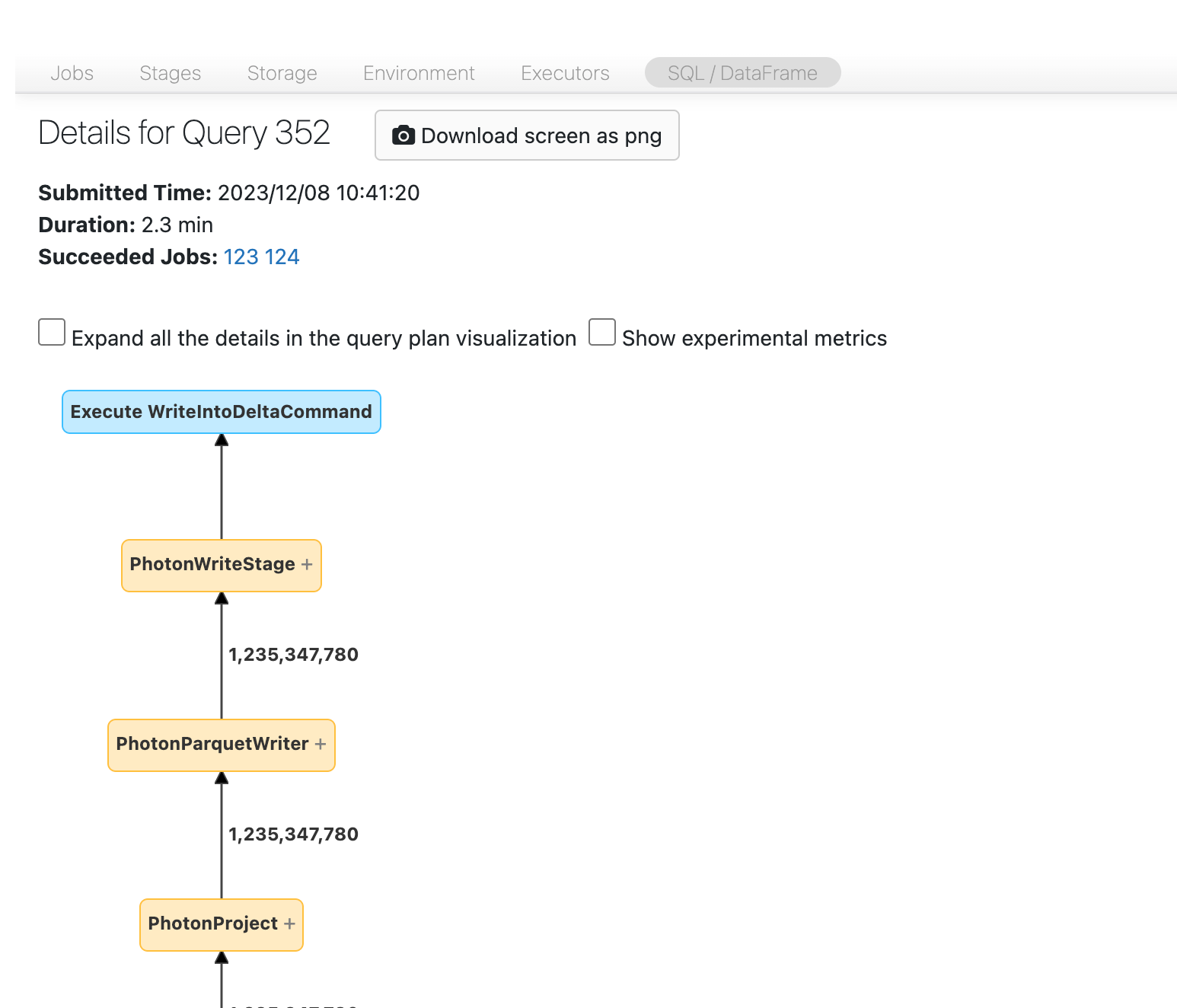
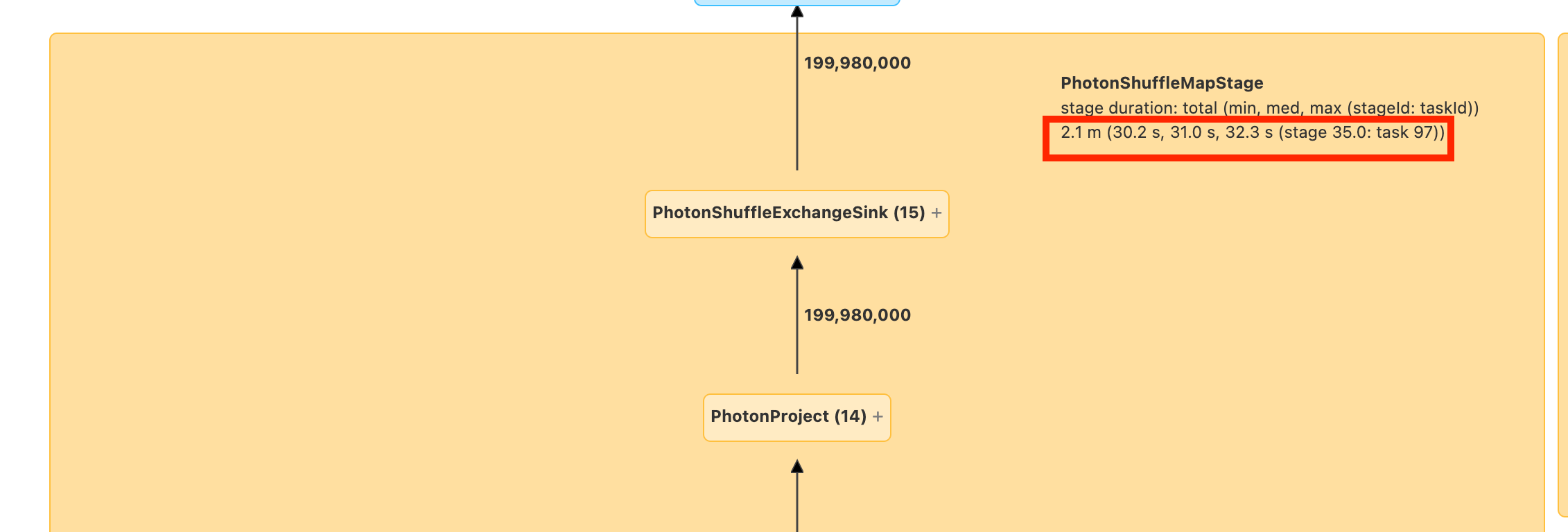
在继续操作之前,你需要熟悉 DAG 以及花费时间的位置。 DAG 中的某些节点具有有用的时间信息,而其他节点则没有。 例如,此块花费了 2.1 分钟,甚至提供阶段 ID:
此节点需要打开它才能看到它花费了 1.4 分钟:
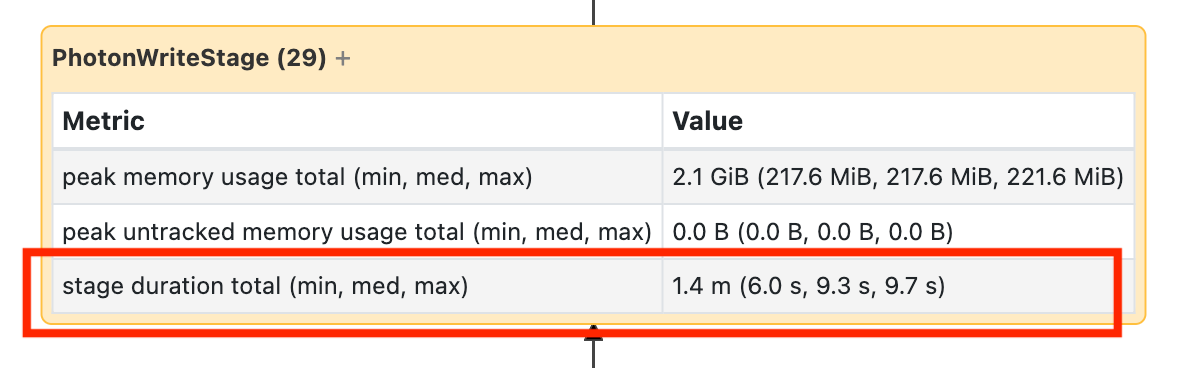
这些时间是累积的,因此它是所有任务花费的总时间,而不是时钟时间。 但它仍然非常有用,因为它们与时钟时间和成本相关。
了解在 DAG 的哪个部分花费了时间是有帮助的。
读取大量小文件
如果发现某个扫描操作耗费了大量时间,请打开查看读取文件数:
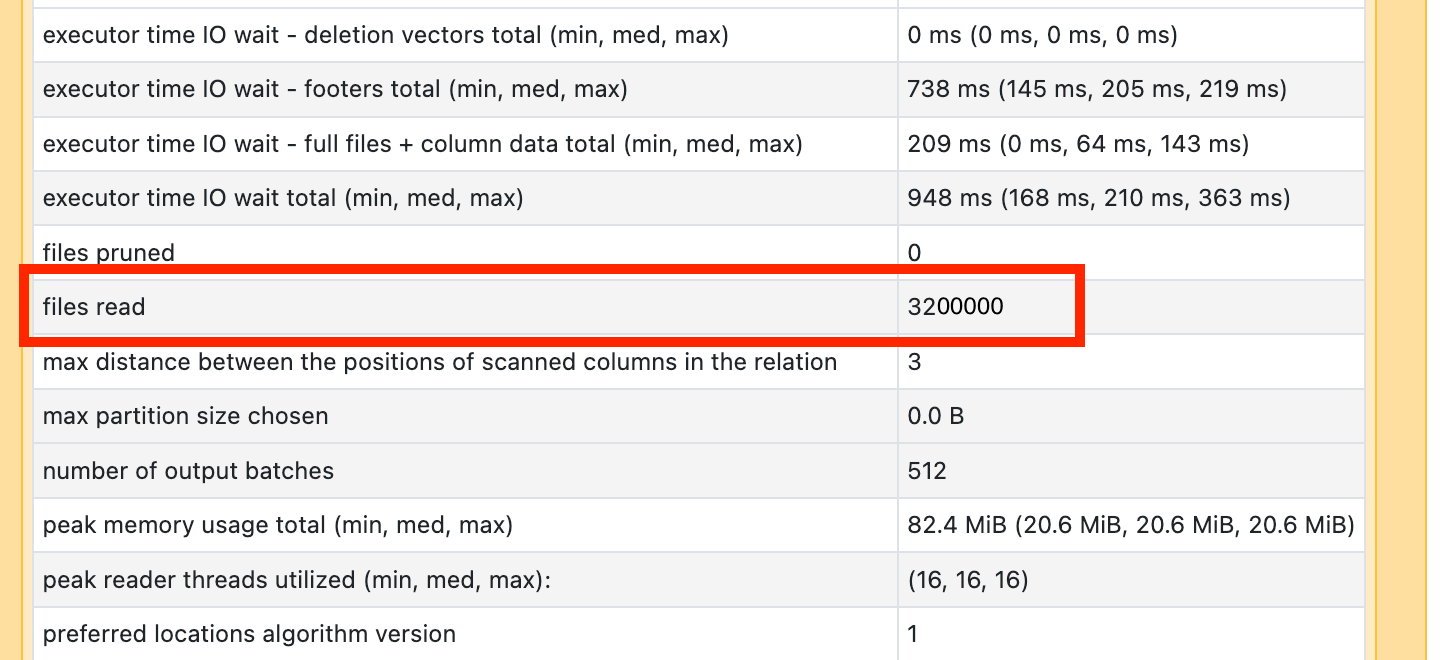
如果要读取数万个文件或更多文件,则可能有一个小文件问题。 文件不应小于 8MB。 小文件问题通常是通过对过多列或高基数列进行分区引起的。
如果你很幸运,你可能只需要运行 OPTIMIZE。 Databricks 建议还启用 预测优化 并重新考虑 文件布局。
编写大量小文件
如果看到写入需要很长时间,请打开它并查找文件数以及写入的数据量:
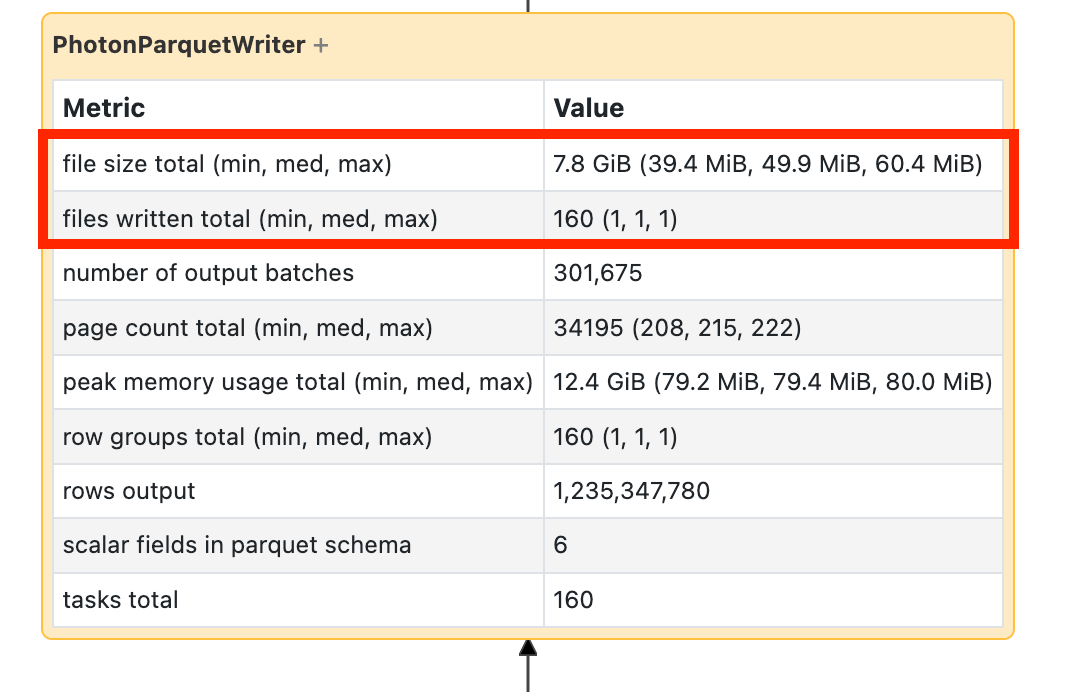
如果要编写数万个文件或更多文件,则可能有一个小文件问题。 文件不应小于 8MB。 小文件问题通常是通过对过多列或高基数列进行分区引起的。 需要启用 预测优化、重新考虑 文件布局或打开 优化的写入。
UDF 缓慢
如果你知道你有 UDF,或者在 DAG 中看到类似这样的内容,则可能拥有缓慢的 UDF:
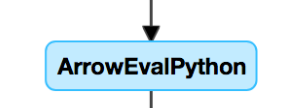
如果你认为你遭遇此问题,请尝试注释掉用户定义函数 (UDF),以查看它对管道速度的影响。 如果 UDF 确实是耗费时间的地方,最佳选择是使用原生函数重写 UDF。 如果无法进行,请考虑执行 UDF 的阶段所涉及的任务数量。 如果它小于群集上的内核数,repartition() 数据帧,然后再使用 UDF。
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDF 也可能因内存问题而受到影响。 请考虑每个任务可能需要将分区中的所有数据加载到内存中。 如果此数据太大,则情况可能会变得非常缓慢或不稳定。 重新分区还可以通过缩小每个任务来解决此问题。
笛卡尔联接
如果在 DAG 中看到笛卡尔联接或嵌套循环联接,则应知道这些联接非常昂贵。 确保这是你打算的,看看是否有另一种方法。
分解联接或分解
如果进入节点的行数很少,而流出的行数却很多,则可能是连接或 explode() 出现了问题:

阅读 Databricks 优化指南中有关爆炸的详细信息。