本文介绍如何在模型服务终结点上配置 Mosaic AI 网关。
Requirements
- 支持模型服务的区域中的 Databricks 工作区。 请参阅 提供区域可用性的模型。
- 一个模型服务终结点。 可以在工作区上使用一个预配置的按令牌付费终结点,或者执行以下操作:
- 若要为外部模型创建终结点,请完成 创建提供终结点的外部模型的步骤 1 和 2。
- 若要创建预配吞吐量的终结点,请参阅 预配吞吐量基础模型 API。
- 若要为自定义模型创建终结点,请参阅 “创建终结点”。
使用 UI 配置 AI 网关
在终结点创建页的 AI 网关 部分中,可以单独配置 AI 网关功能。 请参阅 支持的功能,了解哪些功能可用于外部模型服务端点和预配吞吐量端点。
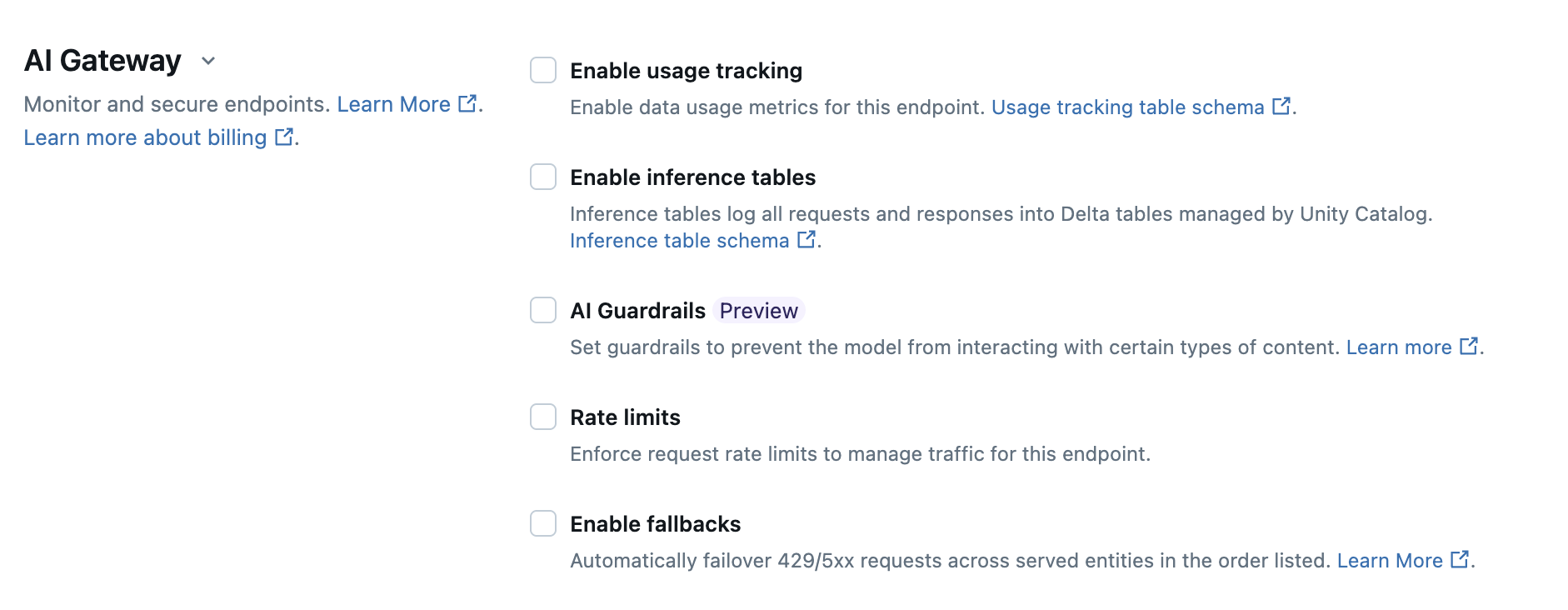
下表总结了如何使用服务 UI 在终结点创建过程中配置 AI 网关。 如果首选以编程方式执行此操作,请参阅笔记本示例。
| Feature | 如何启用 | Details |
|---|---|---|
| Usage tracking | 选择启用使用情况跟踪,以启用数据使用情况指标的跟踪和监视。 默认情况下,此功能为 按令牌付费 端点启用。 |
|
| Payload logging | 选择启用推理表,以自动将来自终结点的请求和响应记录到 Unity Catalog 管理的 Delta 表中。 |
|
| AI Guardrails | 请参阅在 UI 中配置 AI 护栏。 |
|
| Rate limits | 选择 速率限制 以管理和指定终结点可以接收的每个分钟(QPM)的查询数,包括整体查询和每个用户。 速率限制仅适用于有权查询终结点的用户。 可以在不同级别定义速率限制。
可以指定以下自定义速率限制:
|
|
| Traffic splitting | 在 “服务实体 ”部分中,指定要路由到特定模型的 流量百分比 。 若要以编程方式在终结点上配置流量拆分,请参阅 向终结点提供多个外部模型。 |
|
| Fallbacks | 选择“AI 网关”部分中的 “启用回退 ”,将请求作为回退发送到终结点上的其他服务模型。 |
|
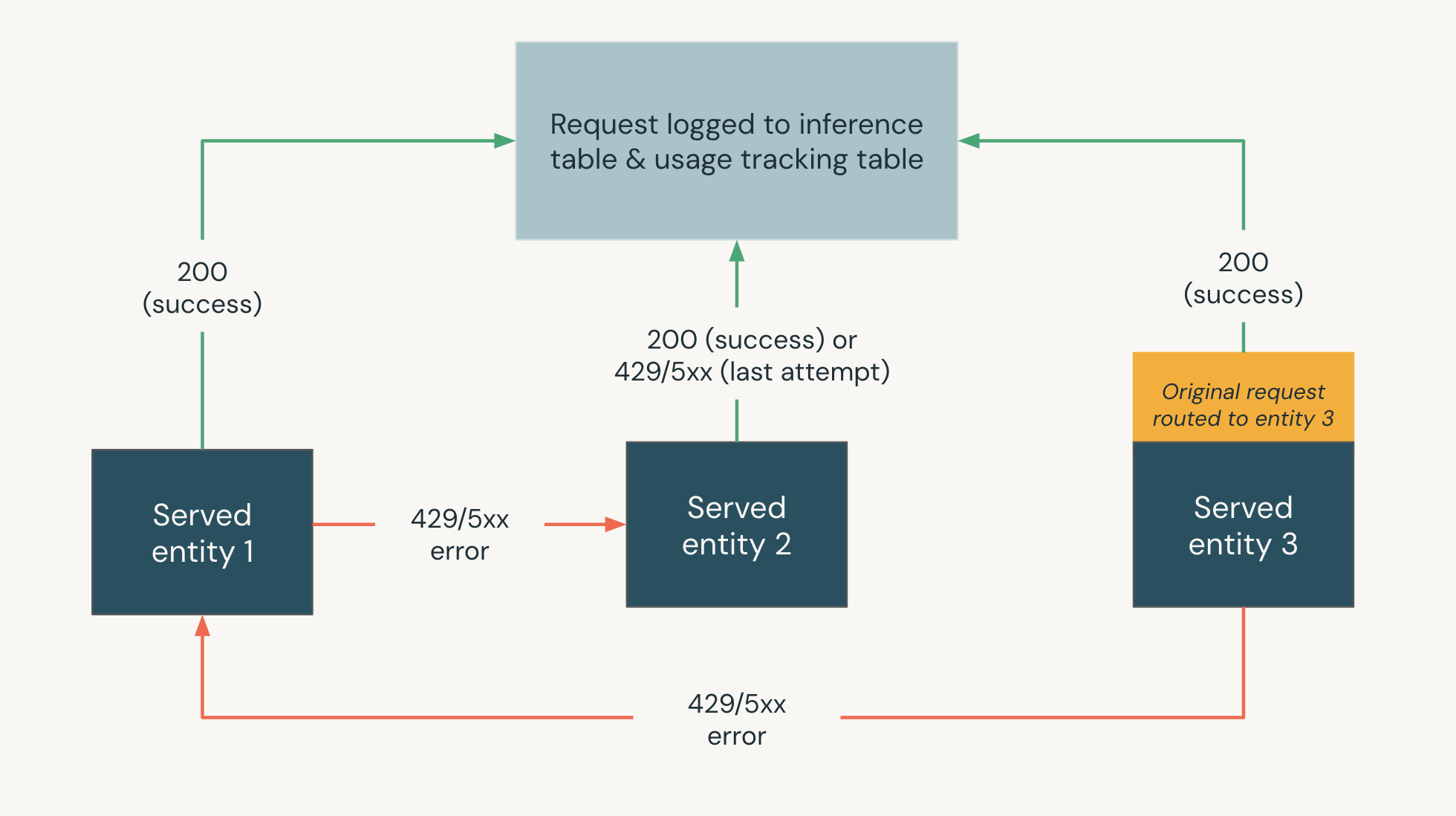
下图显示了一个后备方案示例,其中,
- 在模型服务终结点上提供三个服务实体。
- 请求最初路由到 服务实体 3。
- 如果请求返回 200 响应,则请求在 服务实体 3 上成功,请求及其响应将记录到终结点的使用情况跟踪和有效负载日志记录表。
- 如果请求在 服务实体 3 上返回 429 或 5xx 错误,则请求会回退到终结点上的下一个服务实体 ,即“已处理”实体 1。
- 如果请求在 服务实体 1 上返回 429 或 5xx 错误,则请求会回退到终结点上的下一个服务实体 ,即“已处理”实体 2。
- 如果请求在 服务实体 2 上返回 429 或 5xx 错误,则请求会失败,因为这是回退实体的最大数目。 失败的请求和响应错误将记录到使用情况跟踪和有效负载日志记录表。
在 UI 中配置 AI 护栏
Important
此功能目前以公共预览版提供。
下表显示了如何配置支持的护栏。
Note
2025 年 5 月 30 日之后,不再支持主题审查和关键字筛选 AI 防护措施。 如果工作流需要这些功能,请联系 Databricks 帐户团队,参与自定义防护栏个人预览版。
| Guardrail | 如何启用 |
|---|---|
| Safety | 选择安全以启用安全措施,防止模型与不安全且有害的内容进行交互。 |
| 个人身份信息 (PII) 检测 | 如果终结点请求和响应中检测到此类信息,请选择 “阻止 ”或 “屏蔽 PII 数据”(例如姓名、地址、信用卡号)。 否则,请选择 “无” ,不进行 PII 检测。 |

使用情况跟踪表架构
以下部分概述了用于system.serving.served_entities和system.serving.endpoint_usage系统表的使用情况跟踪表的架构。
system.serving.served_entities 使用情况跟踪表架构
Note
system.serving.served_entities 使用情况跟踪系统表目前不支持用于按令牌付费的终结点。
system.serving.served_entities 使用情况跟踪系统表采用以下架构:
| Column name | Description | 类型 |
|---|---|---|
served_entity_id |
所服务实体的唯一 ID。 | STRING |
account_id |
Delta Sharing 的客户帐户 ID。 | STRING |
workspace_id |
服务终结点的客户工作区 ID。 | STRING |
created_by |
创建者的 ID。 | STRING |
endpoint_name |
服务终结点的名称。 | STRING |
endpoint_id |
服务终结点的唯一 ID。 | STRING |
served_entity_name |
所服务实体的名称。 | STRING |
entity_type |
所服务实体的类型。 可以是 FEATURE_SPEC、EXTERNAL_MODEL、FOUNDATION_MODEL 或 CUSTOM_MODEL |
STRING |
entity_name |
实体的基础名称。 与用户提供的名称 served_entity_name 不同。 例如,entity_name 是 Unity Catalog 模型的名称。 |
STRING |
entity_version |
服务实体的版本。 | STRING |
endpoint_config_version |
终结点配置的版本。 | INT |
task |
任务类型。 可以是 llm/v1/chat、llm/v1/completions 或 llm/v1/embeddings。 |
STRING |
external_model_config |
外部模型的配置。 例如: {Provider: OpenAI} |
STRUCT |
foundation_model_config |
基础模型的配置。 例如 {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
自定义模型的配置。 例如 { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
功能规范的配置。 例如: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
服务实体的更改时间戳。 | TIMESTAMP |
endpoint_delete_time |
实体删除操作的时间戳。 终结点是所服务实体的容器。 删除终结点后,还会删除所服务实体。 | TIMESTAMP |
system.serving.endpoint_usage 使用情况跟踪表架构
system.serving.endpoint_usage 使用情况跟踪系统表采用以下架构:
| Column name | Description | 类型 |
|---|---|---|
account_id |
客户帐户 ID。 | STRING |
workspace_id |
服务终结点的客户工作区 ID。 | STRING |
client_request_id |
可在模型服务请求正文中指定的用户提供的请求标识符。 对于自定义模型终结点,对于大于 4MiB 的请求,不支持这样做。 | STRING |
databricks_request_id |
附加到所有模型服务请求的 Azure Databricks 生成的请求标识符。 | STRING |
requester |
对服务终结点的调用请求使用其权限的用户或服务主体的 ID。 | STRING |
status_code |
从模型返回的 HTTP 状态代码。 | INTEGER |
request_time |
接收请求的时间戳。 | TIMESTAMP |
input_token_count |
输入的标记计数。 对于自定义模型请求,这为 0。 | LONG |
output_token_count |
输出的标记计数。 对于自定义模型请求,这为 0。 | LONG |
input_character_count |
输入字符串或提示的字符计数。 对于自定义模型请求,这为 0。 | LONG |
output_character_count |
响应输出字符串的字符计数。 对于自定义模型请求,这为 0。 | LONG |
usage_context |
用户提供的映射,包含对终结点发出调用的最终用户或客户应用程序的标识符。 请参阅使用 usage_context 进一步定义用法。 对于自定义模型终结点,对于大于 4MiB 的请求,不支持这样做。 |
MAP |
request_streaming |
请求是否处于流模式。 | BOOLEAN |
served_entity_id |
唯一 ID,用于与 system.serving.served_entities 维度表联接,以查找有关终结点和服务实体的信息。 |
STRING |
使用 usage_context 进一步定义使用情况
在启用使用情况跟踪的情况下查询外部模型时,可以提供类型 usage_context 的 Map[String, String] 参数。 用法上下文映射显示在 usage_context 列的使用情况跟踪表中。
usage_context 映射大小不能超过 10 KiB。
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
如果您使用 OpenAI Python 客户端,可以通过在usage_context参数中包含extra_body来指定它。
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
帐户管理员可以根据用法上下文汇总不同的行,以获得见解,并且可以将此信息与有效负载日志记录表中的信息进行联接。 例如,可以将 end_user_to_charge 添加到 usage_context,以跟踪最终用户的成本归因。
监视终端使用情况
若要监视终结点使用情况,可以联接终结点的系统表和推理表。
联接系统表
此示例仅适用于外部模型和预配的吞吐量终结点。
served_entities 系统表对于按令牌付费的终结点不受支持,但你可以联接推理表和使用情况表来获取类似的详细信息。
若要联接 endpoint_usage 表和 served_entities 系统表,请使用以下 SQL:
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
联接推理和使用情况表
下文将联接 endpoint_usage 系统表和推理表,用于按令牌付费的终端点。 必须在终结点上启用推理表和使用情况跟踪以联接这些表。
SELECT * FROM system.serving.endpoint_usage AS endpoint_usage
JOIN
(SELECT DISTINCT(served_entity_id) AS fmapi_served_entity_id
FROM <inference table name>) fmapi_id
ON fmapi_id.fmapi_served_entity_id = endpoint_usage.served_entity_id;
在终结点上更新 AI 网关功能
可以在以前启用 AI 网关功能和未启用该功能的模型服务终结点上更新 AI 网关功能。 应用 AI 网关配置更新大约需要 20-40 秒,但速率限制更新最长可能需要 60 秒。
下面演示了如何使用服务 UI 在模型服务终结点上更新 AI 网关功能。
在终结点页面的网关部分中,可以看到已启用的功能。 若要更新这些功能,请单击编辑 AI 网关。

笔记本示例
以下笔记本演示了如何以编程方式启用和使用 Databricks Mosaic AI 网关功能,以便管理和治理来自提供程序的模型。 有关 REST API 的详细信息,请参阅 PUT /api/2.0/service-endpoints/{name}/ai-gateway 。