Создавайте эмбеддинги с расширением Azure AI
Чтобы выполнить семантический поиск, необходимо сравнить вектор запроса с векторами искомых элементов. Расширение azure_ai для базы данных Azure для PostgreSQL — Гибкий сервер интегрируется с Azure OpenAI для создания векторов эмбеддинга.
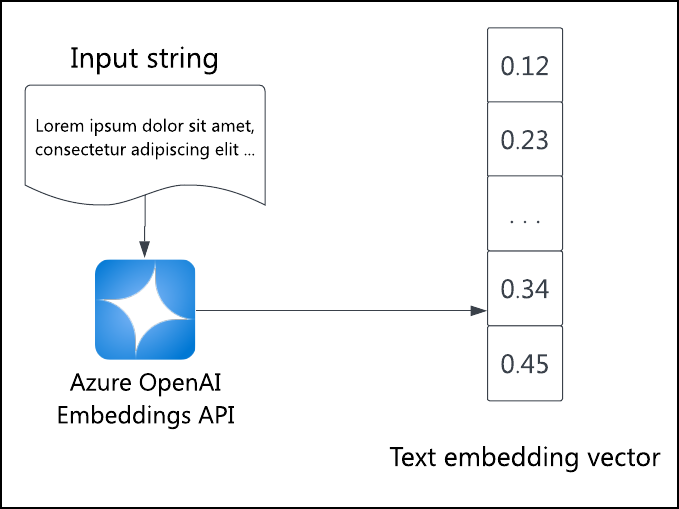
Введение в azure_ai и Azure OpenAI
Гибкое расширение Базы данных Azure для PostgreSQL для Azure AI предоставляет определяемые пользователем функции для интеграции со службами ИИ Azure, включая Azure OpenAI и Azure Cognitive Services.
API встраивания Azure OpenAI создает вектор встраивания для входного текста. Используйте этот API для установки встраиваний для всех элементов, которые будут подвергнуты поиску.
azure_ai Схема расширения azure_openai упрощает вызов API из SQL для создания встраиваний, будь то инициализация встраивания элементов или создание внедряемого на лету запроса. Затем эти внедрения можно использовать для выполнения поиска сходства векторов или, другими словами, семантического поиска.
azure_ai Использование расширения с Azure OpenAI
Чтобы вызвать API Внедрения Azure OpenAI из PostgreSQL, необходимо включить и настроить azure_ai расширение, предоставить доступ к Azure OpenAI и развернуть модель Azure OpenAI. Дополнительные сведения см. в документации по Azure OpenAI на Гибком сервере Базы данных Azure для PostgreSQL.
Как только среда будет готова, и расширение будет внесено в список разрешенных, запустите этот SQL:
/* Enable the extension. */
CREATE EXTENSION azure_ai;
Кроме того, необходимо настроить конечную точку ресурса службы OpenAI и ключ доступа:
SELECT azure_ai.set_setting('azure_openai.endpoint', '{your-endpoint-url}');
SELECT azure_ai.set_setting('azure_openai.subscription_key', '{your-api-key}}');
Как только azure_ai и Azure OpenAI будут настроены, получение и хранение встраиваний — это простой вопрос вызова функции в SQL-запросе. Предположим, существует таблица listings с двумя столбцами: description и listing_vector. Вы можете создать и сохранить векторное представление для всех записей с помощью следующего запроса. Замените {your-deployment-name} на имя развертывания из Azure OpenAI Studio для созданной вами модели.
UPDATE listings
SET listing_vector = azure_openai.create_embeddings('{your-deployment-name}', description, max_attempts => 5, retry_delay_ms => 500)
WHERE listing_vector IS NULL;
Столбец вектора listing_vector должен иметь то же количество измерений, что и языковая модель.
Чтобы просмотреть внедрение документа, выполните следующий запрос:
SELECT listing_vector FROM listings LIMIT 1;
Результатом является вектор чисел с плавающей запятой. Сначала можно запустить \x , чтобы сделать выходные данные более читаемыми.
Создание запроса, встраиваемого динамически
Как только у вас будут эмбеддинги для документов, которые вы хотите найти, можно запустить семантический поисковый запрос. Для этого также необходимо создать эмбеддинг для текста запроса.
Схема azure_openai расширения azure_ai позволяет создавать эмбеддинги в SQL. Например, чтобы найти три первых объявления, текст которых наиболее семантически похож на запрос "Найти места в районе, где можно ходить пешком," выполните следующий SQL:
SELECT id, description FROM listings
ORDER BY listing_vector <=> azure_openai.create_embeddings('{your-deployment-name}', 'Find me places in a walkable neighborhood.')::vector
LIMIT 3;
Оператор <=> вычисляет расстояние косинуса между двумя векторами, семантической метрикой сходства. Чем ближе векторы, тем более семантически похожи; чем дальше векторы, тем семантически отличаются.
Оператор ::vector преобразует созданные внедрения в массивы векторов PostgreSQL.
Запрос возвращает три первых идентификатора записей и их описания, ранжированные от наименее до наиболее различающихся (наиболее до наименее похожих).