Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Агенты ИИ преобразуют способ взаимодействия приложений с данными путем объединения больших языковых моделей (LLM) с внешними инструментами и базами данных. Агенты обеспечивают автоматизацию сложных рабочих процессов, повышают точность получения информации и упрощают интерфейсы естественного языка к базам данных.
В этой статье рассматривается создание интеллектуальных агентов ИИ, которые могут выполнять поиск и анализ данных в Базе данных Azure для PostgreSQL. В нем рассматривается настройка, реализация и тестирование с помощью помощника по юридическим исследованиям в качестве примера.
Что такое агенты ИИ?
Агенты ИИ выходят за рамки простых чат-ботов, сочетая LLM с внешними инструментами и базами данных. В отличие от автономных больших языковых моделей (LLM) или стандартных систем генерации с расширением поиска (RAG), агенты ИИ могут:
- План. Разбиите сложные задачи на более мелкие, последовательные шаги.
- Используйте средства: используйте API, выполнение кода и системы поиска для сбора информации или выполнения действий.
- Восприятие. Понимание и обработка входных данных из различных источников данных.
- Помните: Хранение и воспроизведение предыдущих взаимодействий для более грамотного принятия решений.
Подключив агенты ИИ к базам данных, таким как Azure Database для PostgreSQL, агенты могут предоставлять более точные ответы, учитывающие контекст, на основе ваших данных. Агенты ИИ выходят за рамки простого человеческого диалога для выполнения задач на основе естественного языка. Эти задачи традиционно требуют закодированную логику. Однако агенты могут планировать задачи, необходимые для выполнения на основе предоставленного пользователем контекста.
Внедрение агентов ИИ
Реализация агентов ИИ с помощью Базы данных Azure для PostgreSQL включает интеграцию расширенных возможностей ИИ с надежными функциями баз данных для создания интеллектуальных и контекстно-зависимой систем. С помощью таких средств, как векторный поиск, внедрение и служба агента Azure AI Foundry, разработчики могут создавать агенты, которые понимают запросы естественного языка, извлекают соответствующие данные и предоставляют полезные аналитические сведения.
В следующих разделах описан пошаговый процесс настройки, настройки и развертывания агентов ИИ. Этот процесс обеспечивает простое взаимодействие между моделями ИИ и базой данных PostgreSQL.
Платформы
Различные платформы и средства могут упростить разработку и развертывание агентов ИИ. Все эти платформы поддерживают использование Базы данных Azure для PostgreSQL в качестве средства:
- Служба агента Azure AI Foundry
- LangChain/LangGraph
- LlamaIndex
- Семантическое ядро
- AutoGen
- API помощников OpenAI
Пример реализации
В этом примере используется служба агента Azure AI Foundry для планирования агентов, использования инструментов и восприятия. Она использует Базу данных Azure для PostgreSQL в качестве средства для векторной базы данных и возможностей семантического поиска.
В следующих разделах описано, как создать агент ИИ, который помогает юридическим командам исследовать соответствующие случаи для поддержки своих клиентов в штате Вашингтон. Агент:
- Обрабатывает запросы на естественном языке о юридических ситуациях.
- Использует векторный поиск в Базе данных Azure для PostgreSQL, чтобы найти соответствующие прецеденты случаев.
- Анализирует и суммирует выводы в полезном формате для юридических специалистов.
Предпосылки
Включите и настройте
azure_aipg_vectorрасширения.Развертывание моделей
gpt-4o-miniиtext-embedding-small.Установите Visual Studio Code.
Установите расширение Python .
Установите Python 3.11.x.
Установите Azure CLI (последняя версия).
Замечание
Вам потребуется ключ и конечная точка из развернутых моделей, созданных для агента.
Начало работы
Все код и примеры наборов данных доступны в этом репозитории GitHub.
Шаг 1. Настройка векторного поиска в Базе данных Azure для PostgreSQL
Во-первых, подготовьте базу данных для хранения и поиска данных по юридическим делам с помощью векторных представлений.
Настройка среды
Если вы используете macOS и Bash, выполните следующие команды:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Если вы используете Windows и PowerShell, выполните следующие команды:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Если вы используете Windows и cmd.exeвыполните следующие команды:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Настройка переменных среды
.env Создайте файл с учетными данными:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Загрузка документов и векторов
Файл Python load_data/main.py служит центральной точкой входа для загрузки данных в базу данных Azure для PostgreSQL. Код обрабатывает данные для примеров случаев, включая сведения о случаях в Вашингтоне.
Файл main.py:
- Создает необходимые расширения, настраивает параметры API OpenAI и управляет таблицами баз данных, сбрасывая существующие и создавая новые для хранения данных регистра.
- Считывает данные из CSV-файла и вставляет их во временную таблицу, после чего обрабатывает и переносит в основную таблицу дела.
- Добавляет новый столбец для эмбеддингов в таблицу дел и создает эмбеддинги для мнений по делам с помощью API OpenAI. Он сохраняет внедрения в новом столбце. Процесс внедрения занимает около 3–5 минут.
Чтобы запустить процесс загрузки данных, выполните следующую команду из load_data каталога:
python main.py
Ниже приведены выходные данные main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Шаг 2. Создание средства Postgres для агента
Затем настройте средства агента ИИ для получения данных из Postgres. Затем используйте пакет SDK службы агента Azure AI Foundry для подключения агента ИИ к базе данных Postgres.
Определение функции для вызова агента
Начните с определения функции для вызова агента, описывая ее структуру и все необходимые параметры в документации. Включите все определения функций в один файл , legal_agent_tools.py. Затем вы можете импортировать файл в основной скрипт.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Шаг 3. Создание и настройка агента ИИ с помощью Postgres
Теперь настройте агент ИИ и интегрируйте его с инструментом Postgres. Файл Python src/simple_postgres_and_ai_agent.py служит центральной точкой входа для создания и использования агента.
Файл simple_postgres_and_ai_agent.py:
- Инициализирует агент в вашем проекте Azure AI Foundry с использованием определенной модели.
- Добавляет средство Postgres для векторного поиска в базе данных во время инициализации агента.
- Настраивает поток связи. Этот поток используется для отправки сообщений агенту для обработки.
- Обрабатывает запрос пользователя с помощью агента и средств. Агент может планировать получение правильного ответа с помощью инструментов. В этом случае агент вызывает средство Postgres на основе подписи функции и документации, чтобы выполнить векторный поиск и получить соответствующие данные для ответа на этот вопрос.
- Отображает ответ агента на запрос пользователя.
Поиск строки подключения проекта в Azure AI Foundry
В проекте Azure AI Foundry вы найдете строку подключения проекта на странице обзора проекта. Эта строка используется для подключения проекта к пакету SDK службы агента Azure AI Foundry. Добавьте эту строку в .env файл.
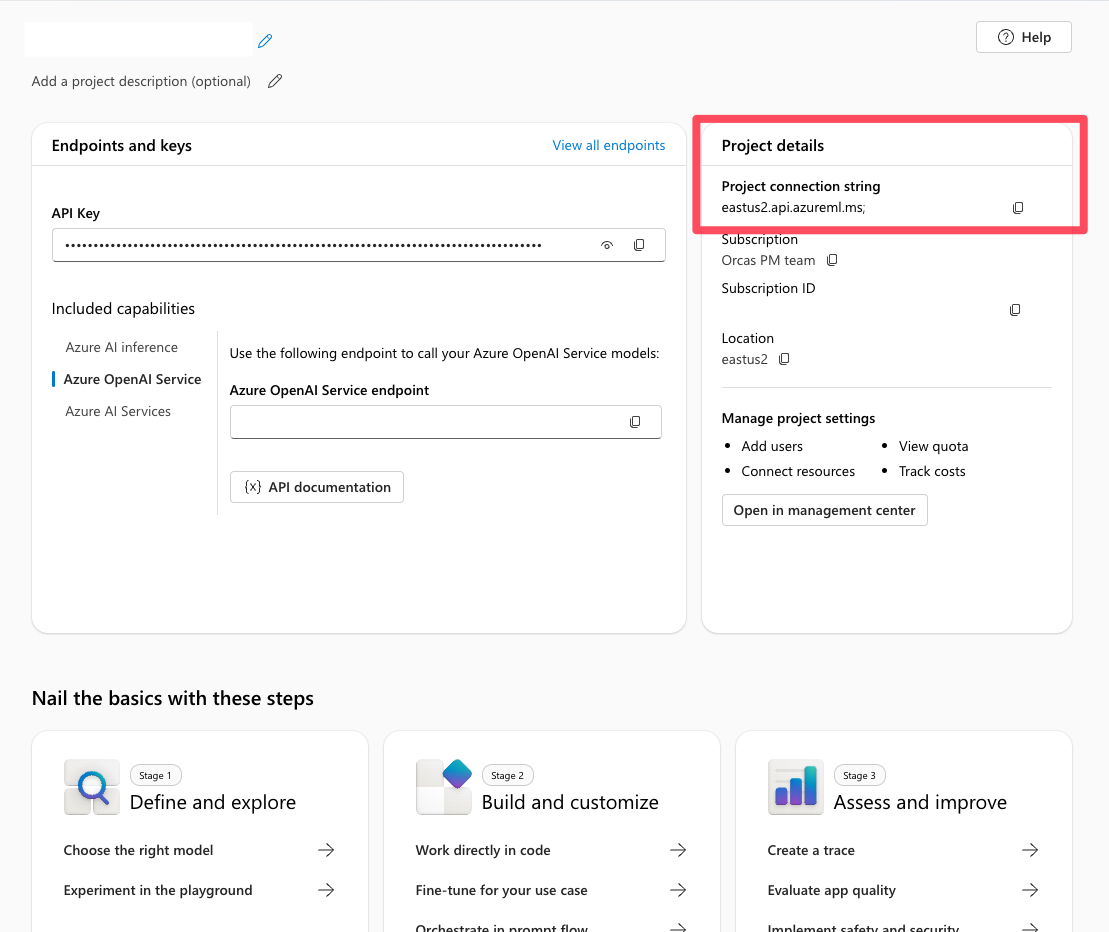
Настройка подключения
Добавьте эти переменные в .env файл в корневом каталоге:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Azure AI Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/src/simple_postgres_and_ai_agent.py).
# Create an Azure AI Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Создание потока связи
В этом фрагменте кода показано, как создать поток агента и сообщение, которое агент обрабатывает в процессе выполнения.
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Обработка запроса
В следующем фрагменте кода создается запуск агента для обработки сообщения и использования соответствующих средств для обеспечения наилучшего результата.
Используя инструменты, агент может вызвать Postgres и выполнить векторный поиск по запросу "Утечка воды в квартиру с верхнего этажа", чтобы получить данные, необходимые для наиболее точного ответа на вопрос.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Запустите агента
Чтобы запустить агент, выполните следующую команду из src каталога:
python simple_postgres_and_ai_agent.py
Агент получает аналогичный результат с помощью средства Azure Database для PostgreSQL для получения доступа к данным дела, сохраненным в базе данных Postgres.
Ниже приведен фрагмент выходных данных агента:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
Шаг 4. Тестирование и отладка с помощью игровой площадки агента
После запуска агента с помощью пакета SDK службы агента Azure AI Foundry агент хранится в проекте. Вы можете поэкспериментировать с агентом на игровой площадке агента:
В Azure AI Foundry перейдите в раздел "Агенты ".
Найдите агента в списке и выберите его для открытия.
Используйте интерфейс детской площадки для тестирования различных юридических запросов.
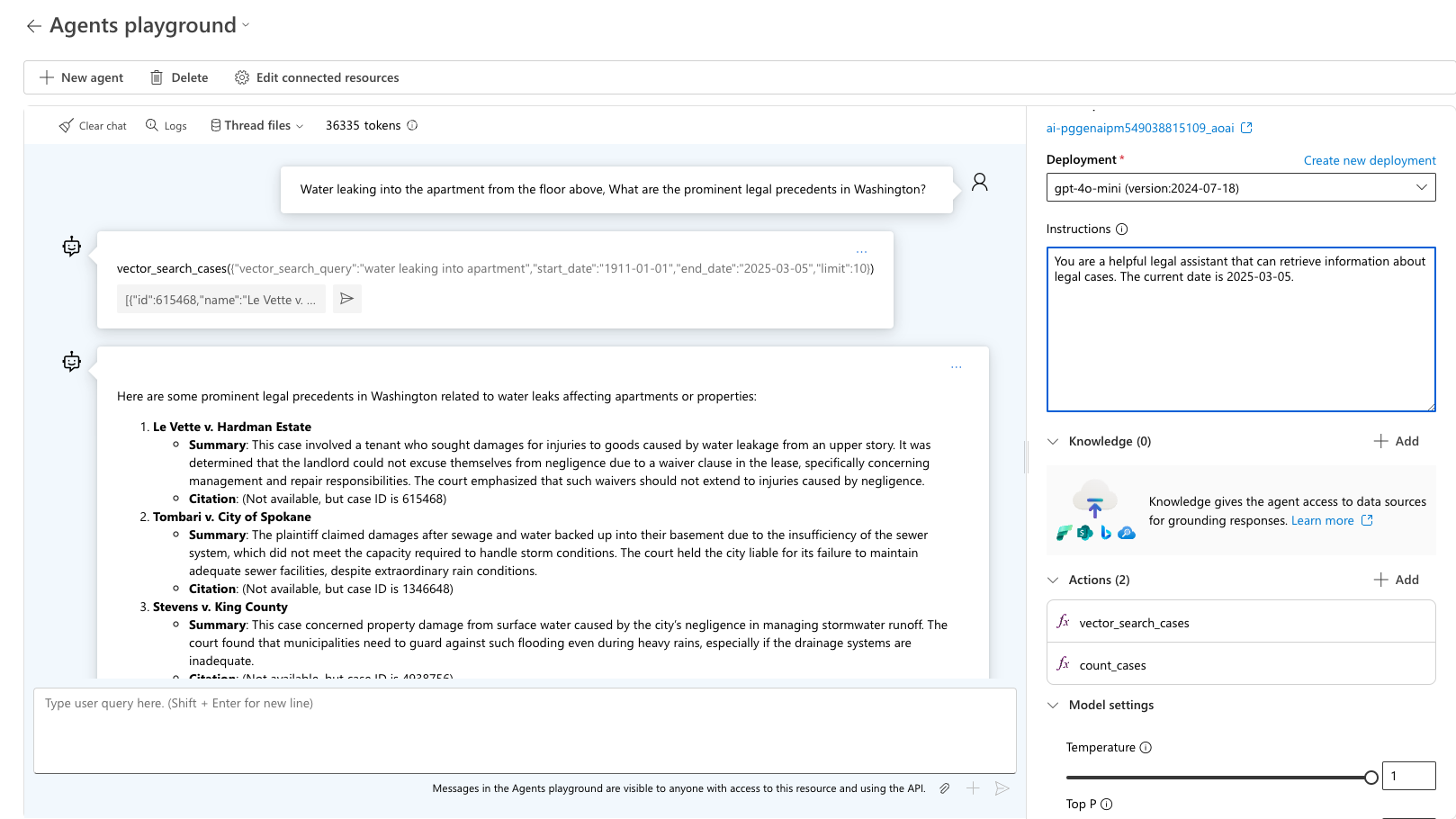
Протестируйте запрос "Утечка воды в квартиру с верхнего этажа, что такое известные юридические прецеденты в Вашингтоне?" Агент выбирает подходящее средство для использования и запрашивает ожидаемые выходные данные для этого запроса. Используйте sample_vector_search_cases_output.json в качестве примера выходных данных.
Шаг 5: Отладка с использованием средств трассировки Azure AI Foundry
При разработке агента с помощью пакета SDK службы агента Azure AI Foundry можно выполнить отладку агента с помощью трассировки. Трассировка позволяет отлаживать вызовы таких инструментов, как Postgres, и узнать, как агент управляет каждой задачей.
В Azure AI Foundry перейдите к трассировке.
Чтобы создать ресурс Application Insights, нажмите кнопку "Создать". Чтобы подключить существующий ресурс, выберите один из них в поле имени ресурса Application Insights и нажмите кнопку Connect.
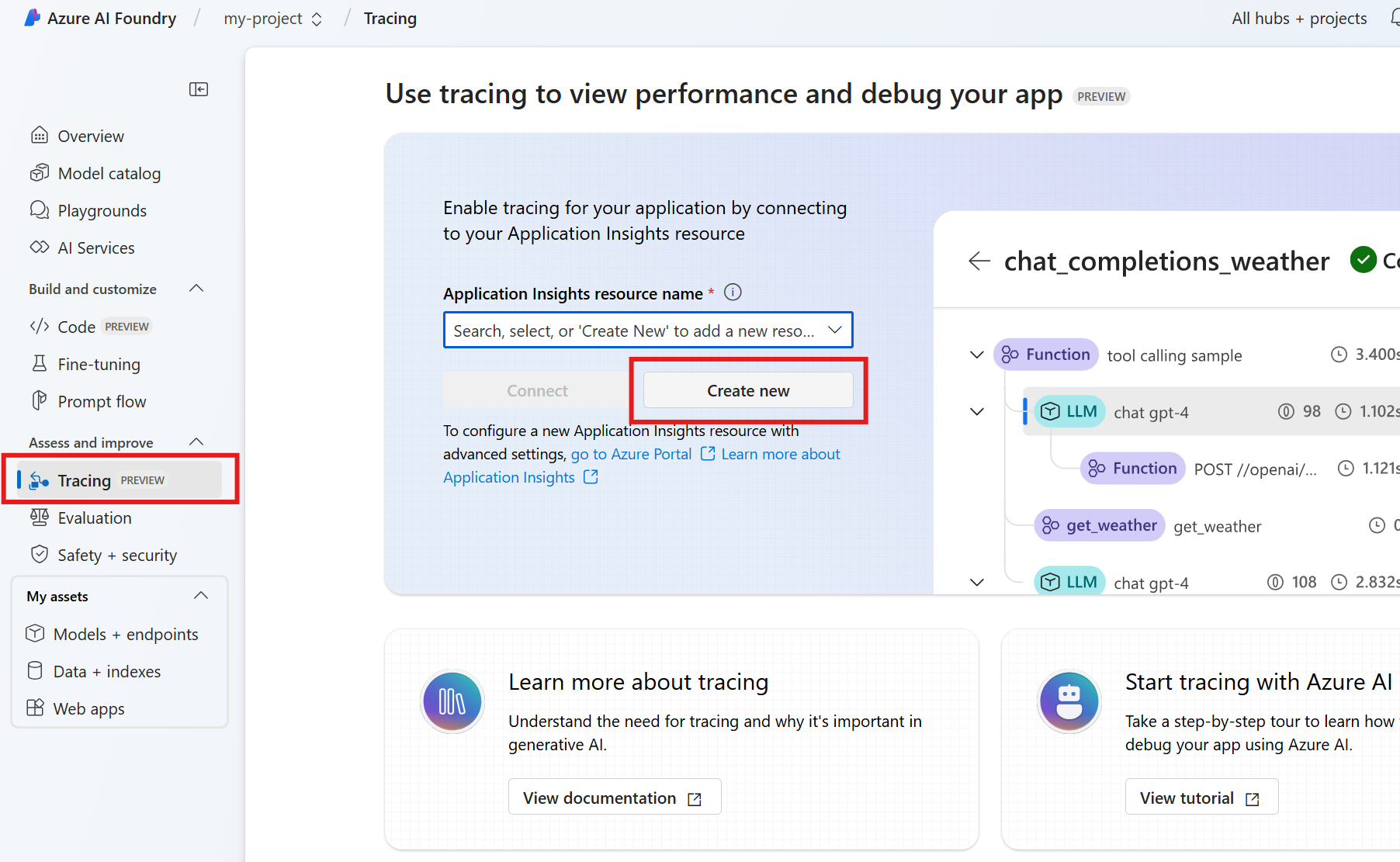
Просмотрите подробные трассировки операций агента.
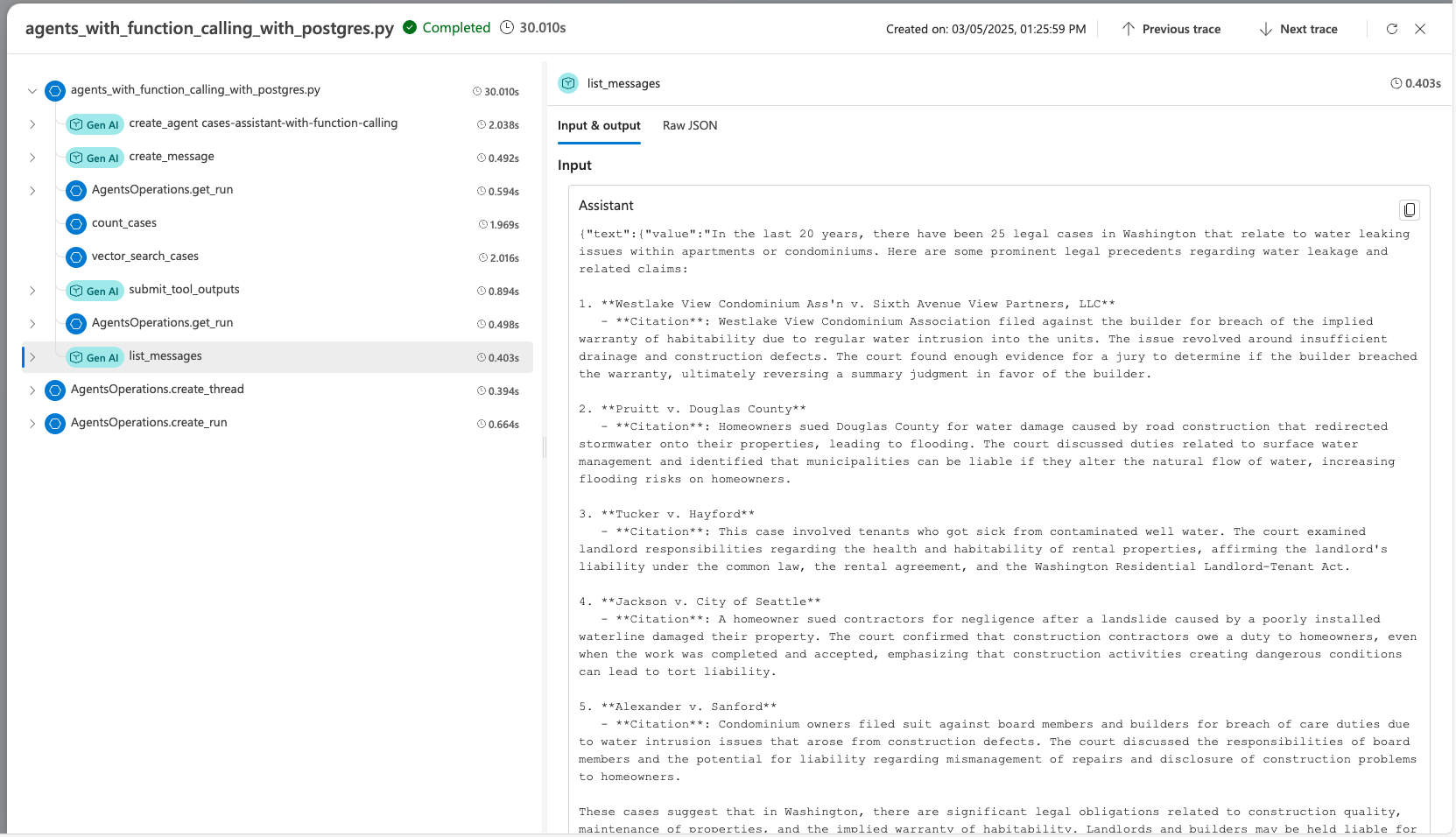
Узнайте больше о настройке трассировки с помощью агента ИИ и Postgres в файле advanced_postgres_and_ai_agent_with_tracing.py на GitHub.
Связанный контент
- Интеграция Базы данных Azure для PostgreSQL для приложений ИИ
- Использование LangChain с базой данных Azure для PostgreSQL
- Создание векторных вложений с помощью Azure OpenAI в Базе данных Azure для PostgreSQL
- Расширение ИИ Azure в Базе данных Azure для PostgreSQL
- Создание семантического поиска с помощью Базы данных Azure для PostgreSQL и Azure OpenAI
- Включение и использование pgvector в Базе данных Azure для PostgreSQL