Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:
![]() Azure Cosmos DB для PostgreSQL (с использованием расширения Citus для PostgreSQL)
Azure Cosmos DB для PostgreSQL (с использованием расширения Citus для PostgreSQL)
Идентификатор арендатора в качестве ключа шардирования
Идентификатор клиента — это столбец в корне рабочей нагрузки или в верхней части иерархии в модели данных. Например, в этой схеме электронной коммерции SaaS это будет идентификатор магазина:
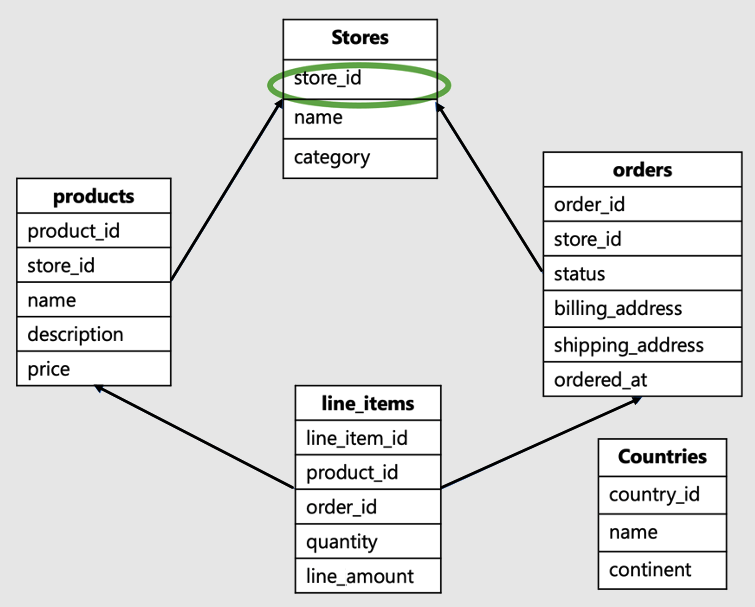
Это распространенная модель данных для бизнеса, например, ее использует Shopify. Компания размещает сайты нескольких интернет-магазинов, причем каждый магазин взаимодействует только со своими данными.
- Эта модель данных содержит множество таблиц: магазины, продукты, заказы, позиции и страны.
- Таблица магазинов расположена в верхней части иерархии. Продукты, заказы и позиции связаны с магазинами, поэтому находятся ниже в иерархии.
- Таблица стран не связана с отдельными магазинами, а охватывает несколько магазинов.
В этом примере store_id находится в верхней части иерархии и является идентификатором клиента. Это правильный ключ шарда. Выбор store_id в качестве ключа сегмента позволяет совместно размещать данные во всех таблицах для одного магазина на одном рабочем узле.
Совместное размещение таблиц в магазине имеет свои преимущества.
- Предоставляет охват SQL, например внешние ключи, операции JOIN. Транзакции для одного клиента локализованы на одном рабочем узле, где существует каждый клиент.
- Достигает производительности в единицы миллисекунд. Запросы для одного клиента направляются на один узел, без использования параллелизации, что помогает оптимизировать сетевые прыжки и при этом масштабировать вычислительные ресурсы и память.
- Это масштабируется. По мере роста числа арендаторов можно добавлять узлы и перераспределять арендаторов на новые узлы, а также выделить крупных арендаторов на собственные узлы. Изоляция клиента позволяет предоставлять выделенные ресурсы.
Оптимальная модель данных для мультитенантных приложений
В этом примере мы должны распределить таблицы, относящиеся к конкретному магазину, по идентификатору магазина, и создать ссылочную таблицу countries.
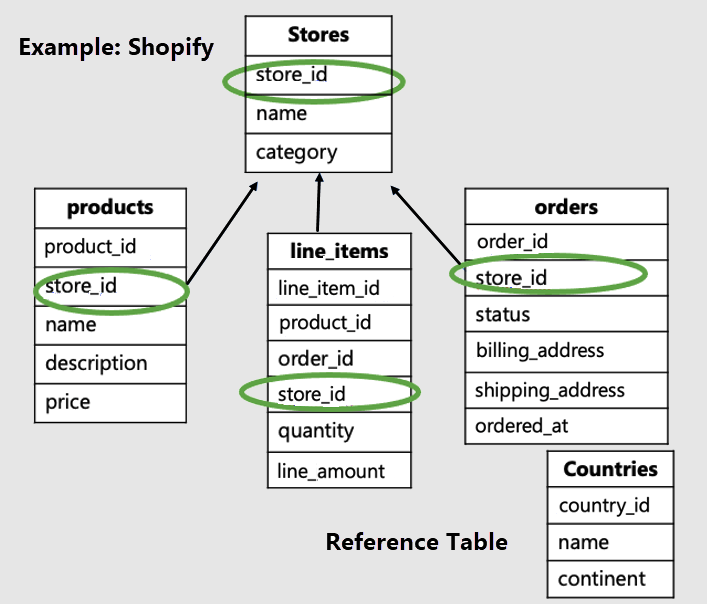
Обратите внимание, что таблицы, относящиеся к клиенту, содержат идентификатор клиента и являются распределенными. В нашем примере таблицы stores (магазины), products (продукты) и line_items (позиции) являются распределенными. Остальные таблицы являются ссылочными таблицами. В нашем примере таблица стран является ссылочной таблицей.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Большие таблицы должны иметь идентификатор клиента.
- Если вы переносите существующее мультитенантное приложение в Azure Cosmos DB для PostgreSQL, возможно, потребуется немного денормализировать и добавить столбец идентификатора клиента в большие таблицы, если он отсутствует, а затем вернуть отсутствующие значения столбца.
- Для новых приложений в Azure Cosmos DB для PostgreSQL убедитесь, что идентификатор клиента присутствует во всех таблицах, относящихся к клиенту.
Убедитесь в включении идентификатора тенанта в ограничения первичного, уникального и внешнего ключа в распределенных таблицах в виде составного ключа. Например, если таблица имеет первичный ключ id, превратите его в составной ключ (tenant_id,id).
Нет необходимости менять ключи для ссылочных таблиц.
Рекомендации по выполнению запросов для оптимальной производительности
Распределенные запросы с фильтрацией по идентификатору клиента, выполняются наиболее эффективно в мультитенантных приложениях. Убедитесь, что запросы всегда ограничены одним клиентом.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
Необходимо добавить фильтр идентификатора клиента, даже если исходные условия фильтра однозначно идентифицируют нужные строки. Фильтр идентификатора арендатора, хоть и кажущийся избыточным, сообщает Azure Cosmos DB для PostgreSQL, как направить запрос к единственному рабочему узлу.
Аналогичным образом, при соединении двух распределенных таблиц, убедитесь, что обе таблицы адаптированы к одному клиенту. Чтобы определить область, нужно включить в условия соединения идентификатор клиента.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Существуют вспомогательные библиотеки для нескольких популярных платформ приложений, которые упрощают включение идентификатора клиента в запросы. Инструкции:
Следующие шаги
Мы закончили изучение моделирования данных для масштабируемых приложений. Следующим шагом является подключение и запрос базы данных с использованием выбранного языка программирования.