Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Baza danych SQL w usłudze Microsoft Fabric (wersja zapoznawcza)
Baza danych SQL w usłudze Microsoft Fabric (wersja zapoznawcza)
Program SQL Server wykonuje operacje sortowania, przecięcia, unii i różnic przy użyciu technologii sortowania i łączenia skrótów w pamięci. Korzystając z tego typu planu zapytań, program SQL Server obsługuje partycjonowanie tabeli pionowej.
Program SQL Server implementuje operacje sprzężenia logicznego określone przez składnię Transact-SQL:
- Inner join
- Lewe zewnętrzne połączenie
- Zewnętrzne sprzężenie prawe
- Pełne łączenie zewnętrzne
- Cross join
Note
Aby uzyskać więcej informacji na temat składni sprzężenia, zobacz KLAUZULA FROM oraz JOIN, APPLY, PIVOT (Transact-SQL).
Program SQL Server wykorzystuje cztery typy operacji sprzężenia fizycznego do wykonywania operacji sprzężenia logicznego:
- Sprzężenia zagnieżdżonych pętli
- Merge joins
- Hash joins
- Sprzężenia adaptacyjne (począwszy od programu SQL Server 2017 (14.x))
Join fundamentals
Za pomocą sprzężeń można pobrać dane z co najmniej dwóch tabel na podstawie relacji logicznych między tabelami. Sprzężenia wskazują, jak program SQL Server powinien używać danych z jednej tabeli do wybierania wierszy w innej tabeli.
Warunek sprzężenia definiuje sposób, w jaki dwie tabele są powiązane w zapytaniu przez:
- Określanie kolumny z każdej tabeli do wykorzystania przy sprzężeniu. Typowy warunek sprzężenia określa klucz obcy z jednej tabeli i skojarzony z nim klucz w drugiej tabeli.
- Określanie operatora logicznego (na przykład = lub <>, ), który ma być używany w porównywaniu wartości z kolumn.
Sprzężenia są wyrażane logicznie przy użyciu następującej składni Transact-SQL:
- INNER JOIN
- LEWE [ ZEWNĘTRZNE ] SPRZĘŻENIA
- PRAWE [ ZEWNĘTRZNE ] SPRZĘŻENIA
- PEŁNE [ ZEWNĘTRZNE ] SPRZĘŻENIA
- CROSS JOIN
Sprzężenia wewnętrzne można określić w FROM klauzulach or WHERE .
Sprzężenia zewnętrzne i sprzężenia krzyżowe można określić tylko w klauzuli .FROM Warunki sprzężenia łączą się z WHERE warunkami wyszukiwania i HAVING w celu kontrolowania wierszy wybranych z tabel bazowych, do których odwołuje się klauzula FROM .
Określenie warunków sprzężenia w klauzuli FROM pomaga oddzielić je od innych warunków wyszukiwania, które mogą być określone w WHERE klauzuli, i jest zalecaną metodą określania sprzężeń. Uproszczona składnia sprzężenia klauzul ISO FROM to:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- Join_type określa, jakiego rodzaju sprzężenie jest wykonywane: sprzężenie wewnętrzne, zewnętrzne lub krzyżowe. Aby uzyskać wyjaśnienia różnych typów sprzężeń, zobacz klauzulę FROM.
- Join_condition definiuje predykat, który ma być oceniany dla każdej pary sprzężonych wierszy.
Poniższy kod jest przykładem specyfikacji FROM sprzężenia klauzuli:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Poniższy kod jest prostą SELECT instrukcją używającą tego sprzężenia:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Instrukcja SELECT zwraca informacje o produkcie i dostawcy dla dowolnej kombinacji części dostarczonych przez firmę, dla której nazwa firmy zaczyna się od litery F, a cena produktu jest większa niż 10 USD.
Jeśli w jednym zapytaniu odwołuje się wiele tabel, wszystkie odwołania do kolumn muszą być jednoznaczne. W poprzednim przykładzie obie tabele ProductVendor i Vendor mają kolumnę o nazwie BusinessEntityID. Każda nazwa kolumny, która jest zduplikowana między co najmniej dwiema tabelami, do których odwołuje się kwerenda, musi być kwalifikowana przy użyciu nazwy tabeli. Wszystkie odwołania do Vendor kolumn w przykładzie są kwalifikowane.
Jeśli nazwa kolumny nie jest duplikowana w co najmniej dwóch tabelach używanych w zapytaniu, odwołania do niej nie muszą być kwalifikowane z nazwą tabeli. Jest to pokazane w poprzednim przykładzie. Taka klauzula czasami jest trudna SELECT do zrozumienia, ponieważ nie ma nic do wskazania tabeli, która dostarczyła każdą kolumnę. Czytelność zapytania jest ulepszona, jeśli wszystkie kolumny są kwalifikowane przy użyciu ich nazw tabel. Czytelność jest jeszcze bardziej ulepszona, jeśli są używane aliasy tabel, zwłaszcza gdy same nazwy tabel muszą być kwalifikowane z bazą danych i nazwami właścicieli. Poniższy kod jest tym samym przykładem, z tą różnicą, że aliasy tabeli zostały przypisane, a kolumny kwalifikowane za pomocą aliasów tabeli w celu zwiększenia czytelności:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
W poprzednich przykładach określono warunki sprzężenia w klauzuli FROM , która jest preferowaną metodą. Następujące zapytanie zawiera ten sam warunek sprzężenia określony w klauzuli WHERE :
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Lista SELECT sprzężenia może odwoływać się do wszystkich kolumn w tabelach sprzężonych lub dowolny podzestaw kolumn. Lista nie jest wymagana SELECT do zawierania kolumn z każdej tabeli w sprzężeniu. Na przykład w sprzężeniu z trzema tabelami tylko jedna tabela może służyć do łączenia z jednej z pozostałych tabel do trzeciej tabeli, a żadna z kolumn z tabeli środkowej nie musi być przywoływanych na liście wyboru. Jest to również nazywane sprzężeniami antysemickimi.
Chociaż warunki sprzężenia zwykle mają porównania równości (=), można określić inne operatory porównania lub relacyjne, podobnie jak inne predykaty. Aby uzyskać więcej informacji, zobacz Operatory porównania (Transact-SQL) i WHERE (Transact-SQL).
Podczas łączenia procesów programu SQL Server optymalizator zapytań wybiera najbardziej wydajną metodę (poza kilkoma możliwościami) przetwarzania sprzężenia. Obejmuje to wybór najbardziej wydajnego typu sprzężenia fizycznego, kolejność łączenia tabel, a nawet przy użyciu typów operacji sprzężenia logicznego, których nie można bezpośrednio wyrazić za pomocą składni Transact-SQL, takich jak sprzężenia częściowe i sprzężenia częściowe. Fizyczne wykonywanie różnych sprzężeń może używać wielu różnych optymalizacji i dlatego nie można niezawodnie przewidzieć. Aby uzyskać więcej informacji na temat częściowych sprzężeń i sprzężeń antysemickich, zobacz Showplan Logical and Physical Operators Reference (Dokumentacja operatorów logicznych i fizycznych programu Showplan).
Kolumny używane w warunku sprzężenia nie są wymagane do posiadania tej samej nazwy lub tego samego typu danych. Jeśli jednak typy danych nie są identyczne, muszą być zgodne lub typy, które program SQL Server może niejawnie konwertować. Jeśli nie można niejawnie przekonwertować typów danych, warunek sprzężenia musi jawnie przekonwertować typ danych przy użyciu CAST funkcji . Aby uzyskać więcej informacji na temat niejawnych i jawnych konwersji, zobacz Konwersja typów danych (aparat bazy danych).
Większość zapytań używających sprzężenia może zostać przepisana przy użyciu podzapytania (zapytanie zagnieżdżone w ramach innego zapytania), a większość podzapytania może zostać przepisana jako sprzężenia. Aby uzyskać więcej informacji na temat podzapytania, zobacz Podzapytania.
Note
Tabele nie mogą być łączone bezpośrednio w kolumnach ntext, text lub image. Tabele można jednak łączyć pośrednio w kolumnach ntext, text lub image przy użyciu polecenia SUBSTRING.
Na przykład SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) wykonuje sprzężenie wewnętrzne z dwiema tabelami na pierwszych 20 znakach każdej kolumny tekstowej w tabelach t1 i t2.
Ponadto kolejną możliwością porównywania ntekstu lub kolumn tekstowych z dwóch tabel jest porównanie długości kolumn z klauzulą WHERE , na przykład: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Omówienie sprzężeń zagnieżdżonych pętli
Jeśli jedno wejście sprzężenia jest małe (mniej niż 10 wierszy), a inne dane wejściowe sprzężenia są dość duże i indeksowane w kolumnach sprzężenia sprzężenia, sprzężenie zagnieżdżone indeksu jest najszybszą operacją sprzężenia, ponieważ wymagają najmniejszego we/wy i najmniejszych porównań.
Sprzężenie zagnieżdżonych pętli, nazywane również iteracją zagnieżdżonych, używa jednego wejścia sprzężenia jako zewnętrznej tabeli wejściowej (pokazanej jako pierwsze dane wejściowe w planie wykonywania graficznego) i jednej jako wewnętrznej (dolnej) tabeli wejściowej. Pętla zewnętrzna używa zewnętrznego wiersza tabeli wejściowej według wiersza. Pętla wewnętrzna wykonywana dla każdego wiersza zewnętrznego wyszukuje pasujące wiersze w wewnętrznej tabeli wejściowej.
W najprostszym przypadku wyszukiwanie skanuje całą tabelę lub indeks; jest to nazywane naiwnym sprzężeniami zagnieżdżonych. Jeśli wyszukiwanie wykorzystuje indeks, jest nazywane sprzężeniami zagnieżdżonych indeksów. Jeśli indeks jest tworzony jako część planu zapytania (i niszczony po zakończeniu zapytania), jest nazywany tymczasowym sprzężeniem zagnieżdżonych pętli indeksu. Wszystkie te warianty są brane pod uwagę przez Optymalizator zapytań.
Sprzężenie zagnieżdżonych pętli jest szczególnie skuteczne, jeśli dane wejściowe zewnętrzne są małe, a dane wejściowe wewnętrzne są wstępnie indeksowane i duże. W wielu małych transakcjach, takich jak te wpływające tylko na niewielki zestaw wierszy, sprzężenia zagnieżdżone indeksu są lepsze zarówno dla sprzężeń scalania, jak i sprzężeń skrótów. Jednak w dużych zapytaniach sprzężenia zagnieżdżone często nie są optymalnym wyborem.
Gdy atrybut OPTIMIZED operatora sprzężenia zagnieżdżonego ma wartość True, oznacza to, że zoptymalizowane pętle zagnieżdżone (lub sortowanie wsadowe) są używane do zminimalizowania liczby operacji we/wy, gdy tabela wewnętrzna jest duża, niezależnie od tego, czy jest równoległa, czy nie. Obecność tej optymalizacji w danym planie może nie być bardzo oczywista podczas analizowania planu wykonania, biorąc pod uwagę, że sam sortowanie jest operacją ukrytą. Jednak patrząc w kodzie XML planu dla atrybutu OPTIMIZED, oznacza to, że sprzężenie zagnieżdżonych pętli może spróbować zmienić kolejność wierszy wejściowych w celu zwiększenia wydajności operacji we/wy.
Merge joins
Jeśli dwa sprzężenia wejściowe nie są małe, ale są sortowane w kolumnie sprzężenia (na przykład jeśli zostały uzyskane przez skanowanie posortowanych indeksów), sprzężenie scalania jest najszybszą operacją sprzężenia. Jeśli oba wejścia sprzężenia są duże, a dwa dane wejściowe mają podobne rozmiary, sprzężenia scalania z wcześniejszym sortowaniem i sprzężenia skrótu oferują podobną wydajność. Jednak operacje sprzężenia skrótu są często znacznie szybsze, jeśli dwa rozmiary wejściowe różnią się znacznie od siebie.
Sprzężenie scalania wymaga sortowania obu danych wejściowych w kolumnach scalania, które są definiowane przez klauzule równości (ON) predykatu sprzężenia. Optymalizator zapytań zwykle skanuje indeks, jeśli istnieje w odpowiednim zestawie kolumn lub umieszcza operator sortowania poniżej sprzężenia seryjnego. W rzadkich przypadkach może istnieć wiele klauzul równości, ale kolumny scalania są pobierane tylko z niektórych dostępnych klauzul równości.
Ponieważ każde dane wejściowe są sortowane, operator Scal sprzężenia pobiera wiersz z każdego danych wejściowych i porównuje je. Na przykład w przypadku operacji sprzężenia wewnętrznego wiersze są zwracane, jeśli są równe. Jeśli nie są równe, wiersz o niższej wartości zostanie odrzucony, a inny wiersz zostanie uzyskany z tych danych wejściowych. Ten proces powtarza się do momentu przetworzenia wszystkich wierszy.
Operacja łączenia scalania jest operacją regularną lub wiele-do-wielu. Sprzężenie scalania wiele-do-wielu używa tabeli tymczasowej do przechowywania wierszy. Jeśli istnieją zduplikowane wartości z poszczególnych danych wejściowych, jeden z danych wejściowych musi się przewinąć na początek duplikatów, ponieważ każdy duplikat z innych danych wejściowych jest przetwarzany.
Jeśli predykat reszt jest obecny, wszystkie wiersze spełniające predykat scalania obliczają predykat reszt i zwracane są tylko te wiersze, które je spełniają.
Samo sprzężenia scalania są bardzo szybkie, ale może to być kosztowny wybór, jeśli wymagane są operacje sortowania. Jeśli jednak wolumin danych jest duży, a żądane dane można uzyskać wstępnie z istniejących indeksów drzewa B, sprzężenie scalania jest często najszybszym dostępnym algorytmem sprzężenia.
Hash joins
Sprzężenia skrótów mogą efektywnie przetwarzać duże, niesortowane, nieindeksowane dane wejściowe. Są one przydatne w przypadku wyników pośrednich w złożonych zapytaniach, ponieważ:
- Wyniki pośrednie nie są indeksowane (chyba że jawnie zapisane na dysku, a następnie indeksowane) i często nie są odpowiednio sortowane dla następnej operacji w planie zapytania.
- Optymalizatory zapytań szacują tylko pośrednie rozmiary wyników. Ponieważ szacunki mogą być bardzo niedokładne w przypadku złożonych zapytań, algorytmy przetwarzania wyników pośrednich nie tylko muszą być wydajne, ale także muszą bezpiecznie obniżyć wydajność, jeśli wynik pośredni okaże się znacznie większy niż oczekiwano.
Sprzężenie skrótu umożliwia zmniejszenie użycia denormalizacji. Denormalizacja jest zwykle używana do osiągnięcia lepszej wydajności przez zmniejszenie operacji sprzężenia, pomimo niebezpieczeństw związanych z nadmiarowością, takich jak niespójne aktualizacje. Sprzężenia skrótu zmniejszają konieczność denormalizacji. Sprzężenia skrótu umożliwiają partycjonowanie pionowe (reprezentujące grupy kolumn z pojedynczej tabeli w osobnych plikach lub indeksach) staje się realną opcją projektowania fizycznej bazy danych.
Sprzężenia skrótu mają dwa dane wejściowe: dane wejściowe kompilacji i dane wejściowe sondy . Optymalizator zapytań przypisuje te role, tak aby mniejsze z dwóch danych wejściowych było danymi wejściowymi kompilacji.
Sprzężenia skrótu są używane w przypadku wielu typów operacji dopasowywania zestawów: sprzężenia wewnętrznego; lewe, prawe i pełne sprzężenia zewnętrzne; lewe i prawe półsprzężenia; skrzyżowanie; unia; i różnice. Ponadto wariant sprzężenia skrótu może wykonywać zduplikowane usuwanie i grupowanie, takie jak SUM(salary) GROUP BY department. Te modyfikacje używają tylko jednego danych wejściowych zarówno dla ról kompilacji, jak i sondy.
W poniższych sekcjach opisano różne typy sprzężeń skrótów: sprzężenia skrótu w pamięci, sprzężenia skrótu grace i sprzężenia cyklicznego skrótu.
Sprzężenia skrótu w pamięci
Funkcja sprzężenia skrótu najpierw skanuje lub oblicza całe dane wejściowe kompilacji, a następnie tworzy tabelę skrótów w pamięci. Każdy wiersz jest wstawiany do zasobnika skrótu w zależności od wartości skrótu obliczonej dla klucza skrótu. Jeśli całe dane wejściowe kompilacji są mniejsze niż dostępna pamięć, wszystkie wiersze można wstawić do tabeli skrótów. Po fazie kompilacji następuje faza sondy. Całe dane wejściowe sondy są skanowane lub obliczane jeden wiersz jednocześnie, a dla każdego wiersza sondy wartość klucza skrótu jest obliczana, odpowiedni zasobnik skrótu jest skanowany, a dopasowania są generowane.
Sprzężenia skrótu Grace
Jeśli dane wejściowe kompilacji nie mieszczą się w pamięci, sprzężenia skrótu będzie kontynuowane w kilku krokach. Jest to nazywane sprzężenia skrótu grace. Każdy krok ma fazę kompilacji i fazę sondy. Początkowo całe dane wejściowe kompilacji i sondy są używane i partycjonowane (przy użyciu funkcji skrótu w kluczach skrótu) do wielu plików. Użycie funkcji skrótu w kluczach skrótu gwarantuje, że wszystkie dwa rekordy łączenia muszą znajdować się w tej samej parze plików. W związku z tym zadanie łączenia dwóch dużych danych wejściowych zostało zredukowane do wielu, ale mniejszych wystąpień tych samych zadań. Sprzężenie skrótu jest następnie stosowane do każdej pary plików partycjonowanych.
Rekursywne sprzężenia skrótu
Jeśli dane wejściowe kompilacji są tak duże, że dane wejściowe dla standardowego scalania zewnętrznego wymagają wielu poziomów scalania, wymagane są wiele kroków partycjonowania i wiele poziomów partycjonowania. Jeśli tylko niektóre partycje są duże, dodatkowe kroki partycjonowania są używane tylko dla tych określonych partycji. Aby umożliwić jak najszybsze wykonanie wszystkich kroków partycjonowania, duże, asynchroniczne operacje we/wy są używane tak, aby jeden wątek mógł zachować wiele dysków zajętych.
Note
Jeśli dane wejściowe kompilacji są tylko nieco większe niż dostępna pamięć, elementy sprzężenia skrótu w pamięci i sprzężenia skrótu grace są łączone w jednym kroku, tworząc sprzężenie skrótu hybrydowego.
Podczas optymalizacji nie zawsze jest możliwe określenie, które sprzężenie skrótu jest używane. W związku z tym program SQL Server rozpoczyna się przy użyciu sprzężenia skrótu w pamięci i stopniowo przechodzi do sprzężenia skrótu prolongaty i cyklicznego sprzężenia skrótu w zależności od rozmiaru danych wejściowych kompilacji.
Jeśli optymalizator zapytań przewiduje błędnie, które z dwóch danych wejściowych jest mniejsze i dlatego powinny być danymi wejściowymi kompilacji, role kompilacji i sondy są odwracane dynamicznie. Sprzężenie skrótu zapewnia, że używa mniejszego pliku przepełnienia jako danych wejściowych kompilacji. Ta technika jest nazywana odwróceniem roli. Odwrócenie roli występuje wewnątrz sprzężenia skrótu po co najmniej jednym rozlaniu na dysk.
Note
Odwrócenie roli odbywa się niezależnie od wszelkich wskazówek zapytania lub struktury. Odwrócenie roli nie jest wyświetlane w planie zapytania; gdy wystąpi, jest niewidoczny dla użytkownika.
Hash bailout
Termin ratowania skrótu jest czasami używany do opisywania sprzężeń skrótu grace lub cyklicznych sprzężeń skrótu.
Note
Rekursywne sprzężenia skrótów lub ratowania skrótów powodują zmniejszenie wydajności serwera. Jeśli w śladzie jest wyświetlanych wiele zdarzeń ostrzegawczych skrótów, zaktualizuj statystyki dotyczące kolumn, które są przyłączone.
Aby uzyskać więcej informacji na temat ratowania skrótów, zobacz Hash Warning Event Class (Klasa zdarzenia ostrzeżenia skrótu).
Adaptive joins
Tryb wsadowy Sprzężenia adaptacyjne umożliwiają odroczenie wyboru metody sprzężenia sprzężenia skrótu lub sprzężenia zagnieżdżonego do momentu, gdy pierwsze dane wejściowe zostaną zeskanowane. Operator Sprzężenia Adaptacyjnego definiuje próg, który określa moment przełączenia się na plan zagnieżdżonych pętli. W związku z tym plan zapytania może dynamicznie przełączyć się na lepszą strategię sprzężenia podczas wykonywania bez konieczności ponownego komilowania.
Tip
Obciążenia z częstymi oscylacjemi między małymi i dużymi skanami wejściowymi sprzężenia będą najbardziej korzystne dla tej funkcji.
Decyzja środowiska uruchomieniowego jest oparta na następujących krokach:
- Jeśli liczba wierszy danych wejściowych sprzężenia kompilacji jest wystarczająco mała, że sprzężenie zagnieżdżonych pętli byłoby bardziej optymalne niż sprzężenie skrótu, plan przejdzie do algorytmu zagnieżdżonych pętli.
- Jeśli dane wejściowe sprzężenia kompilacji przekraczają określony próg liczby wierszy, żaden przełącznik nie wystąpi, a plan będzie kontynuowany przy użyciu sprzężenia skrótu.
Następujące zapytanie służy do zilustrowania przykładu adaptacyjnego sprzężenia:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
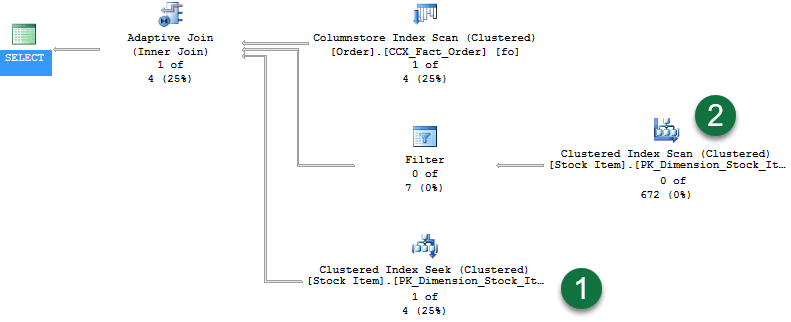
Zapytanie zwraca 336 wierszy. Włączenie statystyk zapytań na żywo wyświetla następujący plan:

W planie zwróć uwagę na następujące kwestie:
- Skanowanie indeksu magazynu kolumn używane do udostępniania wierszy dla fazy kompilacji sprzężenia skrótu.
- Nowy operator sprzężenia adaptacyjnego. Ten operator definiuje próg, który służy do decydowania, kiedy należy przełączyć się do planu zagnieżdżonych pętli. W tym przykładzie próg wynosi 78 wierszy. Wszystkie elementy z >= 78 wierszy będą używać sprzężenia skrótu. Jeśli wartość mniejsza niż próg, zostanie użyte sprzężenia zagnieżdżone.
- Ponieważ zapytanie zwraca 336 wierszy, przekroczyło to próg, a więc druga gałąź reprezentuje fazę sondy standardowej operacji sprzężenia skrótu. Statystyki zapytań na żywo pokazują wiersze przepływające przez operatory — w tym przypadku "672 z 672".
- Ostatnią gałęzią jest wyszukiwanie indeksu klastrowanego do użycia przez sprzężenia zagnieżdżonych pętli, ponieważ próg nie został przekroczony. Zostaną wyświetlone wiersze "0 z 336" (gałąź jest nieużywane).
Teraz porównaj plan z tym samym zapytaniem, ale jeśli Quantity wartość ma tylko jeden wiersz w tabeli:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
Zapytanie zwraca jeden wiersz. Włączenie statystyk zapytań na żywo wyświetla następujący plan:
W planie zwróć uwagę na następujące kwestie:
- Po zwróceniu jednego wiersza funkcja Wyszukiwania indeksu klastrowanego ma teraz przepływające wiersze.
- Ponieważ faza kompilacji sprzężenia skrótu nie została kontynuowana, nie ma wierszy przepływających przez drugą gałąź.
Uwagi dotyczące adaptacyjnego sprzężenia
Sprzężenia adaptacyjne wprowadzają większe wymaganie dotyczące pamięci niż indeksowany plan sprzężenia zagnieżdżonego sprzężenia równoważnego. Żądana jest dodatkowa pamięć, tak jakby pętle zagnieżdżone były sprzężenia skrótu. Istnieje również obciążenie dla fazy kompilacji jako operacji zatrzymania i przejścia w porównaniu z zagnieżdżonym sprzężeniami przesyłania strumieniowego pętli. Dzięki tym dodatkowym kosztom jest elastyczność w scenariuszach, w których liczba wierszy waha się w danych wejściowych kompilacji.
Sprzężenia adaptacyjne trybu wsadowego działają na potrzeby początkowego wykonywania instrukcji, a po skompilowaniu kolejne wykonania pozostaną adaptacyjne na podstawie skompilowanego progu sprzężenia adaptacyjnego i wierszy środowiska uruchomieniowego przepływających przez fazę kompilacji danych wejściowych zewnętrznych.
Jeśli sprzężenie adaptacyjne przełączy się do operacji zagnieżdżonych pętli, używa wierszy już odczytanych przez kompilację sprzężenia skrótu. Operator nie odczytuje ponownie zewnętrznych wierszy odwołań.
Śledzenie działania adaptacyjnego sprzężenia
Operator adaptacyjnego sprzężenia ma następujące atrybuty operatora planu:
| Plan attribute | Description |
|---|---|
| AdaptiveThresholdRows | Przedstawia użycie wartości progowej, aby przełączyć się z sprzężenia skrótu na sprzężenie zagnieżdżonej pętli. |
| EstimatedJoinType | Jaki typ sprzężenia prawdopodobnie będzie. |
| ActualJoinType | W rzeczywistym planie pokazano, jaki algorytm sprzężenia został ostatecznie wybrany na podstawie progu. |
Szacowany plan przedstawia kształt planu sprzężenia adaptacyjnego wraz ze zdefiniowanym progiem sprzężenia adaptacyjnego i szacowanym typem sprzężenia.
Tip
Magazyn zapytań przechwytuje i może wymusić tryb wsadowy plan adaptacyjnego sprzężenia.
Instrukcje uprawniające do przyłączenia adaptacyjnego
Kilka warunków sprawia, że sprzężenia logicznego kwalifikują się do sprzężenia adaptacyjnego w trybie wsadowym:
- Poziom zgodności bazy danych wynosi 140 lub więcej.
- Zapytanie jest instrukcją
SELECT(instrukcje modyfikacji danych są obecnie niekwalifikowane). - Sprzężenie kwalifikuje się do wykonania zarówno przez indeksowane sprzężenia zagnieżdżone pętle, jak i algorytm fizyczny sprzężenia skrótu.
- Sprzężenie skrótu używa trybu usługi Batch, włączonego przez obecność indeksu magazynu kolumn w zapytaniu ogólnym, indeksowaną tabelę magazynu kolumn, do którego odwołuje się sprzężenie, lub za pomocą trybu usługi Batch w magazynie wierszy.
- Wygenerowane alternatywne rozwiązania sprzężenia zagnieżdżonych pętli i sprzężenia skrótu powinny mieć to samo pierwsze podrzędne (odwołanie zewnętrzne).
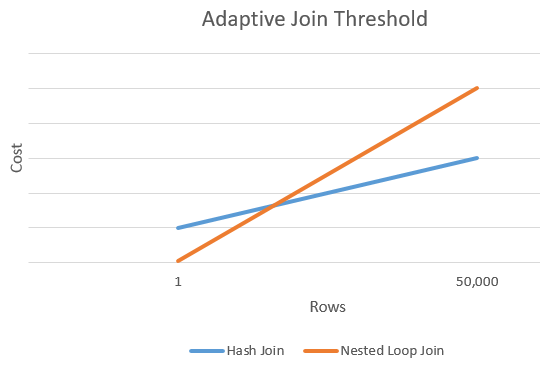
Wiersze progu adaptacyjnego
Na poniższym wykresie przedstawiono przykładowe przecięcie między kosztem sprzężenia skrótu a kosztem alternatywnego sprzężenia zagnieżdżonych pętli. W tym punkcie przecięcia próg jest określany, że z kolei określa rzeczywisty algorytm używany do operacji sprzężenia.
Wyłączanie sprzężeń adaptacyjnych bez zmiany poziomu zgodności
Sprzężenia adaptacyjne można wyłączyć w zakresie bazy danych lub instrukcji, zachowując zgodność bazy danych na poziomie 140 i wyższym.
Aby wyłączyć sprzężenia adaptacyjne dla wszystkich wykonań zapytań pochodzących z bazy danych, wykonaj następujące czynności w kontekście odpowiedniej bazy danych:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Po włączeniu to ustawienie jest wyświetlane jako włączone w sys.database_scoped_configurations.
Aby ponownie włączyć sprzężenia adaptacyjne dla wszystkich wykonań zapytań pochodzących z bazy danych, wykonaj następujące czynności w kontekście odpowiedniej bazy danych:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Sprzężenia adaptacyjne można również wyłączyć dla określonego zapytania, określając DISABLE_BATCH_MODE_ADAPTIVE_JOINS jako wskazówkę zapytania USE HINT. For example:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
Wskazówka zapytania USE HINT ma pierwszeństwo przed ustawieniem konfiguracji w zakresie bazy danych lub flagi śledzenia.
Wartości null i sprzężenia
Jeśli w kolumnach połączonych tabel istnieją wartości null, wartości null nie są ze sobą zgodne. Obecność wartości null w kolumnie z jednej ze sprzężonych tabel może być zwracana tylko przy użyciu sprzężenia zewnętrznego (chyba że WHERE klauzula nie wyklucza wartości null).
Poniżej przedstawiono dwie tabele, które mają NULL w kolumnie, która będzie uczestniczyć w sprzężeniu:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Sprzężenia, które porównuje wartości w kolumnie a z kolumną c , nie uzyskuje dopasowania w kolumnach, które mają wartości NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Zwracany jest tylko jeden wiersz z wartością 4 w kolumnach ac :
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Wartości null zwracane z tabeli podstawowej są również trudne do odróżnienia od wartości null zwracanych z sprzężenia zewnętrznego. Na przykład następująca SELECT instrukcja wykonuje lewe sprzężenia zewnętrzne na tych dwóch tabelach:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Oto zestaw wyników.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Wyniki nie ułatwiają odróżnienia NULL elementu w danych od elementu reprezentującego NULL błąd sprzężenia. Gdy wartości NULL są obecne w danych sprzężonych, zwykle zaleca się pominięcie ich z wyników przy użyciu zwykłego sprzężenia.
Related content
- Odwołanie do operatorów logicznych i fizycznych Showplan
- Operatory porównania (Transact-SQL)
-
konwersji typu danych (aparatu bazy danych) - Subqueries
- Adaptive Joins
- Klauzula FROM oraz JOIN, APPLY, PIVOT (Transact-SQL)