Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Baza danych SQL w usłudze Microsoft Fabric (wersja zapoznawcza)
Baza danych SQL w usłudze Microsoft Fabric (wersja zapoznawcza)
Brak funkcji indeksów jest lekkim narzędziem do znajdowania brakujących indeksów, które mogą znacznie poprawić wydajność zapytań. W tym artykule opisano sposób używania brakujących sugestii dotyczących indeksów w celu efektywnego dostrajania indeksów i zwiększania wydajności zapytań.
Ograniczenia brakującej funkcji indeksu
Gdy optymalizator zapytań generuje plan zapytania, analizuje najlepsze indeksy dla określonego warunku filtru. Jeśli najlepsze indeksy nie istnieją, optymalizator zapytań nadal generuje plan zapytania przy użyciu metod dostępu najmniej kosztowny, ale także przechowuje informacje o tych indeksach. Funkcja brakujących indeksów umożliwia dostęp do tych informacji o najlepszych możliwych indeksach, dzięki czemu można zdecydować, czy mają być implementowane.
Optymalizacja zapytań jest procesem wrażliwym na czas, dlatego istnieją ograniczenia dotyczące brakującej funkcji indeksu. Limitations include:
- Brakujące sugestie dotyczące indeksu są oparte na oszacowaniach dokonanych podczas optymalizacji pojedynczego zapytania przed wykonaniem zapytania. Brakujące sugestie dotyczące indeksu nie są testowane ani aktualizowane po wykonaniu zapytania.
- Brak funkcji indeksu sugeruje tylko nieklastrowane indeksy magazynu wierszy oparte na dysku. Indeksy unikatowe i filtrowane nie są sugerowane.
- Sugerowane są kolumny kluczy, ale sugestia nie określa kolejności dla tych kolumn. Aby uzyskać informacje na temat porządkowania kolumn, zobacz sekcję Stosowanie brakujących sugestii dotyczących indeksu w tym artykule.
- Sugerowane są dołączone kolumny , ale program SQL Server nie przeprowadza analizy kosztów i korzyści dotyczących rozmiaru wynikowego indeksu, gdy sugerowana jest duża liczba dołączonych kolumn.
- Brakujące żądania indeksu mogą oferować podobne odmiany indeksów w tej samej tabeli i kolumnach w zapytaniach. Ważne jest , aby przejrzeć sugestie dotyczące indeksu i połączyć je tam, gdzie to możliwe.
- Sugestie nie są tworzone dla trywialnych planów zapytań.
- Informacje o kosztach są mniej dokładne w przypadku zapytań obejmujących tylko predykaty nierówności.
- Sugestie są zbierane dla maksymalnie 600 brakujących grup indeksów. Po osiągnięciu tego progu nie są zbierane żadne brakujące dane grupy indeksów.
Ze względu na te ograniczenia brakujące sugestie indeksu najlepiej traktować jako jedno z kilku źródeł informacji podczas przeprowadzania analizy indeksu, projektowania, dostrajania i testowania. Brakujące sugestie indeksu nie są receptami na tworzenie indeksów dokładnie tak, jak sugerowano.
Note
Usługa Azure SQL Database oferuje automatyczne dostrajanie indeksów. Automatyczne dostrajanie indeksów używa uczenia maszynowego do nauki w poziomie ze wszystkich baz danych w usłudze Azure SQL Database za pośrednictwem sztucznej inteligencji i dynamicznego ulepszania akcji dostrajania. Automatyczne dostrajanie indeksów obejmuje proces weryfikacji, aby upewnić się, że istnieje pozytywna poprawa wydajności obciążenia z utworzonych indeksów.
Wyświetlanie brakujących rekomendacji dotyczących indeksu
Brak funkcji indeksów składa się z dwóch składników:
- Element
MissingIndexesw kodzie XML planów wykonywania. Dzięki temu można skorelować indeksy, których optymalizator zapytań uważa za brakujące w zapytaniach, dla których brakuje. - Zestaw dynamicznych widoków zarządzania (DMV), których można odpytować, aby zwrócić informacje o brakujących indeksach. Dzięki temu można wyświetlić wszystkie brakujące zalecenia dotyczące indeksu dla bazy danych.
Wyświetlanie brakujących sugestii dotyczących indeksu w planach wykonywania
Plany wykonywania zapytań można wygenerować lub uzyskać na wiele sposobów:
- Podczas pisania lub dostrajania zapytania można użyć programu SQL Server Management Studio (SSMS), aby wyświetlić szacowany plan wykonania bez uruchamiania zapytania lub wykonać zapytanie i wyświetlić rzeczywisty plan wykonania.
- Magazyn zapytań, po włączeniu, zbiera plany wykonywania.
- Można zidentyfikować buforowane plany wykonywania, wykonując zapytania dotyczące widoków DMV, takich jak sys.dm_exec_text_query_plan.
Możesz na przykład użyć następującego zapytania, aby wygenerować brakujące żądania indeksu względem przykładowej bazy danych AdventureWorks.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
Aby wygenerować i wyświetlić brakujące żądania indeksu:
Otwórz program SSMS i połącz sesję z kopią przykładowej bazy danych AdventureWorks.
Wklej zapytanie do sesji i wygeneruj szacowany plan wykonania w programie SSMS dla zapytania, wybierając przycisk pasek narzędzi Wyświetl szacowany plan wykonania . Plan wykonania zostanie wyświetlony w okienku w bieżącej sesji. Zielona instrukcja Missing Index będzie wyświetlana w górnej części planu graficznego.
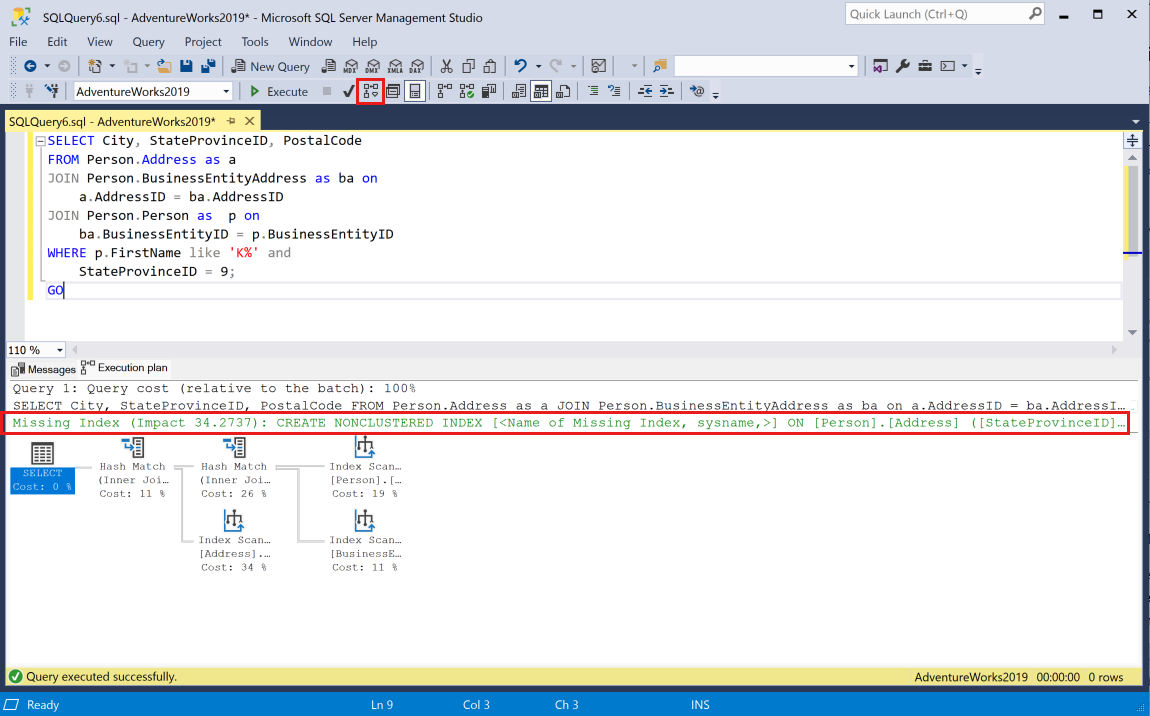
Pojedynczy plan wykonania może zawierać wiele brakujących żądań indeksu, ale w planie wykonywania grafiki może być wyświetlanych tylko jedno brakujące żądanie indeksu. Jedną z opcji wyświetlenia pełnej listy brakujących indeksów dla planu wykonania jest wyświetlenie kodu XML planu wykonania.
Kliknij prawym przyciskiem myszy plan wykonania i wybierz polecenie Pokaż kod XML planu wykonania... z menu.
Plik XML planu wykonywania zostanie otwarty jako nowa karta w programie SSMS.
Note
Tylko jedna brakująca sugestia indeksu będzie wyświetlana w opcji menu Brak szczegółów indeksu... nawet jeśli w pliku XML planu wykonywania znajduje się wiele sugestii. Wyświetlona sugestia dotycząca brakującego indeksu może nie być jedyną z najwyższym szacowanymi ulepszeniami zapytania.
Wyświetl okno dialogowe Znajdź przy użyciu skrótu CTRL+f .
Wyszukaj
MissingIndex.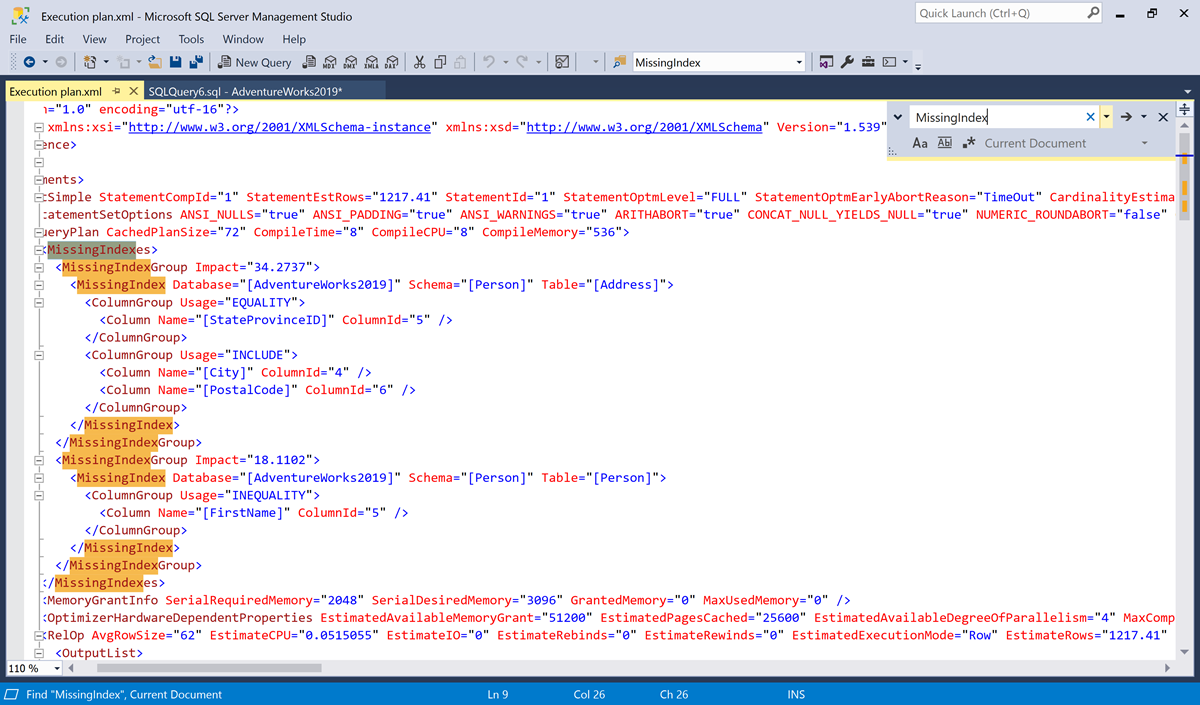
W tym przykładzie istnieją dwa
MissingIndexelementy.- Pierwszy brakujący indeks sugeruje, że zapytanie może używać indeksu
Person.Addressw tabeli, który obsługuje wyszukiwanie równości wStateProvinceIDkolumnie, która zawiera jeszcze dwie kolumnyCityiPostalCode". W momencie optymalizacji optymalizator zapytań uważa, że ten indeks może zmniejszyć szacowany koszt zapytania o 34,2737%. - Drugi brakujący indeks sugeruje, że zapytanie może używać indeksu
Person.Personw tabeli obsługującej wyszukiwanie nierówności w kolumnie FirstName. W momencie optymalizacji optymalizator zapytań uważa, że ten indeks może zmniejszyć szacowany koszt zapytania o 18,1102%.
- Pierwszy brakujący indeks sugeruje, że zapytanie może używać indeksu


Każdy indeks nieklastrowany na dysku w bazie danych zajmuje miejsce, zwiększa obciążenie wstawiania, aktualizacji i usuwania oraz może wymagać konserwacji. Z tych powodów najlepszym rozwiązaniem jest przejrzenie wszystkich brakujących żądań indeksu dla tabeli i istniejących indeksów w tabeli przed dodaniem indeksu na podstawie planu wykonywania zapytania.
Wyświetlanie brakujących sugestii dotyczących indeksu w widokach DMV
Informacje o brakujących indeksach można pobrać, wykonując zapytanie dotyczące dynamicznych obiektów zarządzania wymienionych w poniższej tabeli.
| Dynamiczny widok zarządzania | Information returned |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | Zwraca podsumowanie informacji o brakujących grupach indeksów, na przykład ulepszenia wydajności, które można uzyskać, implementując określoną grupę brakujących indeksów. |
| sys.dm_db_missing_index_groups (Transact-SQL) | Zwraca informacje o określonej grupie brakujących indeksów, takich jak identyfikator grupy i identyfikatory wszystkich brakujących indeksów zawartych w tej grupie. |
| sys.dm_db_missing_index_details (Transact-SQL) | Zwraca szczegółowe informacje dotyczące brakującego indeksu; na przykład zwraca nazwę i identyfikator tabeli, w której brakuje indeksu, oraz kolumny i typy kolumn, które powinny stanowić brakujący indeks. |
| sys.dm_db_missing_index_columns (Transact-SQL) | Zwraca informacje o kolumnach tabeli bazy danych, które nie mają indeksu. |
Poniższe zapytanie używa brakujących widoków DMV indeksu do generowania instrukcji CREATE INDEX. Instrukcje tworzenia indeksu są tutaj przeznaczone do ułatwienia tworzenia własnego języka DDL po zbadaniu wszystkich żądań dla tabeli wraz z istniejącymi indeksami w tabeli.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
To zapytanie porządkuje sugestie według kolumny o nazwie estimated_improvement. Szacowana poprawa jest oparta na kombinacji:
- Szacowany koszt zapytania zapytań skojarzony z brakującym żądaniem indeksu.
- Szacowany wpływ dodawania indeksu. Jest to oszacowanie, ile indeks nieklastrowany zmniejszy koszt zapytania.
- Suma wykonań operatorów zapytań (wyszukiwanie i skanowanie), które zostały uruchomione dla zapytań skojarzonych z brakiem żądania indeksu. W miarę jak omawiamy utrwalanie brakujących indeksów w magazynie zapytań, te informacje są okresowo czyszczone.
Note
Skrypt tworzenia indeksu w przyborniku tiger firmy Microsoft sprawdza brakujące dynamiczne widoki zarządzania indeksami i automatycznie usuwa wszelkie nadmiarowe sugerowane indeksy, analizuje indeksy o niskim wpływie i generuje skrypty tworzenia indeksów do przeglądu. Podobnie jak w powyższym zapytaniu, nie wykonuje poleceń tworzenia indeksu. Skrypt tworzenia indeksu jest odpowiedni dla programu SQL Server i usługi Azure SQL Managed Instance. W przypadku usługi Azure SQL Database rozważ zaimplementowanie automatycznego dostrajania indeksów.
Przejrzyj ograniczenia brakującej funkcji indeksu i sposób stosowania brakujących sugestii indeksu przed utworzeniem indeksów i zmodyfikuj nazwę indeksu, aby była zgodna z konwencją nazewnictwa bazy danych.
Utrwalanie brakujących indeksów za pomocą magazynu zapytań
Brakujące sugestie indeksu w widokach DMV są czyszczone przez zdarzenia, takie jak ponowne uruchomienia wystąpień, tryb failover i ustawienie bazy danych w trybie offline. Ponadto po zmianie metadanych tabeli wszystkie brakujące informacje o indeksie tej tabeli zostaną usunięte z tych dynamicznych obiektów zarządzania. Zmiany metadanych tabeli mogą wystąpić, gdy kolumny są dodawane lub porzucane z tabeli, na przykład lub gdy indeks jest tworzony w kolumnie tabeli. Wykonanie operacji ALTER INDEX REBUILD w indeksie w tabeli powoduje również wyczyszczenie brakujących żądań indeksu dla tej tabeli.
Podobnie plany wykonywania przechowywane w pamięci podręcznej planu są czyszczone przez zdarzenia, takie jak ponowne uruchamianie wystąpień, tryb failover i ustawianie bazy danych w trybie offline. Plany wykonywania mogą zostać usunięte z pamięci podręcznej z powodu ciśnienia pamięci i ponownej kompilacji.
Brakujące sugestie dotyczące indeksu w planach wykonywania można utrwalać w tych zdarzeniach, włączając magazyn zapytań.
Poniższe zapytanie pobiera 20 pierwszych planów zapytań zawierających brakujące żądania indeksu z magazynu zapytań na podstawie przybliżonego oszacowania łącznej liczby odczytów logicznych dla zapytania. Dane są ograniczone do wykonywania zapytań w ciągu ostatnich 48 godzin.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Stosowanie brakujących sugestii dotyczących indeksu
Aby skutecznie używać brakujących sugestii dotyczących indeksu, postępuj zgodnie z wytycznymi dotyczącymi projektowania indeksów nieklastrowanych. Podczas dostrajania indeksów nieklastrowanych z brakującymi sugestiami indeksu przejrzyj strukturę tabeli podstawowej, starannie połącz indeksy, rozważ kolejność kolumn kluczowych i przejrzyj dołączone sugestie dotyczące kolumn.
Przejrzyj strukturę tabeli podstawowej
Przed utworzeniem indeksów nieklastrowanych w tabeli na podstawie brakujących sugestii indeksu przejrzyj indeks klastrowany tabeli.
Jednym ze sposobów sprawdzenia indeksu klastrowanego jest użycie procedury składowanej systemu sp_helpindex . Na przykład możemy wyświetlić podsumowanie indeksów w Person.Address tabeli, wykonując następującą instrukcję:
exec sp_helpindex 'Person.Address';
GO
Przejrzyj kolumnę index_description. Tabela może zawierać tylko jeden indeks klastrowany. Jeśli indeks klastrowany został zaimplementowany dla tabeli, index_description będzie zawierać słowo "clustered".

Jeśli nie ma indeksu klastrowanego, tabela jest stertą. W takim przypadku sprawdź, czy tabela została celowo utworzona w formie sterty, aby rozwiązać określony problem z wydajnością. Większość tabel korzysta z indeksów klastrowanych: często tabele są implementowane w sposób przypadkowy. Rozważ zaimplementowanie indeksu klastrowanego na podstawie wytycznych dotyczących projektowania indeksu klastrowanego.
Przejrzyj brakujące indeksy i istniejące indeksy pod kątem nakładania się
Brakujące indeksy mogą oferować podobne odmiany indeksów nieklastrowanych w tej samej tabeli i kolumnach w zapytaniach. Brakujące indeksy mogą być również podobne do istniejących indeksów w tabeli. Aby uzyskać optymalną wydajność, najlepiej zbadać brakujące indeksy i istniejące indeksy pod kątem nakładania się i unikać tworzenia zduplikowanych indeksów.
Tworzenie skryptów istniejących indeksów w tabeli
Jednym ze sposobów zbadania definicji istniejących indeksów w tabeli jest utworzenie skryptu indeksów za pomocą szczegółów Eksploratora obiektów:
- Połącz Eksplorator obiektów z wystąpieniem lub bazą danych.
- Rozwiń węzeł dla danej bazy danych w Eksploratorze obiektów.
- Rozwiń folder Tables.
- Rozwiń tabelę, dla której chcesz utworzyć skrypt indeksów.
- Wybierz folder Indeksy .
- Jeśli okienko Szczegóły Eksploratora obiektów nie jest jeszcze otwarte, w menu Widok wybierz pozycję Szczegóły Eksploratora obiektów lub naciśnij F7.
- Zaznacz wszystkie indeksy wymienione w okienku Szczegóły Eksploratora obiektów za pomocą skrótu CTRL+a.
- Kliknij prawym przyciskiem myszy w dowolnym miejscu w wybranym regionie i wybierz opcję Indeks skryptu jako, a następnie utwórz do i nowe okno edytora zapytań.

Przeglądanie indeksów i łączenie tam, gdzie to możliwe
Przejrzyj brakujące zalecenia dotyczące indeksu dla tabeli jako grupy wraz z definicjami istniejących indeksów w tabeli. Należy pamiętać, że podczas definiowania indeksów kolumny równości powinny być umieszczane przed kolumnami nierówności i razem powinny one stanowić klucz indeksu. Aby określić efektywną kolejność kolumn równości, należy je uporządkować na podstawie ich wyboru: najpierw wyświetl najbardziej selektywne kolumny (po lewej stronie na liście kolumn). Unikatowe kolumny są najbardziej selektywne, a kolumny z wieloma powtarzającymi się wartościami są mniej selektywne.
Dołączone kolumny należy dodać do instrukcji CREATE INDEX przy użyciu klauzuli INCLUDE. Kolejność uwzględnionych kolumn nie ma wpływu na wydajność zapytań. W związku z tym podczas łączenia indeksów uwzględnione kolumny mogą być łączone bez obaw o kolejność. Dowiedz się więcej na temat zawartych wytycznych dotyczących kolumn.
Na przykład może istnieć tabela z Person.Addressistniejącym indeksem w kolumnie StateProvinceIDklucza . W tabeli mogą pojawić się brakujące zalecenia dotyczące indeksu Person.Address dla następujących kolumn:
- Filtry RÓWNOŚCI dla
StateProvinceIDiCity - Filtry RÓWNOŚCI dla
StateProvinceIDelementów iCity, INCLUDEPostalCode
Zmodyfikowanie istniejącego indeksu tak, aby był zgodny z drugim zaleceniem, indeks z kluczami w systemach StateProvinceID i City , PostalCodeprawdopodobnie spełnia zapytania, które wygenerowały obie sugestie indeksu.
Kompromisy są powszechne w dostrajaniu indeksu. Prawdopodobnie w przypadku wielu zestawów danych kolumna City jest bardziej selektywna niż kolumna StateProvinceID . Jeśli jednak nasz istniejący indeks jest StateProvinceID intensywnie używany, a inne żądania w dużej mierze wyszukują zarówno dla StateProvinceID bazy danych, jak i City, jest to niższe obciążenie dla bazy danych w ogóle, aby mieć pojedynczy indeks z obu kolumn w kluczu, co prowadzi w StateProvinceIDkolumnie , chociaż nie jest to najbardziej selektywna kolumna.
Indeksy mogą być modyfikowane na wiele sposobów:
- Instrukcję CREATE INDEX można użyć z klauzulą DROP_EXISTING. Możesz zmienić nazwę indeksów po modyfikacji, aby nazwa nadal dokładnie opisuje definicję indeksu w zależności od konwencji nazewnictwa.
- Możesz użyć instrukcji DROP INDEX (Transact-SQL), a następnie instrukcji CREATE INDEX.
Kolejność kluczy indeksu ma znaczenie podczas łączenia sugestii indeksu: City jako kolumna wiodąca różni się od StateProvinceID wiodącej kolumny. Dowiedz się więcej w wytycznych dotyczących projektowania indeksów nieklastrowanych.
Podczas tworzenia indeksów należy rozważyć użycie operacji indeksowania online , gdy są dostępne.
Chociaż indeksy mogą znacznie poprawić wydajność zapytań w niektórych przypadkach, indeksy również mają koszty związane z obciążeniem i zarządzaniem. Zapoznaj się z ogólnymi wytycznymi dotyczącymi projektowania indeksów , aby ułatwić ocenę korzyści z indeksów przed ich utworzeniem.
Sprawdź, czy zmiana indeksu zakończyła się pomyślnie
Ważne jest, aby sprawdzić, czy zmiany indeksu zakończyły się pomyślnie: czy optymalizator zapytań korzysta z indeksów?
Jednym ze sposobów weryfikacji zmian indeksu jest użycie magazynu zapytań do identyfikowania zapytań z brakującymi żądaniami indeksu. Zanotuj query_id dla zapytań. Użyj widoku Śledzone zapytania w magazynie zapytań, aby sprawdzić, czy plany wykonywania zostały zmienione dla zapytania i czy optymalizator używa nowego lub zmodyfikowanego indeksu. Dowiedz się więcej o śledzonych zapytaniach na początku od rozwiązywania problemów z wydajnością zapytań.
Related content
Dowiedz się więcej o dostrajaniu indeksu i wydajności w następujących artykułach: