Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:
![]() Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
De distributiekolom van elke tabel kiezen, is een van de belangrijkste modelleringsbeslissingen die u moet nemen. In Azure Cosmos DB for PostgreSQL worden rijen opgeslagen in shards op basis van de waarde van de distributiekolom van de rijen.
De juiste keuze groepeert gerelateerde gegevens op dezelfde fysieke knooppunten, waardoor queries sneller worden uitgevoerd en ondersteuning biedt voor alle SQL-functionaliteiten. Een onjuiste keuze maakt dat het systeem langzaam wordt uitgevoerd.
Algemene tips
Hier volgen vier criteria voor het kiezen van de ideale distributiekolom voor uw gedistribueerde tabellen.
Kies een kolom die een centraal onderdeel is van de workload van de toepassing.
U kunt deze kolom beschouwen als het 'hart', 'centraal stuk' of 'natuurlijke dimensie' voor het partitioneren van gegevens.
Voorbeelden:
-
device_idin een IoT-workload -
security_idvoor een financiële app die effecten bijhoudt -
user_idbij gebruikersanalyse -
tenant_idvoor een SaaS-toepassing met meerdere tenants
-
Kies een kolom met fatsoenlijke kardinaliteit en een gelijkmatige statistische verdeling.
De kolom moet veel waarden hebben en grondig en gelijkmatig verdelen tussen alle shards.
Voorbeelden:
- Kardinaliteit meer dan 1000
- Kies geen kolom met dezelfde waarde voor een groot percentage rijen (scheeftrekken van gegevens)
- In een SaaS-workload kan het zijn dat één tenant veel groter is dan de rest, wat kan leiden tot gegevensscheeftrekking. Voor deze situatie kunt u tenantisolatie gebruiken om een speciale shard te maken die de tenant afhandelt.
Kies een kolom die van uw bestaande query's profiteert.
Voor een transactionele of operationele workload (waarbij de meeste query's slechts een paar milliseconden duren), kiest u een kolom die wordt weergegeven als filter in
WHEREcomponenten voor ten minste 80% van de query's. Bijvoorbeeld dedevice_idkolom inSELECT * FROM events WHERE device_id=1.Voor een analytische workload (waarbij de meeste query's 1-2 seconden duren), kiest u een kolom waarmee query's kunnen worden geparallelliseerd tussen werkknooppunten. Een kolom die vaak voorkomt in GROUP BY-componenten of die meerdere waarden tegelijk heeft opgevraagd.
Kies een kolom die aanwezig is in de meeste grote tabellen.
Tabellen van meer dan 50 GB moeten worden gedistribueerd. Wanneer u voor allemaal dezelfde distributiekolom kiest, kunt u de gegevens voor die kolom samenbrengen op werkknooppunten. Co-locatie maakt het efficiënt om JOINs en rollups uit te voeren en foreign keys af te dwingen.
De andere (kleinere) tabellen kunnen lokale of referentietabellen zijn. Als de kleinere tabel JOIN met gedistribueerde tabellen nodig heeft, maakt u deze een referentietabel.
Gebruikssituatievoorbeelden
We hebben algemene criteria gezien voor het kiezen van de distributiekolom. Laten we nu eens kijken hoe ze van toepassing zijn op veelvoorkomende use cases.
Apps met meerdere tenants
De architectuur met meerdere tenants maakt gebruik van een vorm van hiërarchische databasemodellering om query's over knooppunten in het cluster te verdelen. De bovenkant van de gegevenshiërarchie wordt de tenant-id genoemd en moet worden opgeslagen in een kolom in elke tabel.
Azure Cosmos DB for PostgreSQL inspecteert query's om te zien welke tenant-id ze gebruiken en zoekt de overeenkomende tabelshard. Hiermee wordt de query gerouteerd naar één werkknooppunt dat de shard bevat. Het uitvoeren van een query met alle relevante gegevens die op hetzelfde knooppunt worden geplaatst, wordt colocatie genoemd.
In het volgende diagram ziet u colocatie in het gegevensmodel met meerdere tenants. Het bevat twee tabellen, Accounts en Campaigns, elk gedistribueerd door account_id. De gearceerde vakken vertegenwoordigen shards. Groene shards worden samen opgeslagen op één werkknooppunt en blauwe shards worden opgeslagen op een ander werkknooppunt. U ziet hoe een joinquery tussen accounts en campagnes alle benodigde gegevens op één knooppunt bevat wanneer beide tabellen worden beperkt tot dezelfde account_id.
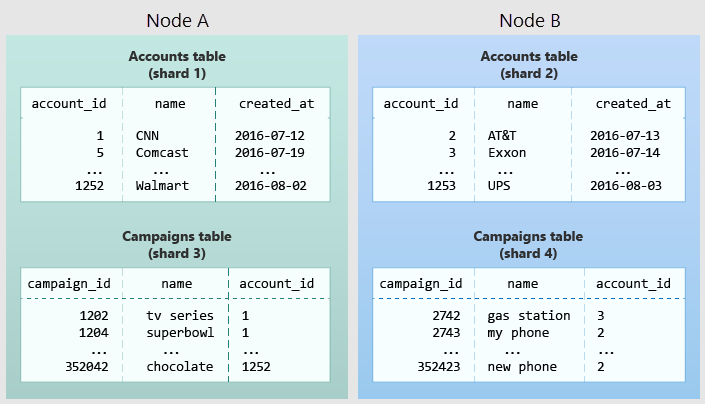
Als u dit ontwerp wilt toepassen in uw eigen schema, identificeert u wat een tenant in uw toepassing is. Veelgebruikte voorbeelden zijn onder andere bedrijf, account, organisatie of klant. De kolomnaam zal er ongeveer als volgt uitzien company_id of customer_id. Controleer al uw query's en vraag het uzelf af, of het werkt als er meer WHERE-componenten zijn om alle tabellen die betrokken zijn te beperken tot rijen met dezelfde tenant-id? Query's in het model met meerdere tenants zijn gericht op een tenant. Queries over verkoop of voorraad worden bijvoorbeeld binnen een bepaalde winkel geplaatst.
Beste praktijken
- Distribueer tabellen op basis van een gemeenschappelijke tenant_id-kolom. In een SaaS-toepassing waar tenants bedrijven zijn, is de tenant_id waarschijnlijk de company_id.
- Converteer kleine cross-tenant tabellen naar referentietabellen. Wanneer meerdere tenants een kleine tabel met gegevens delen, distribueert u deze als referentietabel.
- Beperk alle toepassingsquery's op tenant_id. Elke query moet informatie aanvragen voor één tenant tegelijk.
Lees de zelfstudie voor multi-tenant applicaties voor een voorbeeld van het bouwen van dit type toepassing.
Realtime-apps
De architectuur met meerdere tenants introduceert een hiërarchische structuur en maakt gebruik van gegevenscolocatie om query's per tenant te routeren. Realtime architecturen zijn daarentegen afhankelijk van specifieke distributie-eigenschappen van hun gegevens om zeer parallelle verwerking te bereiken.
We gebruiken 'entiteits-id' als een term voor distributiekolommen in het realtime-model. Typische entiteiten zijn gebruikers, hosts of apparaten.
Realtime-query's vragen doorgaans om numerieke aggregaties gegroepeerd op datum of categorie. Azure Cosmos DB for PostgreSQL verzendt deze query's naar elke shard voor gedeeltelijke resultaten en verzamelt het uiteindelijke antwoord op het coördinatorknooppunt. Query's worden het snelst uitgevoerd wanneer zoveel mogelijk knooppunten bijdragen en wanneer er geen enkel knooppunt een onevenredige hoeveelheid werk moet uitvoeren.
Beste praktijken
- Kies een kolom met een hoge kardinaliteit als de distributiekolom. Ter vergelijking is een veld Status in een ordertabel met de waarden Nieuw, Betaald en Verzonden een slechte keuze uit de distributiekolom. Er wordt uitgegaan van slechts die paar waarden, waarmee het aantal shards wordt beperkt dat de gegevens kan bevatten en het aantal knooppunten dat deze kan verwerken. Bij kolommen met een hoge kardinaliteit is het ook handig om die kolommen te kiezen die vaak worden gebruikt in group-by-componenten of als joinsleutels.
- Kies een kolom met gelijkmatige distributie. Als u een tabel distribueert op een kolom die neigt naar bepaalde gemeenschappelijke waarden, neigen gegevens in de tabel te accumuleren in specifieke shards. De knooppunten die deze shards bevatten, werken uiteindelijk meer dan andere knooppunten.
- Verspreid feit- en dimensietabellen op basis van hun gemeenschappelijke kolommen. Uw feitentabel kan slechts één distributiesleutel hebben. Tabellen die worden samengevoegd op een andere sleutel, worden niet gekoppeld aan de feitentabel. Kies één dimensie die u wilt instellen op basis van hoe vaak deze wordt samengevoegd en de grootte van de samenvoegingsrijen.
- Wijzig enkele dimensietabellen in referentietabellen. Als een dimensietabel niet kan worden gekoppeld aan de feitentabel, kunt u de queryprestaties verbeteren door kopieën van de dimensietabel te distribueren naar alle knooppunten in de vorm van een verwijzingstabel.
Lees de zelfstudie voor realtime dashboards voor een voorbeeld van het bouwen van dit type toepassing.
Tijdreeksgegevens
In een tijdreeksworkload doorzoeken toepassingen recente informatie terwijl ze oude informatie archiveren.
De meest voorkomende fout bij het modelleren van tijdreeksgegevens in Azure Cosmos DB for PostgreSQL is het gebruik van de tijdstempel zelf als een distributiekolom. Een hashdistributie op basis van tijd verdeelt tijd schijnbaar willekeurig over verschillende shards, in plaats van tijdsintervallen bij elkaar te houden binnen dezelfde shard. Queries die betrekking hebben op tijd, verwijzen meestal naar tijdsbereiken, zoals de meest recente gegevens. Dit type hash-distributie leidt tot netwerkoverhead.
Beste praktijken
- Kies geen tijdstempel als distributiekolom. Kies een andere distributiekolom. Gebruik in een app met meerdere tenants de tenant-id of gebruik in een realtime-app de entiteits-id.
- Gebruik in plaats daarvan PostgreSQL-tabelpartitionering voor tijd. Gebruik tabelpartitionering om een grote tabel met tijd geordende gegevens te splitsen in meerdere overgenomen tabellen, waarbij elke tabel verschillende tijdsbereiken bevat. Het distribueren van een Postgres-gepartitioneerde tabel resulteert in het aanmaken van shards voor de overgenomen tabellen.
Volgende stappen
- Meer informatie over hoe colocatie tussen gedistribueerde gegevens helpt bij het snel uitvoeren van query's.
- Ontdek de distributiekolom van een gedistribueerde tabel en andere nuttige diagnostische query's.