Windows Server 2019 では、記憶域スペース ダイレクトは、仮想マシン、サーバー、ドライブ、ボリューム、ネットワーク アダプターなど、広範なパフォーマンス履歴を記録して格納します。 Performance history is easy to query and process in PowerShell so you can quickly go from raw data to actual answers to questions like:
- 先週 CPU の急増は発生しましたか?
- 物理ディスクで異常な待機時間が発生していますか?
- 現在、最も多くのストレージ IOPS を使用している VM は何ですか?
- ネットワーク帯域幅は飽和状態ですか?
- このボリュームが空き領域を使い切るのは、いつですか?
- 過去 1 か月間に、最も多くのメモリを使用した VM は何ですか?
Get-ClusterPerf コマンドレットは、スクリプト用に構築されます。 アソシエーションを処理するために Get-VM や Get-PhysicalDisk のようなコマンドレットからの入力をパイプラインにより受け入れ、その出力を Sort-Object、Where-Object、Measure-Object のようなユーティリティ コマンドレットにパイプして、強力なクエリを素早く作成できます。
このトピックでは、上記の 6 つの質問に回答する 6 つのサンプル スクリプトを示し、説明します。 さまざまなデータや時間枠で、ピークの検出、平均の検出、傾向線のプロット、外れ値の検出などに適用できるパターンが紹介されています。 これらは無償のスタート コードとして提供され、コピー、拡張、再利用が可能です。
Note
簡潔にするために、サンプル スクリプトでは、高品質の PowerShell コードで予想されるエラー処理などの事柄を省略しています。 これらは主に、本番利用ではなく、インスピレーションと教育を目的としています。
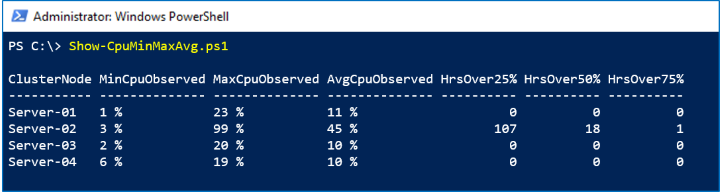
サンプル 1: CPU の確認
このサンプルでは、ClusterNode.Cpu.Usage 期間の LastWeek 系列を使用して、クラスター内のすべてのサーバーの最大 ("ハイ ウォーターマーク")、最小、および平均 CPU 使用率を示します。 また、簡単な四分位数分析を行って、過去 8 日間の CPU 使用率が 25%、50%、75% を超えた時間数を示します。
Screenshot
In the screenshot below, we see that Server-02 had an unexplained spike last week:
しくみ
Get-ClusterPerf からの出力は、組み込みの Measure-Object コマンドレットにうまくパイプされるので、Value プロパティを指定するだけです。
-Maximum、-Minimum、および、-Average フラグを使用すると、Measure-Object により最初の 3 つの列がほぼ無料で提供されます。 四分位数分析を行うには、Where-Object にパイプして、25、50、または 75 を超えた値の数をカウントできます。 最後の手順として、Format-Hours と Format-Percent ヘルパー関数を使用して美しくします (これは省略可能です)。
Script
スクリプトを次に示します。
Function Format-Hours {
Param (
$RawValue
)
# Weekly timeframe has frequency 15 minutes = 4 points per hour
[Math]::Round($RawValue/4)
}
Function Format-Percent {
Param (
$RawValue
)
[String][Math]::Round($RawValue) + " " + "%"
}
$Output = Get-ClusterNode | ForEach-Object {
$Data = $_ | Get-ClusterPerf -ClusterNodeSeriesName "ClusterNode.Cpu.Usage" -TimeFrame "LastWeek"
$Measure = $Data | Measure-Object -Property Value -Minimum -Maximum -Average
$Min = $Measure.Minimum
$Max = $Measure.Maximum
$Avg = $Measure.Average
[PsCustomObject]@{
"ClusterNode" = $_.Name
"MinCpuObserved" = Format-Percent $Min
"MaxCpuObserved" = Format-Percent $Max
"AvgCpuObserved" = Format-Percent $Avg
"HrsOver25%" = Format-Hours ($Data | Where-Object Value -Gt 25).Length
"HrsOver50%" = Format-Hours ($Data | Where-Object Value -Gt 50).Length
"HrsOver75%" = Format-Hours ($Data | Where-Object Value -Gt 75).Length
}
}
$Output | Sort-Object ClusterNode | Format-Table
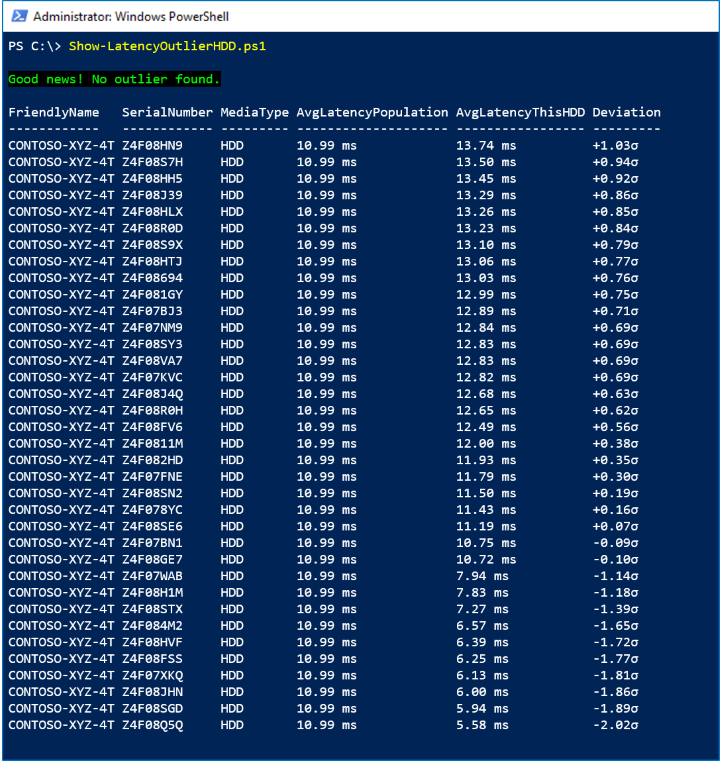
サンプル 2: 待機時間の外れ値
このサンプルでは、PhysicalDisk.Latency.Average 期間のLastHour 系列を使用し、統計的外れ値を探します。これは、1 時間あたりの平均待機時間が母集団平均よりも +3σ (標準偏差 3) を超えるドライブとして定義されています。
Important
簡潔にするために、このスクリプトは、低分散に対する安全策を実装しておらず、部分的に欠落しているデータを扱わず、モデルやファームウェアで区別しません。ハード ディスクを交換するかどうかは、このスクリプトだけに依存せず、適切な判断をしてください。 ここでは、教育目的でのみ提供されています。
Screenshot
次のスクリーンショットでは、外れ値がないことがわかります。
しくみ
まず、PhysicalDisk.Iops.Total が一貫して -Gt 1 (1 より大きい) ことをチェックして、アイドル状態またはほぼアイドル状態のドライブを除外します。 アクティブな HDD ごとに、10 秒間隔で 360 回の測定値で構成される LastHour 期間を Measure-Object -Average にパイプして、過去 1 時間の平均待機時間を取得します。 これにより、母集団が設定されます。
We implement the widely-known formula to find the mean μ and standard deviation σ of the population. アクティブな HDD ごとに、平均待機時間と母集団の平均を比較し、標準偏差で除算します。 生の値を保持し、結果を Sort-Object することができますが、Format-Latency と Format-StandardDeviation ヘルパー関数を使用して表示される結果を美しくします (これは省略可能です)。
ドライブが +3σ を超える場合は赤、それ以外の場合は緑で Write-Host します。
Script
スクリプトを次に示します。
Function Format-Latency {
Param (
$RawValue
)
$i = 0 ; $Labels = ("s", "ms", "μs", "ns") # Petabits, just in case!
Do { $RawValue *= 1000 ; $i++ } While ( $RawValue -Lt 1 )
# Return
[String][Math]::Round($RawValue, 2) + " " + $Labels[$i]
}
Function Format-StandardDeviation {
Param (
$RawValue
)
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + [String][Math]::Round([Math]::Abs($RawValue), 2) + "σ"
}
$HDD = Get-StorageSubSystem Cluster* | Get-PhysicalDisk | Where-Object MediaType -Eq HDD
$Output = $HDD | ForEach-Object {
$Iops = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Iops.Total" -TimeFrame "LastHour"
$AvgIops = ($Iops | Measure-Object -Property Value -Average).Average
If ($AvgIops -Gt 1) { # Exclude idle or nearly idle drives
$Latency = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Latency.Average" -TimeFrame "LastHour"
$AvgLatency = ($Latency | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"FriendlyName" = $_.FriendlyName
"SerialNumber" = $_.SerialNumber
"MediaType" = $_.MediaType
"AvgLatencyPopulation" = $null # Set below
"AvgLatencyThisHDD" = Format-Latency $AvgLatency
"RawAvgLatencyThisHDD" = $AvgLatency
"Deviation" = $null # Set below
"RawDeviation" = $null # Set below
}
}
}
If ($Output.Length -Ge 3) { # Minimum population requirement
# Find mean μ and standard deviation σ
$μ = ($Output | Measure-Object -Property RawAvgLatencyThisHDD -Average).Average
$d = $Output | ForEach-Object { ($_.RawAvgLatencyThisHDD - $μ) * ($_.RawAvgLatencyThisHDD - $μ) }
$σ = [Math]::Sqrt(($d | Measure-Object -Sum).Sum / $Output.Length)
$FoundOutlier = $False
$Output | ForEach-Object {
$Deviation = ($_.RawAvgLatencyThisHDD - $μ) / $σ
$_.AvgLatencyPopulation = Format-Latency $μ
$_.Deviation = Format-StandardDeviation $Deviation
$_.RawDeviation = $Deviation
# If distribution is Normal, expect >99% within 3σ
If ($Deviation -Gt 3) {
$FoundOutlier = $True
}
}
If ($FoundOutlier) {
Write-Host -BackgroundColor Black -ForegroundColor Red "Oh no! There's an HDD significantly slower than the others."
}
Else {
Write-Host -BackgroundColor Black -ForegroundColor Green "Good news! No outlier found."
}
$Output | Sort-Object RawDeviation -Descending | Format-Table FriendlyName, SerialNumber, MediaType, AvgLatencyPopulation, AvgLatencyThisHDD, Deviation
}
Else {
Write-Warning "There aren't enough active drives to look for outliers right now."
}
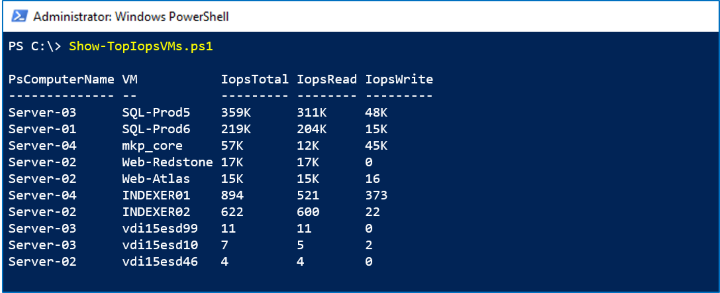
サンプル 3: ノイズの多い仮想マシン That's write!
Performance history can answer questions about right now, too. 新しい測定値は、10 秒ごとにリアルタイムで使用できます。 このサンプルでは、VHD.Iops.Total 期間の MostRecent 系列を使用して、クラスター内のすべてのホストで最も多くのストレージ IOPS を消費する仮想マシン ("ノイズが最も多い" と言う場合があります) を特定し、そのアクティビティの読み取り/書き込みの内訳を示します。
Screenshot
次のスクリーンショットには、ストレージ アクティビティ別に上位 10 台の仮想マシンが表示されています。
しくみ
Get-PhysicalDisk とは異なり、Get-VM コマンドレットはクラスターに対応しません。ローカル サーバー上の VM のみを返します。 すべてのサーバーから並列でクエリを実行するには、呼び出しを Invoke-Command (Get-ClusterNode).Name { ... } にラップします。 すべての VM について、VHD.Iops.Total、VHD.Iops.Read、および VHD.Iops.Write の測定値を取得します。
-TimeFrame パラメーターを指定しない場合は、それぞれの 1 つの MostRecent データ ポイントを取得します。
Tip
これらの系列は、この VM のアクティビティの合計を、そのすべての VHD/VHDX ファイルに反映します。 これは、パフォーマンス履歴が自動的に集計される例です。 VHD/VHDX ごとの内訳を取得するには、個々の Get-VHD を VM ではなく Get-ClusterPerf にパイプできます。
すべてのサーバーの結果は $Output と一緒に表示されます。それを Sort-Object し、次に Select-Object -First 10 できます。
Invoke-Command は、結果がどこから来たのか示す PsComputerName プロパティで結果を装飾します。VM がどこで実行されているかを知るためにこれを出力できます。
Script
スクリプトを次に示します。
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Iops {
Param (
$RawValue
)
$i = 0 ; $Labels = (" ", "K", "M", "B", "T") # Thousands, millions, billions, trillions...
Do { if($RawValue -Gt 1000){$RawValue /= 1000 ; $i++ } } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$IopsTotal = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Total"
$IopsRead = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Read"
$IopsWrite = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Write"
[PsCustomObject]@{
"VM" = $_.Name
"IopsTotal" = Format-Iops $IopsTotal.Value
"IopsRead" = Format-Iops $IopsRead.Value
"IopsWrite" = Format-Iops $IopsWrite.Value
"RawIopsTotal" = $IopsTotal.Value # For sorting...
}
}
}
$Output | Sort-Object RawIopsTotal -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, IopsTotal, IopsRead, IopsWrite
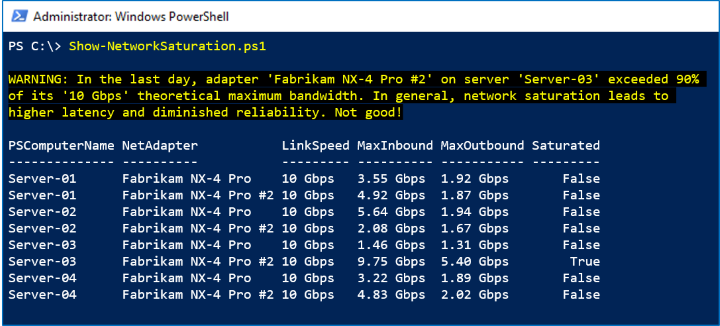
サンプル 4: 「25 ギグは新しい 10 ギグ」
このサンプルでは、NetAdapter.Bandwidth.Total 期間の LastDay 系列を使用して、理論上の最大帯域幅の >90% として定義されたネットワーク飽和の兆候を探します。 クラスター内のすべてのネットワーク アダプターについて、直近 1 日で観測された最も高い帯域幅使用量と、指定されたリンク速度を比較します。
Screenshot
次のスクリーンショットでは、1 つの Fabrikam NX-4 Pro #2 が過去 1 日でピークに達しているのがわかります。
しくみ
すべてのサーバーで上から Invoke-Command に対してこの Get-NetAdapter 手順を繰り返し、Get-ClusterPerf にパイプします。 その後、関連する 2 つのプロパティを取得します。"10 Gbps" のような LinkSpeed 文字列と、10000000000 のような生の Speed 整数です。
Measure-Object を使用して、直近 1 日の平均とピークを取得し (リマインダー: LastDay 期間内の各測定値は 5 分を表します)、1 バイトあたり 8 ビットを乗算して同一条件での比較を取得します。
Note
Some vendors, like Chelsio, include remote-direct memory access (RDMA) activity in their Network Adapter performance counters, so it's included in the NetAdapter.Bandwidth.Total series. Mellanox など、他はそうではない場合があります。 ベンダーがそれを行っていない場合は、このスクリプトのお使いのバージョンに単に NetAdapter.Bandwidth.RDMA.Total 系列を追加してください。
Script
スクリプトを次に示します。
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-BitsPerSec {
Param (
$RawValue
)
$i = 0 ; $Labels = ("bps", "kbps", "Mbps", "Gbps", "Tbps", "Pbps") # Petabits, just in case!
Do { $RawValue /= 1000 ; $i++ } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-NetAdapter | ForEach-Object {
$Inbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Inbound" -TimeFrame "LastDay"
$Outbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Outbound" -TimeFrame "LastDay"
If ($Inbound -Or $Outbound) {
$InterfaceDescription = $_.InterfaceDescription
$LinkSpeed = $_.LinkSpeed
$MeasureInbound = $Inbound | Measure-Object -Property Value -Maximum
$MaxInbound = $MeasureInbound.Maximum * 8 # Multiply to bits/sec
$MeasureOutbound = $Outbound | Measure-Object -Property Value -Maximum
$MaxOutbound = $MeasureOutbound.Maximum * 8 # Multiply to bits/sec
$Saturated = $False
# Speed property is Int, e.g. 10000000000
If (($MaxInbound -Gt (0.90 * $_.Speed)) -Or ($MaxOutbound -Gt (0.90 * $_.Speed))) {
$Saturated = $True
Write-Warning "In the last day, adapter '$InterfaceDescription' on server '$Env:ComputerName' exceeded 90% of its '$LinkSpeed' theoretical maximum bandwidth. In general, network saturation leads to higher latency and diminished reliability. Not good!"
}
[PsCustomObject]@{
"NetAdapter" = $InterfaceDescription
"LinkSpeed" = $LinkSpeed
"MaxInbound" = Format-BitsPerSec $MaxInbound
"MaxOutbound" = Format-BitsPerSec $MaxOutbound
"Saturated" = $Saturated
}
}
}
}
$Output | Sort-Object PsComputerName, InterfaceDescription | Format-Table PsComputerName, NetAdapter, LinkSpeed, MaxInbound, MaxOutbound, Saturated
サンプル 5: ストレージを再びトレンドに!
マクロの傾向を確認するために、パフォーマンス履歴は最大 1 年間保持されます。 このサンプルでは、Volume.Size.Available 期間の LastYear 系列を使用して、ストレージが満たされる速度を判断し、いつ一杯になるかを見積もっています。
Screenshot
In the screenshot below, we see the Backup volume is adding about 15 GB per day:
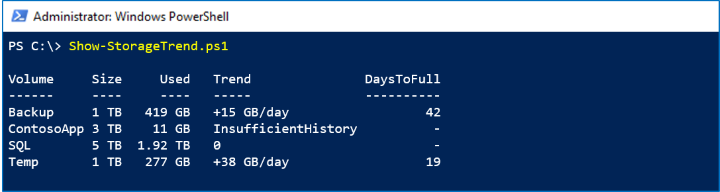
この速度では、あと 42 日以内に最大容量に達します。
しくみ
LastYear 時間枠には、1 日に 1 つのデータ ポイントがあります。 傾向線を引くには厳密には 2 点のみ必要ですが、実際には 14 日などもっと多くを必要とする方が良いでしょう。 We use Select-Object -Last 14 to set up an array of (x, y) points, for x in the range [1, 14]. これらの点を使用して、単純な線形最小二乗アルゴリズムを実装し、最適な $A の線をパラメーター化する $B と を見つけます。
ボリュームの SizeRemaining プロパティを、傾向 (傾き $A) で除算すると、現在のストレージ増加率で、ボリュームが一杯になるまでの日数を大まかに見積もりできます。
Format-Bytes、Format-Trend、および Format-Days ヘルパー関数は、出力を美しくします。
Important
この推定値は線形であり、直近 14 日の測定値にのみ基づいています。 より洗練された正確な手法があります。 ストレージの拡張に投資するかどうかを判断するために、このスクリプトだけに依存せず、適切な判断をしてください。 ここでは、教育目的でのみ提供されています。
Script
スクリプトを次に示します。
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { $RawValue /= 1024 ; $i++ } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Function Format-Trend {
Param (
$RawValue
)
If ($RawValue -Eq 0) {
"0"
}
Else {
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + $(Format-Bytes ([Math]::Abs($RawValue))) + "/day"
}
}
Function Format-Days {
Param (
$RawValue
)
[Math]::Round($RawValue)
}
$CSV = Get-Volume | Where-Object FileSystem -Like "*CSV*"
$Output = $CSV | ForEach-Object {
$N = 14 # Require 14 days of history
$Data = $_ | Get-ClusterPerf -VolumeSeriesName "Volume.Size.Available" -TimeFrame "LastYear" | Sort-Object Time | Select-Object -Last $N
If ($Data.Length -Ge $N) {
# Last N days as (x, y) points
$PointsXY = @()
1..$N | ForEach-Object {
$PointsXY += [PsCustomObject]@{ "X" = $_ ; "Y" = $Data[$_-1].Value }
}
# Linear (y = ax + b) least squares algorithm
$MeanX = ($PointsXY | Measure-Object -Property X -Average).Average
$MeanY = ($PointsXY | Measure-Object -Property Y -Average).Average
$XX = $PointsXY | ForEach-Object { $_.X * $_.X }
$XY = $PointsXY | ForEach-Object { $_.X * $_.Y }
$SSXX = ($XX | Measure-Object -Sum).Sum - $N * $MeanX * $MeanX
$SSXY = ($XY | Measure-Object -Sum).Sum - $N * $MeanX * $MeanY
$A = ($SSXY / $SSXX)
$B = ($MeanY - $A * $MeanX)
$RawTrend = -$A # Flip to get daily increase in Used (vs decrease in Remaining)
$Trend = Format-Trend $RawTrend
If ($RawTrend -Gt 0) {
$DaysToFull = Format-Days ($_.SizeRemaining / $RawTrend)
}
Else {
$DaysToFull = "-"
}
}
Else {
$Trend = "InsufficientHistory"
$DaysToFull = "-"
}
[PsCustomObject]@{
"Volume" = $_.FileSystemLabel
"Size" = Format-Bytes ($_.Size)
"Used" = Format-Bytes ($_.Size - $_.SizeRemaining)
"Trend" = $Trend
"DaysToFull" = $DaysToFull
}
}
$Output | Format-Table
サンプル 6: メモリ ホグ。実行できますが、隠すことはできません
パフォーマンス履歴はクラスター全体に対して一元的に収集されて保存されるため、VM がホスト間を何回移動しても、さまざまなコンピューターからのデータを結合する必要はありません。 このサンプルでは、VM.Memory.Assigned 期間の LastMonth 系列を使用して、過去 35 日間にメモリを最も多く消費した仮想マシンを特定します。
Screenshot
次のスクリーンショットでは、先月のメモリ使用量別で上位 10 台の仮想マシンが表示されています。
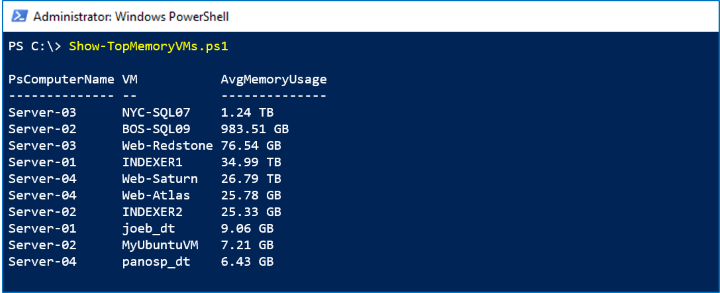
しくみ
上記で紹介した Invoke-Command 手順を、すべてのサーバーの Get-VM に繰り返します。
Measure-Object -Average を使用して、すべての VM の月間平均を取得し、次に Sort-Object の後に Select-Object -First 10 を使用してリーダーボードを取得します。 (Or maybe it's our Most Wanted list?)
Script
スクリプトを次に示します。
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { if( $RawValue -Gt 1024 ){ $RawValue /= 1024 ; $i++ } } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$Data = $_ | Get-ClusterPerf -VMSeriesName "VM.Memory.Assigned" -TimeFrame "LastMonth"
If ($Data) {
$AvgMemoryUsage = ($Data | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"VM" = $_.Name
"AvgMemoryUsage" = Format-Bytes $AvgMemoryUsage.Value
"RawAvgMemoryUsage" = $AvgMemoryUsage.Value # For sorting...
}
}
}
}
$Output | Sort-Object RawAvgMemoryUsage -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, AvgMemoryUsage
That's it! これらのサンプルが作業を始めるために役に立つことを願っています。 記憶域スペース ダイレクト パフォーマンスの履歴と、スクリプトに対応した強力な Get-ClusterPerf コマンドレットを使用すれば、質問と回答ができるようになります。 – Windows Server 2019 インフラストラクチャを管理および監視する際の複雑な質問。