APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure Machine Learning では、カスタム コンテナーを使用してモデルをオンライン エンドポイントにデプロイできます。 カスタム コンテナーデプロイでは、Azure Machine Learning で使用される既定の Python Flask サーバー以外の Web サーバーを使用できます。
カスタム デプロイを使用すると、次のことができます。
- TensorFlow Serving (TF Serving)、TorchServe、Triton Inference Server、Plumber R パッケージ、Azure Machine Learning 推論の最小イメージなど、さまざまなツールとテクノロジを使用します。
- 引き続き、Azure Machine Learning が提供する組み込みの監視、スケーリング、アラート、認証を活用します。
この記事では、TF サービス イメージを使用して TensorFlow モデルを提供する方法について説明します。
Prerequisites
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「ワークスペースの 作成」を参照してください。
Azure CLI と
ml拡張機能または Azure Machine Learning Python SDK v2:Azure CLI と
ml拡張機能をインストールするには、 CLI のインストールと設定 (v2) に関するページを参照してください。この記事の例では、Bash シェルまたは互換性のあるシェルを使用することを前提としています。 たとえば、Linux システム上のシェルや Linux 用 Windows サブシステムを使用できます。
ワークスペースを含み、自分またはサービス プリンシパルが共同作成者アクセス権を持つ Azure リソース グループ。 ワークスペースを 作成してワークスペース を構成する手順を使用する場合は、この要件を満たします。
Docker Engine, installed and running locally. This prerequisite is highly recommended. モデルをローカルにデプロイするために必要であり、デバッグに役立ちます。
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Azure CLI スクリプト | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Azure Machine Learning 推論の最小イメージを拡張することで、複数のモデルを 1 つのデプロイにデプロイします。 |
| minimal/single-model | deploy-custom-container-minimal-single-model | Azure Machine Learning 推論の最小イメージを拡張して、1 つのモデルをデプロイします。 |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | 異なる Python 要件を持つ 2 つの MLFlow モデルを、1 つのエンドポイントの背後にある 2 つの個別のデプロイにデプロイします。 Azure Machine Learning 推論の最小イメージを使用します。 |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | 3 つの回帰モデルを 1 つのエンドポイントにデプロイします。 Plumber R パッケージを使用します。 |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | TF Serving カスタム コンテナーを使用して、Half Plus Two モデルをデプロイします。 標準モデル登録プロセスを使用します。 |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | イメージに統合されたモデルと共に TF Serving カスタム コンテナーを使用して、Half Plus 2 モデルをデプロイします。 |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | TorchServe カスタム コンテナーを使用して 1 つのモデルをデプロイします。 |
| triton/single-model | deploy-custom-container-triton-single-model | カスタム コンテナーを使用して Triton モデルをデプロイします。 |
この記事では、tfserving/half-plus-2 の例を使用する方法について説明します。
Warning
Microsoft サポート チームは、カスタム イメージによって発生する問題のトラブルシューティングを支援できない場合があります。 問題が発生した場合は、既定のイメージまたは Microsoft が提供するイメージの 1 つを使用して、問題がイメージに固有であるかどうかを確認するように求められる場合があります。
ソース コードをダウンロードする
The steps in this article use code samples from the azureml-examples repository. 次のコマンドを使用して、リポジトリをクローンします。
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
環境変数を初期化する
TensorFlow モデルを使用するには、いくつかの環境変数が必要です。 次のコマンドを実行して、これらの変数を定義します。
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
TensorFlow モデルをダウンロードする
入力値を 2 で除算し、結果に 2 を追加するモデルをダウンロードして解凍します。
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
TF サービス イメージをローカルでテストする
Docker を使用して、テスト用にイメージをローカルで実行します。
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
イメージに対してライブネス要求とスコアリング要求を送信する
コンテナー内のプロセスが実行されていることを確認するライブネス要求を送信します。 応答状態コード 200 OK が表示されます。
curl -v http://localhost:8501/v1/models/$MODEL_NAME
スコアリング要求を送信して、ラベル付けされていないデータに関する予測を取得できることを確認します。
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
イメージを停止する
ローカルでのテストが完了したら、イメージを停止します。
docker stop tfserving-test
オンライン エンドポイントを Azure にデプロイする
オンライン エンドポイントを Azure にデプロイするには、次のセクションの手順を実行します。
エンドポイントとデプロイ用の YAML ファイルを作成する
YAML を使用してクラウド デプロイを構成できます。 たとえば、エンドポイントを構成するには、次の行を含む tfserving-endpoint.yml という名前の YAML ファイルを作成できます。
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
デプロイを構成するには、次の行を含む tfserving-deployment.yml という名前の YAML ファイルを作成します。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
以降のセクションでは、YAML パラメーターと Python パラメーターに関する重要な概念について説明します。
Base image
YAML の environment セクション、または Python の Environment コンストラクターでは、基本イメージをパラメーターとして指定します。 この例では、docker.io/tensorflow/serving:latest値としてimageを使用します。
コンテナーを検査すると、このサーバーが ENTRYPOINT コマンドを使用してエントリ ポイント スクリプトを開始していることがわかります。 このスクリプトは、 MODEL_BASE_PATH や MODEL_NAMEなどの環境変数を受け取り、 8501などのポートを公開します。 これらの詳細はすべてこのサーバーに関連しており、この情報を使用してデプロイを定義する方法を決定できます。 たとえば、展開定義で MODEL_BASE_PATH 環境変数と MODEL_NAME 環境変数を設定した場合、TF Serving はこれらの値を使用してサーバーを開始します。 同様に、展開定義で各ルートのポートを 8501 に設定すると、それらのルートへのユーザー要求が TF サービス サーバーに正しくルーティングされます。
この例は、TF サービス ケースに基づいています。 ただし、稼働状態を維持し、liveness、readiness、スコアリング ルートに移動する要求に応答する、任意のコンテナーを使用できます。 Dockerfile を形成してコンテナーを作成する方法については、他の例を参照してください。 一部のサーバーでは、CMD命令の代わりにENTRYPOINT命令が使用されます。
inference_config パラメーター
environment セクションまたは Environment クラスでは、inference_configはパラメーターです。 これは、3 種類のルート (liveness、readiness、スコアリング ルート) のポートとパスを指定します。 マネージド オンライン エンドポイントで独自のコンテナーを実行する場合は、 inference_config パラメーターが必要です。
readiness ルートと liveness ルート
一部の API サーバーには、サーバーの状態を確認する方法が用意されています。 状態を確認するために指定できるルートには、次の 2 種類があります。
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
機械学習推論のコンテキストでは、モデルを読み込む前に、サーバーが状態コード 200 OK でライブネス要求に応答する場合があります。 サーバーは、モデルをメモリに読み込んだ後にのみ、状態コード 200 OK で準備要求に応答する場合があります。
liveness および readiness probe の詳細については、liveness、readiness、startup probe の構成を参照してください。
選択した API サーバーによって、ライブ性と準備のルートが決まります。 コンテナーをローカルでテストするときは、前の手順でそのサーバーを識別します。 この記事では、TF Serving はライブネス ルートのみを定義するため、デプロイ例では、ライブネス ルートと準備ルートに同じパスを使用します。 ルートを定義するその他の方法については、他の例を参照してください。
Scoring routes
使用する API サーバーは、作業するペイロードを受け取る方法を提供します。 機械学習推論のコンテキストでは、サーバーは特定のルートを介して入力データを受信します。 前の手順でコンテナーをローカルでテストするときに、API サーバーのルートを特定します。 作成するデプロイを定義するときに、そのルートをスコアリング ルートとして指定します。
デプロイが正常に作成されると、エンドポイントの scoring_uri パラメーターも更新されます。 この事実を確認するには、次のコマンドを実行します: az ml online-endpoint show -n <endpoint-name> --query scoring_uri。
マウントされたモデルを見つける
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. モデルがマウントされると、新しい Docker イメージを作成しなくても、新しいバージョンのモデルをデプロイできます。 By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
たとえば、次の設定を考えてみましょう。
- ローカル コンピューターにおける /azureml-examples/cli/endpoints/online/custom-container のディレクトリ構造
- モデル名は
half_plus_twoです

tfserving-deployment.yml ファイルの model セクションに次の行が含まれているとします。 このセクションでは、 name 値は、Azure Machine Learning にモデルを登録するために使用する名前を参照します。
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
この場合、デプロイを作成すると、モデルは /var/azureml-app/azureml-models/tfserving-mounted/1 フォルダーの下にあります。
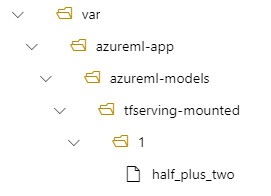
必要に応じて、 model_mount_path 値を構成できます。 この設定を調整することで、モデルをマウントするパスを変更できます。
Important
model_mount_path値は、Linux の有効な絶対パスである必要があります (コンテナー イメージのゲスト OS 内)。
Important
model_mount_path は BYOC (Bring Your Own Container) シナリオでのみ使用できます。 BYOC シナリオでは、オンライン 展開で使用される環境に inference_config パラメーター が構成されている必要があります。 Azure ML CLI または Python SDK を使用して、環境の作成時 inference_config パラメーターを指定できます。 現在、Studio UI ではこのパラメーターの指定はサポートされていません。
model_mount_pathの値を変更する場合は、MODEL_BASE_PATH環境変数も更新する必要があります。 ベース パスが見つからないというエラーが原因でデプロイが失敗しないように、 MODEL_BASE_PATH を model_mount_path と同じ値に設定します。
たとえば、tfserving-deployment.yml ファイルに model_mount_path パラメーターを追加できます。 そのファイルの MODEL_BASE_PATH 値を更新することもできます。
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
デプロイでは、モデルは /var/tfserving-model-mount/tfserving-mounted/1 にあります。 azureml-app/azureml-models ではなく、ご自分で指定したマウント パスの下に配置されます。
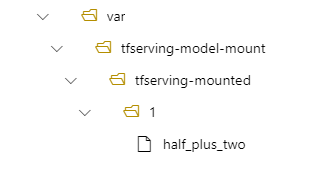
エンドポイントとデプロイを作成する
YAML ファイルを作成したら、次のコマンドを使用してエンドポイントを作成します。
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
次のコマンドを使用してデプロイを作成します。 この手順は数分実行される場合があります。
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
エンドポイントを呼び出す
デプロイが完了したら、デプロイされたエンドポイントにスコアリング要求を行います。
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
エンティティを削除する
エンドポイントが不要になった場合は、次のコマンドを実行して削除します。
az ml online-endpoint delete --name tfserving-endpoint