この記事では、取得拡張世代 (RAG) と、運用環境に対応した RAG ソリューションを構築するために開発者が必要とする内容について説明します。
ビジネス向けの最も生成的な AI ユース ケースの 1 つである "データを介したチャット" アプリを構築する 2 つの方法については、「 RAG を使用して LLM を拡張する」または「微調整」を参照してください。
次の図は、RAG の主な手順を示しています。
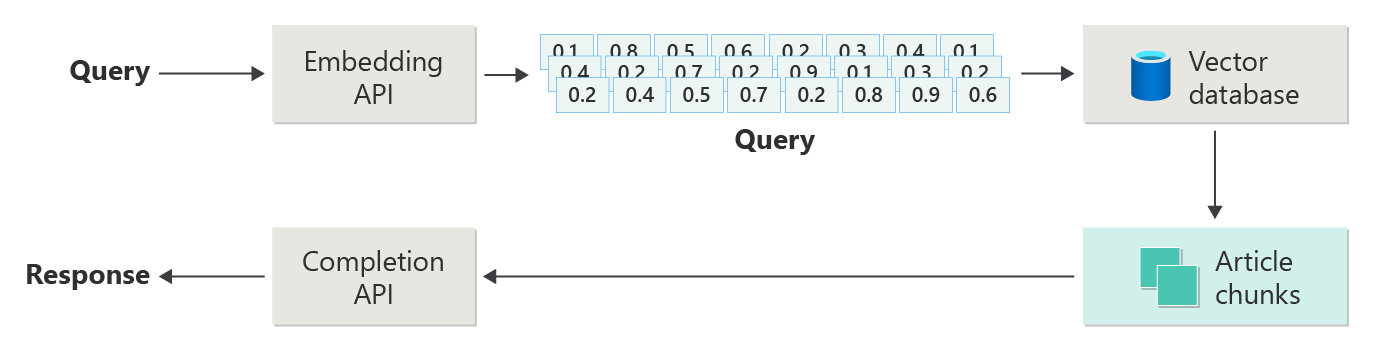
このプロセスは 単純な RAG と呼ばれます。 RAG ベースのチャット システムの基本的な部分と役割を理解するのに役立ちます。
実際の RAG システムでは、アーティクル、クエリ、応答を処理するために、より多くの前処理と後処理が必要になります。 次の図は、 高度な RAG と呼ばれる、より現実的なセットアップを示しています。

この記事では、実際の RAG ベースのチャット システムの主なフェーズを理解するための簡単なフレームワークを提供します。
- インジェスト フェーズ
- 推論パイプライン フェーズ
- 評価フェーズ
インジェスト
インジェストとは、組織のドキュメントを保存して、ユーザーの回答をすばやく見つけられるようにすることです。 主な課題は、各質問に最も一致するドキュメントの部分を見つけて使用することです。 ほとんどのシステムでは、ベクトル埋め込みとコサイン類似性検索を使用して、質問をコンテンツに一致させます。 コンテンツ タイプ (パターンや形式など) を理解し、ベクター データベースでデータを適切に整理すると、より良い結果が得られます。
インジェストを設定するときは、次の手順に注目してください。
- コンテンツの前処理と抽出
- チャンク戦略
- チャンク編成
- 戦略を更新する
コンテンツの前処理と抽出
インジェスト フェーズの最初の手順は、ドキュメントのコンテンツを前処理して抽出することです。 この手順は、テキストがクリーンで構造化され、インデックス作成と取得の準備ができていることを保証するため、非常に重要です。
クリーンで正確なコンテンツにより、RAG ベースのチャット システムの動作が向上します。 まず、インデックスを作成するドキュメントの図形とスタイルを確認します。 ドキュメントなど、セット パターンに従っていますか。 そうでない場合、これらのドキュメントはどのような質問に回答できますか?
少なくとも、インジェスト パイプラインを次の内容に設定します。
- テキスト形式を標準化する
- 特殊文字を処理する
- 関連のないコンテンツまたは古いコンテンツを削除する
- さまざまなバージョンのコンテンツを追跡する
- タブ、画像、またはテーブルを使用してコンテンツを処理する
- メタデータを抽出する
この情報の一部 (メタデータなど) は、ベクター データベース内のドキュメントと共に保持すると、取得および評価中に役立ちます。 テキスト チャンクと組み合わせて、チャンクのベクター埋め込みを改善することもできます。
チャンク戦略
開発者は、大きなドキュメントをより小さなチャンクに分割する方法を決定します。 チャンクは、最も関連性の高いコンテンツを LLM に送信するのに役立ちます。これにより、ユーザーの質問に対する回答が向上します。 また、チャンクを取得した後のチャンクの使用方法についても考えてください。 一般的な業界の方法を試し、組織内のチャンク戦略をテストします。
チャンクする場合は、次のことを考慮してください。
- チャンク サイズの最適化: セクション、段落、文ごとに、最適なチャンク サイズとその分割方法を選択します。
- 重なり合うウィンドウ チャンクとスライディング ウィンドウ チャンク: チャンクを個別にするか、重複するかを決定します。 スライディング ウィンドウアプローチを使用することもできます。
- Small2Big: 文で分割する場合は、近くの文や完全な段落を見つけられるようにコンテンツを整理します。 この追加のコンテキストを LLM に与えることは、より良い回答を得るのに役立ちます。 詳細については、次のセクションを参照してください。
チャンク編成
RAG システムでは、ベクター データベースでデータを整理する方法により、適切な情報を簡単かつ迅速に見つけることができます。 インデックスと検索を設定する方法を次に示します。
- 階層インデックス: インデックスのレイヤーを使用します。 最上位の概要インデックスでは、可能性の高いチャンクの小さなセットがすぐに見つかります。 第 2 レベルのインデックスは、正確なデータを指します。 この設定では、詳細を確認する前にオプションを絞り込んで検索を高速化します。
- 特殊なインデックス: データに合ったインデックスを選択します。 たとえば、引用ネットワークやナレッジ グラフのように、チャンクが相互に接続する場合は、グラフベースのインデックスを使用します。 データがテーブル内にある場合はリレーショナル データベースを使用し、SQL クエリでフィルター処理します。
- ハイブリッド インデックス: さまざまなインデックス作成方法を組み合わせます。 たとえば、最初に概要インデックスを使用し、次にグラフベースのインデックスを使用して、チャンク間の接続を探索します。
配置の最適化
取得したチャンクを、回答する質問の種類と一致させることで、より関連性が高く正確になります。 1 つの方法は、最適な質問を示す各チャンクのサンプル質問を作成する方法です。 この方法は、いくつかの方法で役立ちます。
- 照合の改善: 検索中に、システムはユーザーの質問をこれらのサンプルの質問と比較して最適なチャンクを見つけます。 この手法により、結果の関連性が向上します。
- 機械学習モデルのトレーニング データ: これらの質問とチャンクのペアは、RAG システムで機械学習モデルをトレーニングするのに役立ちます。 モデルでは、どのチャンクがどの種類の質問に回答するかを学習します。
- 直接クエリ処理: ユーザーの質問がサンプルの質問と一致する場合、システムは適切なチャンクをすばやく見つけて使用できるため、応答が高速化されます。
各チャンクのサンプル質問は、取得アルゴリズムをガイドするラベルとして機能します。 検索の焦点が高くなり、コンテキストが認識されます。 この方法は、チャンクがさまざまなトピックや種類の情報をカバーする場合に適切に機能します。
更新方法
組織がドキュメントを頻繁に更新する場合は、取得元が常に最新の情報を検索できるように、データベースを最新の状態に保つ必要があります。 レトリバー コンポーネントは、ベクター データベースを検索して結果を返すシステムの一部です。 ベクター データベースを最新の状態に保つ方法を次に示します。
増分更新:
- 定期的な間隔: ドキュメントの変更頻度に基づいて、スケジュールに従って実行する更新を設定します (毎日または毎週など)。 このアクションにより、データベースが最新の状態に保たれた状態が維持されます。
- トリガーベースの更新: 誰かがドキュメントを追加または変更したときに自動更新を設定します。 システムは、影響を受ける部分のインデックスを再作成します。
部分更新:
- 選択的なインデックス再作成: 変更されたデータベースの部分のみを更新し、全体を更新する必要はありません。 この手法は、特に大規模なデータセットの場合に、時間とリソースを節約します。
- 差分エンコード: 古いドキュメントと新しいドキュメントの間の変更のみを格納します。これにより、処理するデータの量が減ります。
バージョン管理:
- スナップショット作成: ドキュメント セットのバージョンを異なる時間に保存します。 このアクションにより、必要に応じて以前のバージョンに戻ったり復元したりできます。
- ドキュメントのバージョン管理: バージョン管理システムを使用して、変更を追跡し、ドキュメントの履歴を保持します。
リアルタイム更新:
- ストリーム処理: ストリーム処理を使用して、ドキュメントの変更に合ってベクター データベースをリアルタイムで更新します。
- ライブ クエリ: ライブ クエリを使用して up-to-date の回答を取得します。場合によっては、ライブ データとキャッシュされた結果が混在して速度が向上します。
最適化手法:
- バッチ処理: 変更をグループ化し、それらを一緒に適用してリソースを節約し、オーバーヘッドを削減します。
-
ハイブリッド アプローチ: さまざまな戦略を組み合わせています。
- 小さな変更には増分更新を使用します。
- 重要な更新には、完全なインデックス再作成を使用します。
- データに対する大きな変更を追跡して文書化します。
ニーズに合った更新戦略またはミックスを選択します。 考える:
- ドキュメント コーパスのサイズ
- 更新頻度
- リアルタイム データのニーズ
- 使用可能なリソース
アプリケーションのこれらの要因を確認します。 各方法には、複雑さ、コスト、更新プログラムの表示速度にトレードオフがあります。
推論パイプライン
これで、アーティクルはチャンクされ、ベクター化され、ベクター データベースに格納されます。 次に、システムから最適な回答を得ることに重点を置きます。
正確で迅速な結果を得るには、次の重要な質問について考えてください。
- ユーザーの質問は明確であり、正しい答えを得る可能性がありますか?
- 質問は会社のルールを破りますか?
- システムがより良い一致を見つけるのに役立つ質問を書き直すことができますか?
- データベースからの結果は質問と一致しますか?
- 結果を LLM に送信する前に変更して、回答が関連していることを確認する必要がありますか?
- LLM の回答は、ユーザーの質問に完全に対処していますか?
- その答えは組織のルールに従っていますか?
推論パイプライン全体がリアルタイムで動作します。 前処理と後処理の手順を設定する正しい方法は 1 つもありません。 コード呼び出しと LLM 呼び出しの組み合わせを使用します。 最大のトレードオフの 1 つは、精度とコンプライアンスとコストと速度のバランスを取るということです。
推論パイプラインの各ステージの戦略を見てみましょう。
クエリの前処理手順
クエリの前処理は、ユーザーが質問を送信した直後に開始されます。

これらの手順は、ユーザーの質問がシステムに適合し、コサインの類似性または "最も近い隣人" 検索を使用して最適な記事チャンクを見つける準備ができていることを確認するのに役立ちます。
ポリシー チェック: ロジックを使用して、個人データ、不適切な言語、安全規則 ("脱獄" と呼ばれる) を破ろうとするなどの不要なコンテンツを特定して削除またはフラグを設定します。
クエリの書き換え: 必要に応じて質問を変更します。頭字語の展開、スラングの削除、または言い換えを行って、より大きなアイデア (ステップ バック プロンプト) に焦点を当てます。
ステップ バック プロンプトの特別なバージョンは 、架空のドキュメント埋め込み (HyDE) です。 HyDE には LLM が質問に回答し、その回答から埋め込みを行い、それを使用してベクター データベースを検索します。
サブクエリ
サブクエリは、長い質問や複雑な質問をより小さく簡単な質問に分割します。 システムは各小さな質問に回答し、その回答を組み合わせます。
たとえば、誰かが「誰が現代物理学、アルバート・アインシュタイン、ニールス・ブールにもっと重要な貢献をしたか」と尋ねた場合、それを次に分割できます。
- サブクエリ 1: "アルバート・アインシュタインは現代物理学に何を貢献しましたか?
- サブクエリ 2: "Niels Bohr は現代物理学に何を貢献しましたか?
答えは次のとおりです。
- アインシュタインの場合:相対性理論、光電効果、 E=mc^2。
- ボーアの場合:水素原子モデル、量子力学、および相補性の原理に取り組みます。
その後、フォローアップの質問をすることができます。
- サブクエリ 3: "アインシュタインの理論は現代の物理学をどのように変えるのか?
- サブクエリ 4: "ボーアの理論は現代の物理学をどのように変えるのか?
これらのフォローアップでは、次のような各科学者の効果を確認します。
- アインシュタインの仕事が宇宙論と量子理論の新しいアイデアにつながった方法
- ボーアの仕事が原子と量子力学を理解するのにどのように役立ったか
システムは回答を組み合わせて、元の質問に対する完全な回答を提供します。 この方法では、複雑な質問を明確で小さな部分に分割することで、回答が容易になります。
クエリ ルーター
コンテンツが複数のデータベースや検索システムに存在する場合があります。 このような場合は、クエリ ルーターを使用します。 クエリ ルーターは、各質問に答える最適なデータベースまたはインデックスを選択します。
クエリ ルーターは、ユーザーが質問した後、システムが回答を検索する前に機能します。
クエリ ルーターのしくみを次に示します。
- クエリ分析: LLM または別のツールが質問を調べて、必要な回答の種類を特定します。
- インデックスの選択: ルーターは、質問に合った 1 つ以上のインデックスを選択します。 一部のインデックスは事実に適しており、他のインデックスは意見や特別なトピックに適しています。
- クエリ ディスパッチ: ルーターは、選択したインデックスまたはインデックスに質問を送信します。
- 結果の集計: システムは、インデックスから回答を収集して結合します。
- 回答の生成: システムは、見つかった情報を使用して明確な回答を作成します。
次の場合は、異なるインデックスまたは検索エンジンを使用します。
- データ型の特殊化: 一部のインデックスは、ニュース、学術論文、医療や法的情報などの特殊なデータベースに焦点を当てています。
- クエリの種類の最適化: 単純なファクト (日付など) に対して高速なインデックスもあれば、複雑な質問や専門家の質問を処理するインデックスもあります。
- アルゴリズムの違い: 検索エンジンによって、ベクター検索、キーワード検索、高度なセマンティック検索など、さまざまな方法が使用されます。
たとえば、医療アドバイス システムでは、次のことがあります。
- 技術詳細に関する研究論文索引
- 実際の例のケース スタディ インデックス
- 基本的な質問の一般的な正常性インデックス
誰かが新薬の効果について尋ねた場合、ルータは研究論文のインデックスに質問を送信します。 一般的な症状に関する質問の場合は、単純な回答に一般的な正常性インデックスを使用します。
取得後の処理ステップ
取得後の処理は、システムがベクター データベース内のコンテンツ チャンクを検出した後に発生します。

次に、LLM に送信する前に、これらのチャンクが LLM プロンプトに役立つかどうかを確認します。
次の点に注意してください。
- 追加情報は、最も重要な詳細を隠すことができます。
- 無関係な情報は、答えを悪化させる可能性があります。
干し草の問題の針に注意してください:LLMは、多くの場合、中間よりもプロンプトの開始と終了に注意を払います。
また、LLM の最大コンテキスト ウィンドウと、長いプロンプトに必要なトークンの数 (特に大規模) を覚えておいてください。
これらの問題を処理するには、次のような手順で取得後処理パイプラインを使用します。
- 結果のフィルター処理: クエリに一致するチャンクのみを保持します。 LLM プロンプトをビルドするときに残りの部分を無視します。
- 再ランク付け: 最も関連性の高いチャンクをプロンプトの先頭と末尾に配置します。
- プロンプト圧縮: 小さく安価なモデルを使用して、チャンクを要約して 1 つのプロンプトに結合してから LLM に送信します。
完了後の処理ステップ
完了後の処理は、ユーザーの質問の後に発生し、すべてのコンテンツ チャンクが LLM に移動します。

LLM が回答を出したら、その精度を確認します。 完了後の処理パイプラインには、次のものが含まれます。
- ファクト チェック: 事実であると主張する回答内のステートメントを探し、それが正しいかどうかを確認します。 ファクト チェックが失敗した場合は、LLM にもう一度確認するか、エラー メッセージを表示できます。
- ポリシー チェック: 回答にユーザーまたは組織の有害なコンテンツが含まれていないことを確認します。
評価
このようなシステムの評価は、通常の単体テストや統合テストを実行するよりも複雑です。 次の質問について考えてみましょう。
- ユーザーは回答に満足していますか?
- 回答は正確ですか?
- ユーザーフィードバックを収集する方法
- 収集できるデータに関する規則はありますか?
- 答えが間違っているときにシステムが取ったすべてのステップを見ることができますか?
- 根本原因分析のために詳細なログを保持していますか?
- 状況を悪化させずにシステムを更新するにはどうすればよいですか?
ユーザーからのフィードバックのキャプチャと操作
組織のプライバシー チームと協力して、クエリ セッションのフォレンジックと根本原因分析のためのフィードバック キャプチャ ツール、システム データ、ログ記録を設計します。
次の手順では、 評価パイプラインを構築します。 評価パイプラインを使用すると、フィードバックを簡単かつ迅速に確認し、AI が特定の回答を与えた理由を確認できます。 すべての応答を確認して、AI によって生成された方法、適切なコンテンツ チャンクが使用されたかどうか、およびドキュメントがどのように分割されたかを確認します。
また、結果を改善できる追加の前処理または後処理の手順を探します。 このクローズ レビューでは、特にユーザーの質問に関する適切なドキュメントが存在しない場合に、コンテンツのギャップが見つかることがよくあります。
これらのタスクを大規模に処理するには、評価パイプラインが必要です。 優れたパイプラインでは、カスタム ツールを使用して回答の品質を測定します。 これは、AI が特定の回答を与えた理由、使用されたドキュメント、および推論パイプラインがどれだけうまく機能したかを確認するのに役立ちます。
ゴールデン データセット
RAG チャット システムの動作を確認する 1 つの方法は、ゴールデン データセットを使用することです。 ゴールデン データセットは、承認された回答、役に立つメタデータ (トピックや質問の種類など)、ソース ドキュメントへのリンク、ユーザーが同じことを尋ねるさまざまな方法を含む一連の質問です。
ゴールデン データセットには、"ベスト ケース シナリオ" が表示されます。開発者はこれを使用して、システムの動作を確認し、新しい機能や更新プログラムを追加するときにテストを実行します。
損害の評価
損害モデリングは、製品のリスクの可能性を特定し、それらを減らす方法を計画するのに役立ちます。
損害評価ツールには、次の重要な機能が含まれている必要があります。
- 利害関係者の識別: 直接ユーザー、間接的に影響を受けたユーザー、将来の世代、さらには環境など、テクノロジの影響を受けるすべてのユーザーを一覧表示してグループ化するのに役立ちます。
- 損害のカテゴリと説明: プライバシーの喪失、感情的な苦痛、経済的損害など、考えられる損害を一覧表示します。 例をガイドし、予期される問題と予期しない問題の両方について考えるのに役立ちます。
- 重大度と確率の評価: 各損害の深刻度と可能性を判断するのに役立ちます。そのため、最初に修正する内容を決定できます。 データを使用して選択をサポートできます。
- 軽減策: システム設計の変更、セーフガードの追加、その他のテクノロジの使用など、リスクを軽減する方法を提案します。
- フィードバック メカニズム: 関係者からのフィードバックを収集して、詳細を確認しながらプロセスを改善し続けることができます。
- ドキュメントとレポート: 見つけた内容と、リスクを軽減するために行ったことを示すレポートを簡単に作成できます。
これらの機能は、リスクを見つけて修正するのに役立ちます。また、最初から考えられるすべての影響について考えることで、より倫理的で責任ある AI を構築するのにも役立ちます。
詳細については、次の記事を参照してください。
セーフガードのテストと検証
レッド チーミング は重要です。つまり、攻撃者のように行動して、システム内の弱点を見つけることです。 この手順は、脱獄を停止するために特に重要です。 責任ある AI のレッド チーミングの計画と管理に関するヒントについては、 大規模言語モデル (LLM) とそのアプリケーションのレッド チーミングの計画を参照してください。
開発者は、さまざまなシナリオで RAG システムセーフガードをテストして、動作することを確認する必要があります。 この手順により、システムが強化され、倫理的な基準とルールに従って応答を微調整することもできます。
アプリケーション設計に関する最終的な考慮事項
アプリの設計に役立つ、この記事で覚えておく必要がある重要な点を次に示します。
- 生成 AI の予測不能性
- ユーザー プロンプトの変更とその時間とコストへの影響
- パフォーマンスを向上させる並列 LLM 要求
生成 AI アプリを構築するには、「 Python 用の独自のデータ サンプルを使用してチャットを開始する」を参照してください。 このチュートリアルは、