この記事では、プロビジョニングされたスループット Foundation Model API を使用してモデルをデプロイする方法について説明します。 Databricks では、運用環境のワークロードに対してプロビジョニングされたスループットが推奨され、パフォーマンスが保証された基盤モデルの推論が最適化されています。
プロビジョニングされたスループットとは
Databricks でエンドポイントを提供するプロビジョニング済みスループット モデルを作成する場合は、提供する基盤モデルに一貫したスループットを確保するために、専用の推論容量を割り当てます。 基盤モデルを提供するモデル サービス エンドポイントは、 モデル ユニット のチャンクでプロビジョニングできます (レガシ モデル エンドポイントは、 1 秒あたりのバンドあたりのトークンに基づいてプロビジョニングされます)。 割り当てるモデル ユニットの数により、運用 GenAI アプリケーションを確実にサポートするために必要なスループットを正確に購入できます。
- 「独自の LLM エンドポイント ベンチマークの実施」を参照してください
- プロビジョニングされたスループット エンドポイントでサポートされているモデル アーキテクチャの一覧については、「 Mosaic AI Model Serving でサポートされている基礎モデル」を参照してください。
プロビジョニング済みのスループットモデルユニット
モデル ユニットは、エンドポイントが 1 分あたりに処理できる作業量を決定するスループットの単位です。 新しいプロビジョニング済みスループット エンドポイントを作成する場合は、提供される各モデルに対してプロビジョニングするモデル ユニットの数を指定します。
エンドポイントへの各要求を処理するために必要な作業量は、入力と生成された出力の両方のサイズによって異なります。 入力トークンと出力トークンの数が増えると、要求の処理に必要な作業量も増加します。 出力トークンの生成は、入力トークンの処理よりもリソースを大量に消費します。 各要求に必要な作業は、入力トークンまたは出力トークンの数が増えるにつれて非線形的に増加します。つまり、エンドポイントが処理できるモデル ユニットの量は次のとおりです。
- 一度に複数の小さな要求 。
- 容量が不足する前に、長いコンテキスト要求の数が減ります。
さらに具体的な例として、3500 個の入力トークンと 300 個の出力トークンを含む中規模のワークロードの場合、特定の数のモデル ユニットについて、1 秒あたりのスループットあたりのトークンを見積もることができます。
| モデル | モデル単位 | 1 秒あたりの推定トークン数 |
|---|---|---|
| Llama 4 Maverick | 50 | 3250 |
必要条件
の要件を参照してください。 微調整された基盤モデルのデプロイについては、「微調整された基盤モデルをデプロイする」を参照してください。
[推奨]Unity カタログから基盤モデルをデプロイする
重要
この機能はパブリック プレビュー段階にあります。
Databricks では、Unity カタログにプレインストールされている基本モデルを使用することをお勧めします。 これらのモデルは、スキーマ system (ai) のカタログ system.ai にあります。
基盤モデルをデプロイするには:
- カタログ エクスプローラーで
system.aiに移動します。 - デプロイするモデルの名前をクリックします。
- モデル ページで、[このモデルを提供する] ボタンをクリックします。
- [サービス エンドポイントの作成] ページが表示されます。 「UIを使用してプロビジョニングされたスループット エンドポイントを作成する」を参照してください。
注
Unity カタログの system.ai から Meta Llama モデルをデプロイするには、該当する Instruct バージョンを選択する必要があります。 Meta Llama モデルの基本バージョンは、Unity カタログの system.ai からのデプロイではサポートされていません。
Databricksでホストされている FoundationモデルおよびMeta Llamaモデルのバリアントを参照してください。
Databricks Marketplace から基盤モデルをデプロイする
または、Databricks Marketplaceから Unity カタログに基本モデルをインストールすることもできます。
モデル ファミリを検索し、モデル ページから [アクセス の取得] 選択し、ログイン資格情報を指定してモデルを Unity カタログにインストールできます。
モデルが Unity カタログにインストールされたら、サービス UI を使用してモデル サービス エンドポイントを作成できます。
微調整された基盤モデルをデプロイする
system.ai スキーマでモデルを使用できない場合、または Databricks Marketplace からモデルをインストールできない場合は、Unity カタログにログを記録することで、微調整された基盤モデルをデプロイできます。 このセクションと以降のセクションでは、MLflow モデルを Unity カタログに記録し、UI または REST API を使用してプロビジョニングされたスループット エンドポイントを作成するようにコードを設定する方法について説明します。
サポートされている Meta Llama 3.1、3.2、3.3 の微調整されたモデルとそのリージョンの可用性については、 Databricks でホストされている Foundation モデルを参照してください。
必要条件
- 微調整された基盤モデルのデプロイは、MLflow 2.11 以降でのみサポートされます。 Databricks Runtime 15.0 ML 以降では、互換性のある MLflow バージョンがプレインストールされます。
- Databricks では、大規模なモデルのアップロードとダウンロードを高速化するために、Unity カタログでモデルを使用することをお勧めします。
カタログ、スキーマ、モデル名を定義する
微調整された基盤モデルをデプロイするには、ターゲットの Unity カタログ カタログ、スキーマ、および選択したモデル名を定義します。
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
モデルをログに記録する
モデル エンドポイントのプロビジョニング済みスループットを有効にするには、MLflow transformers フレーバーを使用してモデルをログに記録し、次のオプションから適切なモデルの種類のインターフェイスで task 引数を指定する必要があります。
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
これらの引数は、モデル サービス エンドポイントに使用される API 署名を指定します。 これらのタスクと対応する入出力スキーマの詳細については、MLflow ドキュメント を参照してください。
MLflow を使用してログに記録されたテキスト補完言語モデルをログに記録する方法の例を次に示します。
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.3-70B-Instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.3-70B-Instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
注
2.12 より前の MLflow を使用している場合は、代わりに同じ metadata 関数 mlflow.transformer.log_model() パラメーター内でタスクを指定する必要があります。
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
プロビジョニングされたスループットでは、ベースおよび大規模な GTE 埋め込みモデルのどちらもサポートします。 プロビジョニングされたスループットで提供できるように、モデル Alibaba-NLP/gte-large-en-v1.5 をログに記録する方法の例を次に示します。
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
このモデルが Unity Catalog 内にログされた後、「UI を使用してプロビジョニングされたスループット エンドポイントを作成する」に進んで、プロビジョニングされたスループットでモデル サービング エンドポイントを作成します。
UI を使用してプロビジョニング済みスループット エンドポイントを作成する
ログに記録されたモデルが Unity カタログに入ったら、次の手順でプロビジョニング済みスループット サービス エンドポイントを作成します。
- ワークスペースの サービス UI に移動します。
- [サービング エンドポイントの作成] を選択します。
- [エンティティ] フィールドで、Unity カタログからモデルを選択します。 対象モデルの場合、提供されるエンティティの UI には [プロビジョニング スループット] 画面が表示されます。
- [最大] ドロップダウンで、エンドポイントの 1 秒あたりの最大トークン スループットを構成できます。
- プロビジョニングされたスループット エンドポイントは自動的にスケーリングされるため、[ の変更] を選択して、エンドポイントがスケールダウンできる 1 秒あたりの最小トークン数を表示できます。
プロビジョニング済みスループット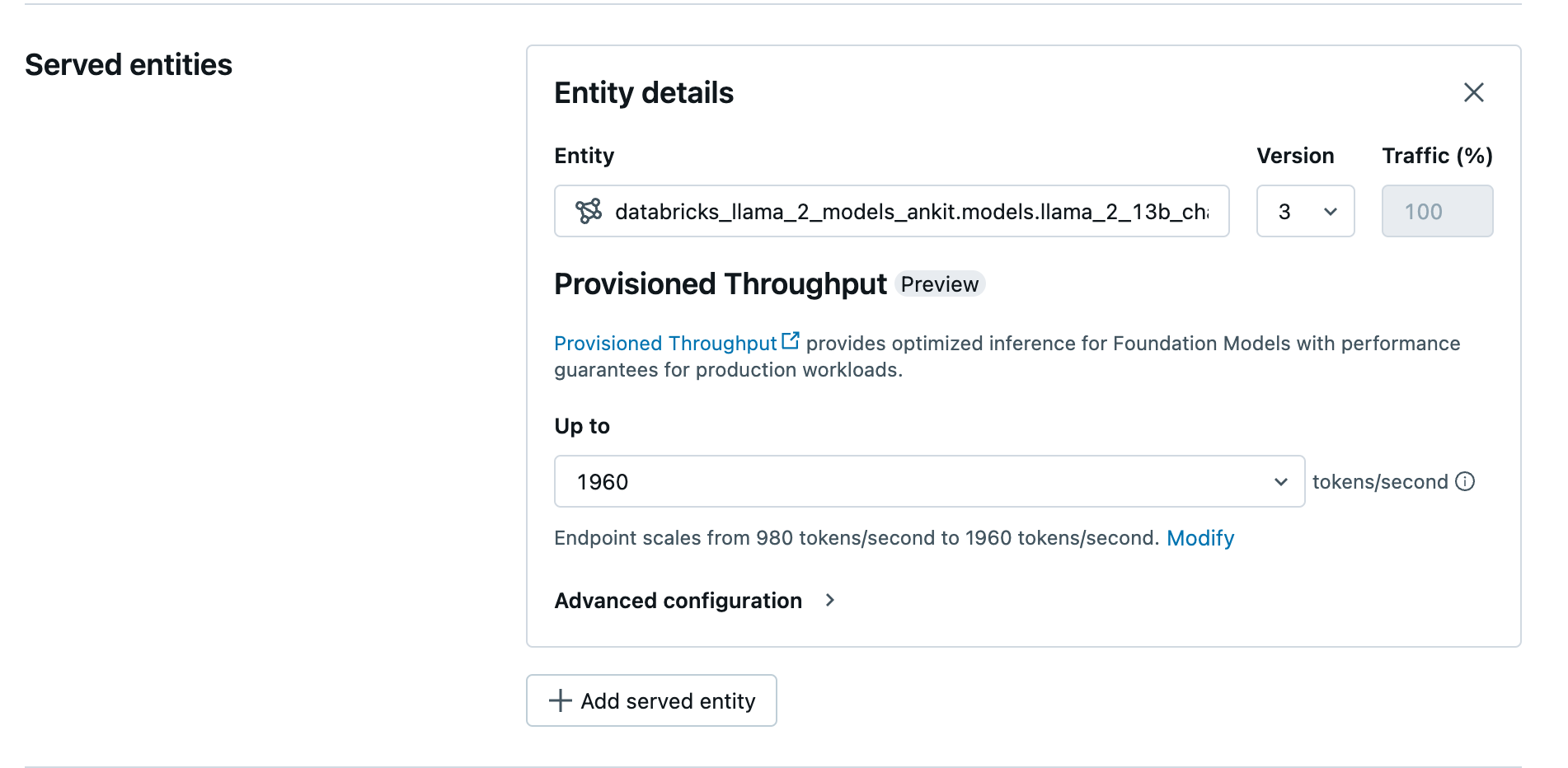 プロビジョニング スループットの
プロビジョニング スループットの
REST API を使用してプロビジョニング済みスループット エンドポイントを作成する
REST API を使用してプロビジョニング済みスループット モードでモデルをデプロイするには、要求に min_provisioned_throughput フィールドと max_provisioned_throughput フィールドを指定する必要があります。 Python を使用する場合は、MLflow Deployment SDK を使用して、エンドポイントを作成することもできます。
モデルに適したプロビジョニング済みスループットの範囲を特定するには、「プロビジョニング済みスループットを増分で取得する」を参照してください。
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
チャット完了タスクのログ確率
チャット完了タスクの場合は、logprobs パラメーターを使用して、大規模な言語モデル生成プロセスの一部としてサンプリングされるトークンのログ確率を指定できます。
logprobs は、分類、モデルの不確実性の評価、評価メトリックの実行など、さまざまなシナリオに使用できます。 パラメーターの詳細については、「チャット タスクの」を参照してください。
プロビジョニング スループットを増分で取得する
プロビジョニングされたスループットは、1 秒あたりのトークンの増分で利用でき、特定の増分はモデルによって異なります。 ニーズに適した範囲を特定するために、Databricks では、プラットフォーム内でモデル最適化情報 API を使用することをお勧めします。
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
API からの応答の例を次に示します。
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
ノートブックの例
次のノートブックは、プロビジョニングされたスループット基盤モデル API を作成する方法の例を示しています。
GTE モデル ノートブックに提供されるプロビジョニング スループット
BGE モデル ノートブックのプロビジョニング スループット提供
次のノートブックは、Unity カタログで DeepSeek R1 の蒸留された Llama モデルをダウンロードして登録する方法を示しています。そのため、Foundation Model API によってプロビジョニングされたスループット エンドポイントを使用してデプロイできます。
DeepSeek R1 distilled Llama モデル ノートブックのプロビジョニング スループット提供
制限事項
- GPU 容量の問題が原因でモデルのデプロイが失敗し、エンドポイントの作成または更新中にタイムアウトが発生する可能性があります。 解決するには、Databricks アカウント チームにお問い合わせください。
- Foundation Models API の自動スケーリングは、CPU モデルサービスよりも遅くなります。 Databricks では、要求のタイムアウトを回避するために、過剰なプロビジョニングを推奨しています。
- GTE v1.5 (英語) では、正規化された埋め込みを生成しません。