Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Low Rank Adaptation (LoRA) can be utilized to fine-tune the Phi Silica model to enhance its performance for your specific use-case. By using LoRA to optimize Phi Silica, Microsoft Windows local language model, you can achieve more accurate results. This process involves training a LoRA adapter and then applying it during inference to improve the model's accuracy.
Prerequisites
- You have identified a use case for enhancing the response of Phi Silica.
- You have chosen an evaluation criteria to decide what a 'good response' is.
- You have tried the Phi Silica APIs and they do not meet your evaluation criteria.
Train your adapter
To train a LoRA adapter for fine-tuning the Phi Silica model with Windows 11, you must first generate a dataset that the training process will use.
Generate a dataset for use with a LoRA adapter
To generate a dataset, you will need to split data into two files:
train.json– Used for training the adapter.test.json– Used for evaluating the adapter's performance during and after training.
Both files must use the JSON format, where each line is a separate JSON object representing a single sample. Each sample should contain a list of messages exchanged between a user and an assistant.
Every message object requires two fields:
content: the text of the message.role: either"user"or"assistant", indicating the sender.
See the following examples:
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
Training tips:
There is no comma needed at the end of each sample line.
Include as many high-quality and diverse examples as possible. For best results, collect at least a few thousand training samples in your
train.jsonfile.The
test.jsonfile can be smaller, but should cover the types of interactions you expect your model to handle.Create
train.jsonandtest.jsonfiles with one JSON object per line, each containing a brief back-and-forth conversation between a user and an assistant. The quality and quantity of your data will greatly affect the effectiveness of your LoRA adapter.
Training a LoRA adapter in the AI Toolkit
To train a LoRA adapter using the AI Toolkit for Visual Studio Code, you will first need the follow required prerequisites:
Azure subscription with available quota in Azure Container Apps.
- We recommend using A100 GPUs or better to efficiently run a fine-tuning job.
- Check that you have available quota in the Azure Portal. If you'd like help finding your quota, see View Quotas.
You will need to install Visual Studio Code if you don't already have it.
To install AI Toolkit for Visual Studio Code:
Once the AI Toolkit extension is downloaded, you will be able to access it from the left toolbar pane inside Visual Studio Code.
Navigate to Tools > Fine-tuning.
Enter a Project Name and Project Location.
Select "microsoft/phi-silica" from the Model Catalog.
Select "Configure project".
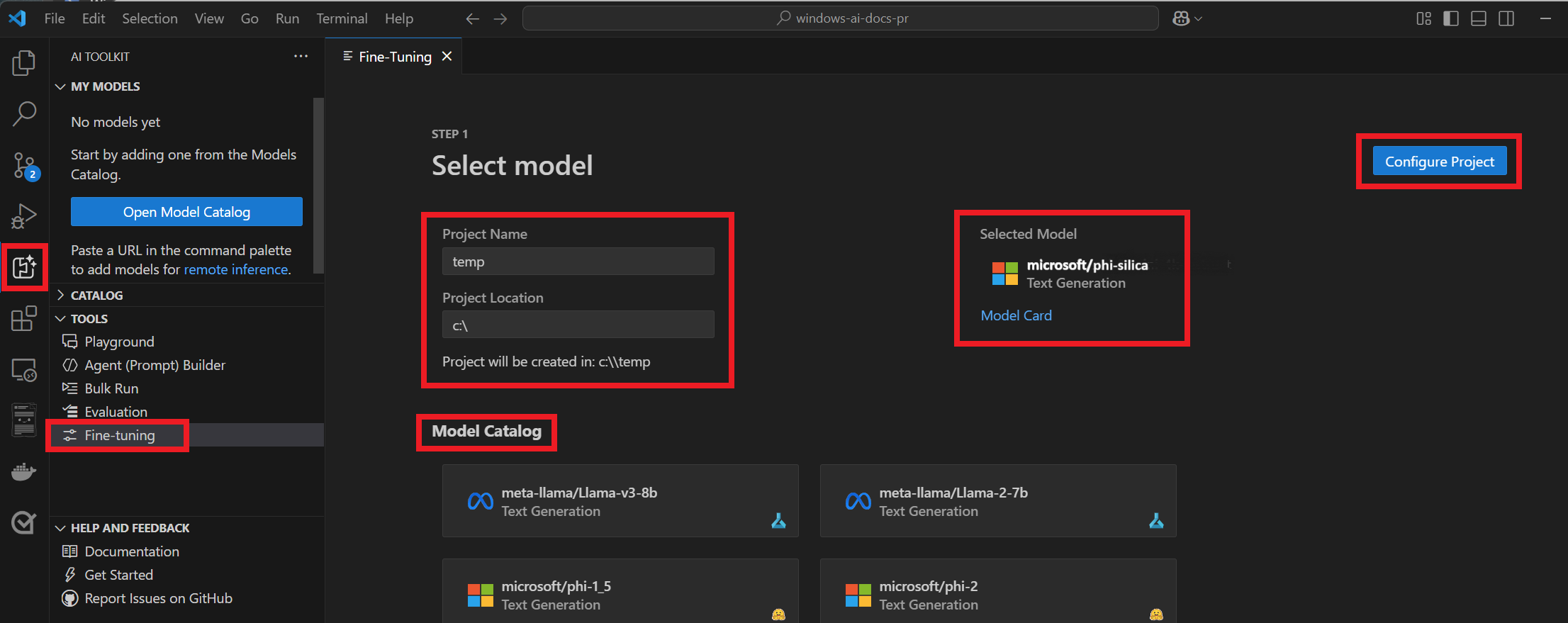
Select the latest version of Phi Silica.
Under Data > Training Dataset name and Test Dataset name, select your
train.jsonandtest.jsonfiles.Select "Generate Project" - a new VS Code windows will open.
Ensure that the correct workload profile is selected in your bicep file so that the Azure job deploys and runs correctly. Add the following under
workloadProfiles:{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }Select "New Fine-tuning Job" and enter a name for the job.
A dialog box will appear asking you to select the Microsoft account with which to access your Azure subscription.
Once your account is selected, you will need to select a Resource Group from the subscription dropdown menu.
You will now see that your fine-tuning job has successfully started, along with a Job Status. Once the job has completed, you will have the option to download the newly trained LoRA adapter by selecting the "Download" button. It typically takes an average of 45 - 60 minutes for a fine-tuning job to complete.
Inference
Training is the initial phase where the AI model learns from a large dataset, recognizing patterns and correlations. Inference, on the other hand, is the application phase where a trained model (Phi Silica in our case) uses new data (our LoRA adapter) to make predictions or decisions with which to generate more customized output.
To apply the trained LoRA adapter:
Use the AI Dev Gallery app. AI Dev Gallery is an app which allows you to experiment with local AI models and API, in addition to viewing and exporting sample code. Learn more about AI Dev Gallery.
Once you have installed AI Dev Gallery, open the app and select the "AI APIs" tab, then select "Phi Silica LoRA."
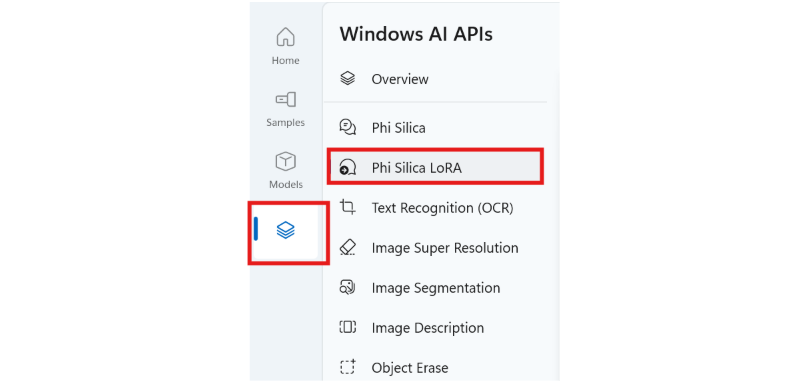
Select the adapter file. The default location for these to be stored is:
Desktop/lora_lab/trainedLora.Complete the "System Prompt" and "Prompt" fields. Then select "Generate" to see the difference between Phi Silica with and without the LoRA adapter.
Experiment with the Prompt and System Prompt to see how this makes a difference to your output.
Select "Export Sample" to download a standalone Visual Studio solution that only contains this sample code.
Generate responses
Once you've tested your new LoRA adapter using AI Dev Gallery, you can add the adapter to your Windows app using the code sample below.
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
Responsible AI - Risks and limitations of fine-tuning
When customers fine-tune Phi Silica, it can improve model performance and accuracy on specific tasks and domains, but it can also introduce new risks and limitations that customers should be aware of. Some of these risks and limitations are:
Data quality and representation: The quality and representativeness of the data used for fine-tuning can affect the model's behavior and outputs. If the data is noisy, incomplete, outdated, or if it contains harmful content like stereotypes, the model can inherit these issues and produce inaccurate or harmful results. For example, if the data contains gender stereotypes, the model can amplify them and generate sexist language. Customers should carefully select and pre-process their data to ensure that it is relevant, diverse, and balanced for the intended task and domain.
Model robustness and generalization: The model's ability to handle diverse and complex inputs and scenarios can decrease after fine-tuning, especially if the data is too narrow or specific. The model can overfit to the data and lose some of its general knowledge and capabilities. For example, if the data is only about sports, the model can struggle to answer questions or generate text about other topics. Customers should evaluate the model's performance and robustness on a variety of inputs and scenarios and avoid using the model for tasks or domains that are outside its scope.
Regurgitation: While your training data is not available to Microsoft or any third-party customers, poorly fine-tuned models may regurgitate, or directly repeat, training data. Customers are responsible for removing any PII or otherwise protected information from their training data and should assess their fine-tuned models for over-fitting or otherwise low-quality responses. To avoid regurgitation, customers are encouraged to provide large and diverse datasets.
Model transparency and explainability: The model's logic and reasoning can become more opaque and difficult to understand after fine-tuning, especially if the data is complex or abstract. A fine-tuned model can produce outputs that are unexpected, inconsistent, or contradictory, and customers may not be able to explain how or why the model arrived at those outputs. For example, if the data is about legal or medical terms, the model can generate outputs that are inaccurate or misleading, and customers may not be able to verify or justify them. Customers should monitor and audit the model's outputs and behavior and provide clear and accurate information and guidance to the end-users of the model.