Deploy a model to an endpoint
When you develop a generative AI app, you need to integrate language models into your application. To be able to use a language model, you need to deploy the model. Let's explore how to deploy language models in the Azure AI Foundry, after first understanding why to deploy a model.
Why deploy a model?
You train a model to generate output based on some input. To get value out of your model, you need a solution that allows you to send input to the model, which the model processes, after which the output is visualized for you.
With generative AI apps, the most common type of solution is a chat application that expects a user question, which the model processes, to generate an adequate response. The response is then visualized to the user as a response to their question.
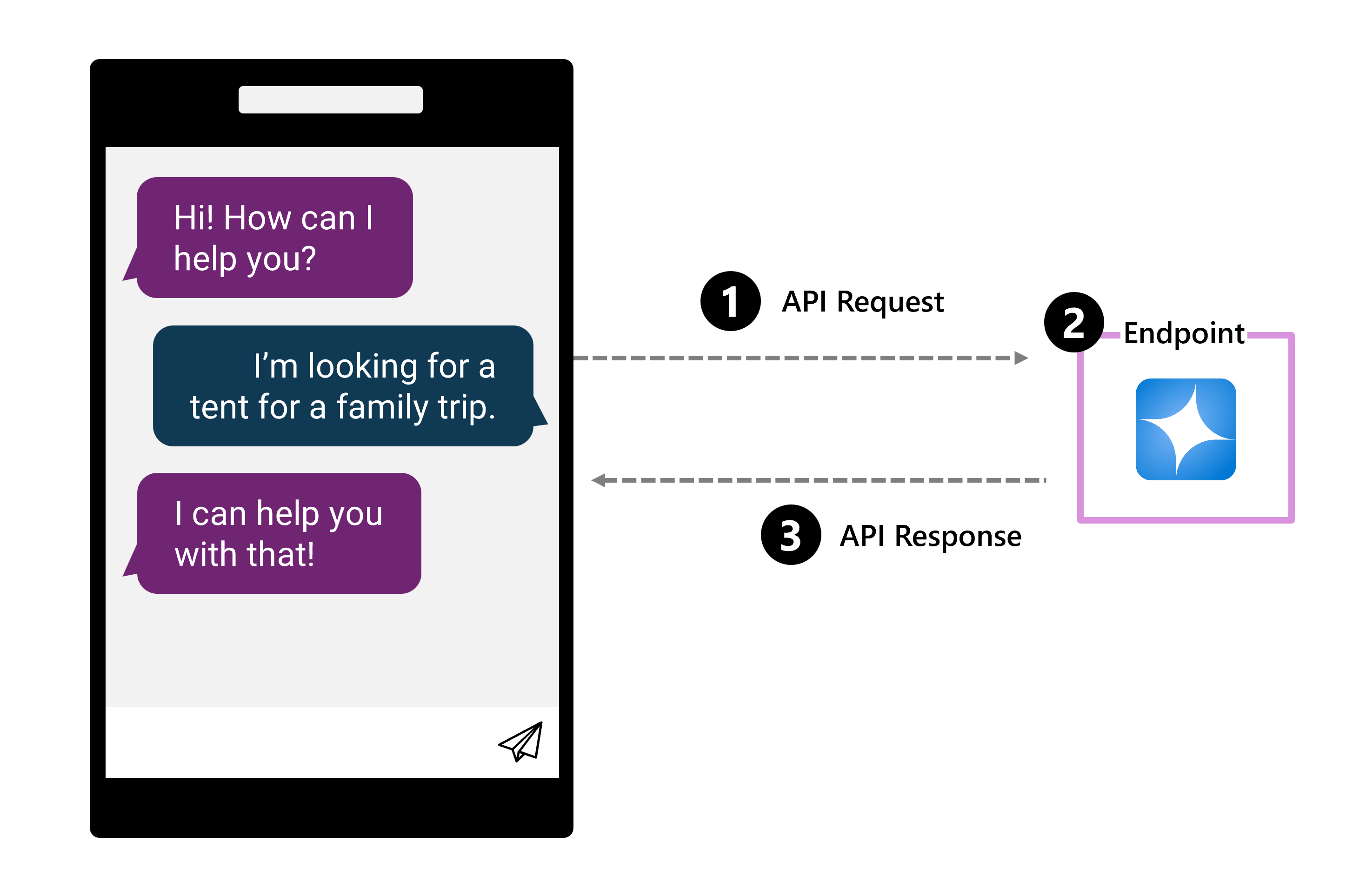
You can integrate a language model with a chat application by deploying the model to an endpoint. An endpoint is a specific URL where a deployed model or service can be accessed. Each model deployment typically has its own unique endpoint, which allows different applications to communicate with the model through an API (Application Programming Interface).
When a user asks a question:
- An API request is sent to the endpoint.
- The endpoint specifies the model that processes the request.
- The result is sent back to the app through an API response.
Now that you understand why you want to deploy a model, let's explore the deployment options with Azure AI Foundry.
Deploy a language model with Azure AI Foundry
When you deploy a language model with Azure AI Foundry, you have several types available, which depend on the model you want to deploy.
Deploy options include:
- Standard deployment: Models are hosted in the Azure AI Foundry project resource.
- Serverless compute: Models are hosted in Microsoft-managed dedicated serverless endpoints in an Azure AI Foundry hub project.
- Managed compute: Models are hosted in managed virtual machine images in an Azure AI Foundry hub project.
The associated cost depends on the type of model you deploy, which deployment option you choose, and what you are doing with the model:
| Standard deployment | Serverless compute | Managed compute | |
|---|---|---|---|
| Supported models | Azure AI Foundry models (including Azure OpenAI models and Models-as-a-service models) | Foundry Models with pay-as-you-go billing | Open and custom models |
| Hosting service | Azure AI Foundry resource | AI Project resource in a hub | AI Project resource in a hub |
| Billing basis | Token-based billing | Token-based billing | Compute-based billing |
Note
Standard deployment is recommended for most scenarios.