Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
NLU+ provides full, repeatable control over your agent's conversations, a customized dialog, and high accuracy for customer's queries. The NLU+ option is ideal for large enterprise-grade applications. These types of applications typically consist of a large number of topics and entities, and use a large number of training samples. Also, if you have a voice-enabled agent, your NLU+ training data is used to optimize your speech recognition capabilities.
NLU+ allows makers to add a large amount of annotated data, which drives users towards higher intent routing and entity extraction accuracy. Also, NLU+ is constructed on a grammar base, which ensures that you trigger an exact match with the training data that you added. This base can also be expanded with entity items and synonyms. This foundation ensures that the model always returns the exact intents and entities you added for annotations.
Important
- The NLU+ option is available when you manage your voice or chat channels with a Dynamics 365 Contact Center license. For more information, go to System requirements for Dynamics 365 Contact Center.
- When NLU+ is turned on, data is exchanged between Copilot Studio and Dynamics 365 Contact Center. This exchange includes training and runtime data. Each service follows its own specific data policies. For more information regarding these policies, go to Key concepts - Copilot Studio security and governance and Privacy and personal data in Microsoft Dynamics 365.
NLU+ best practices
Consider the following guidance before building your NLU+ model and application:
- Use as much real-world training data as possible. Add distinct variations in carrier phrases to help the model learn different ways to trigger intents or entity extractions.
- When you're annotating entities, only one entity variant or synonym is sufficient. Adding more variants doesn't add any extra value.
- The more distinct your intents and entities, your model performance increases. If similar utterances are used within different intents, or as items or synonyms, there's a higher chance of model confusion.
- Don't include determiners or prepositions in entity literals and annotations. Keep determiners and prepositions outside the entity or annotation.
Setup orchestration and language understanding
To use NLU+, first configure the generative AI orchestration settings, and then select the NLU+ language understanding option.
Open your agent and select Settings.
Select the "classic" Copilot Studio orchestration option in your agent's settings (Generative AI > Orchestration > No).

Select the NLU+ option in your agent's Language understanding settings.
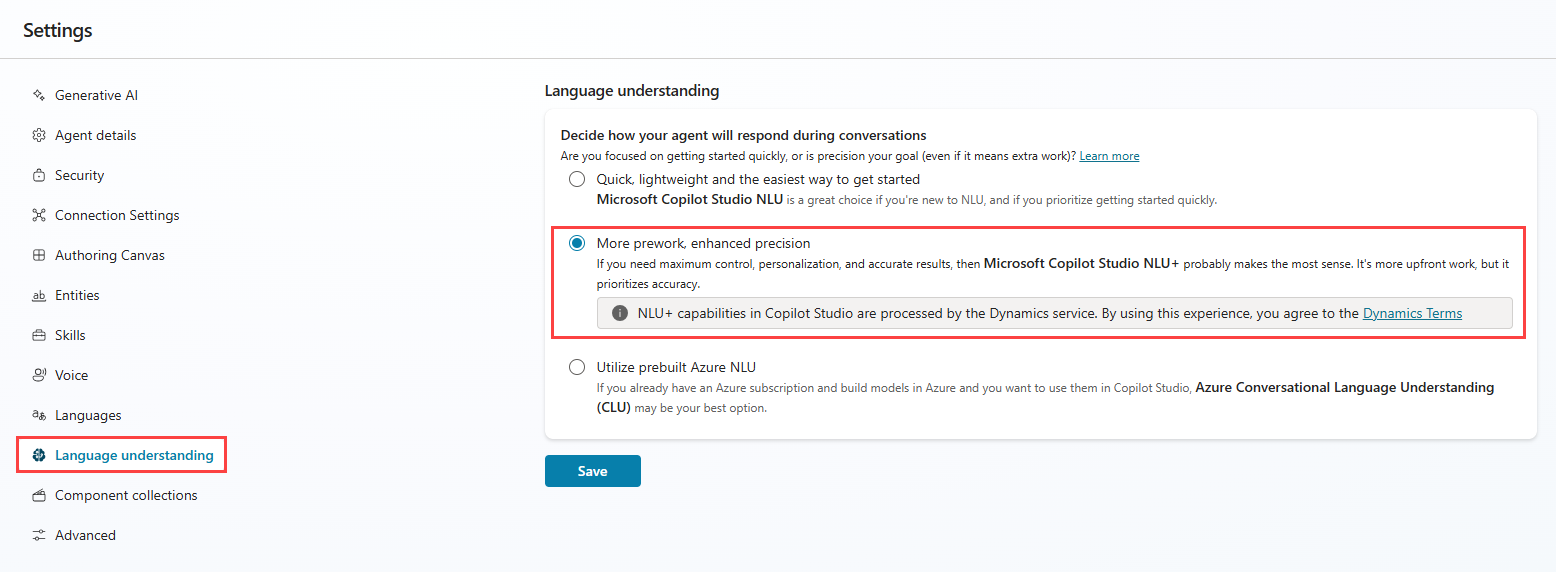
Select Save.
Setup topic annotations
To return the maximum value of NLU+, it's important to add entity annotations to the topic Trigger phrases for each topic. By adding entity annotations within the samples that trigger a topic, NLU+ can extract the entities as part of the process of triggering a topic.
The entities are annotated using the variables linked to the entities. This linkage allows the same entity to be used multiple times within a topic, shared across topics, or to create different copies within different topics.
Entity syntax
If you use entities in your project, they must be constructed using the following syntax:
{Topic.Variable_Name/Entity_item_or_synonym}: This syntax is used for local variables, scoped to a specific topic.{Gloabl.Variable_Name/Entity_item_orsynonym}: This syntax is used for global variables, used across all topics.
The following example illustrates how entities are formatted:
"book a ticket from {Topic.fromCity/Boston} to {Topic.toCity/NewYork} for {Topic.noPass/2} passengers {Topic.travelDate/tomorrow} in {Topic.class/First} class"

While entities are helpful, it's also common to have projects that don't use entities. Even if your project uses entities, not every sample requires entity annotation. There are some samples that only trigger a topic and don't extract the entities, even if there are entities tied to that topic. Which is why entity annotations are optional and not required.
Note
Entities can also be extracted, even if entity annotations aren't added. However, adding annotations increases the overall entity extraction accuracy.
Entity annotations
In addition to annotating entities within a topic's Trigger phrases, you can help the model extract entities as part of a Question node. Within each custom entity, you can add optional entity annotations. This method is used to annotate how customers respond to specific questions, which are asked to collect that particular entity.
You can only add a single entity as part of entity annotations. You can't annotate two different entities, or even two instances of an entity within entity annotations. For example, in a CustomCity entity, you can't add "Boston to New York" as an annotation.
Ensure you only add samples that refer to extracting an entity, and not triggering a topic. For example, if you have a flight booking app, you can add "book it for New York." You shouldn't add a sample that triggers a
bookTickettopic like, "I would like to travel to New York."
Annotation syntax
The following syntax variations can be used to create the annotation syntax.
{Entity value or Literal}: If you're annotating a single entity, you don't need to specify the entity.{ENTITY_NAME/Entity item or synonym}: If desired, you can specify the entity name, which is the name of the closed list or RegEx. Providing the entity name makes it easier to read in the YAML, and also matches the syntax used in topics.
The following example illustrates the annotation syntax:
- "book it for
{New York}" - "book it for
{City/New York}"

Custom list entities
For NLU+, list entities are considered to be partially open. This consideration means the model extracts entity literals that aren't explicitly defined in the list, so the model can handle entity data that isn't explicitly defined.
For example, you have a custom list with "Movie titles" that your app handles. If a user requests a title that isn't in your list, the model still marks that title as a "Movie entity." When this happens, the entity value is blank, because the model doesn't know what value to assign the entity.
To influence how open an entity is, alter the way you annotate your entity. If you add training data where the entity is annotated with items and synonyms already defined in your entity list, the model considers the entity mostly closed. The model still might extract new entity items, but the probability of that happening is low. The more training data you add with the entity annotated with literals not in your entity definition, the more open that list becomes. The model is more likely to extract entity literals not in your entity definition.
Build your NLU+ model
NLU+ requires that the maker explicitly builds their NLU+ model before they can test or publish their agent. This is different from the original NLU option, where changes are automatically incorporated. The NLU+ compiled model has a more predictable latency performance for large models, but requires model training.
After adding your training data and you're satisfied with it, select the Train NLU+ model button. The button is available in the Topics page or the Entities settings page.


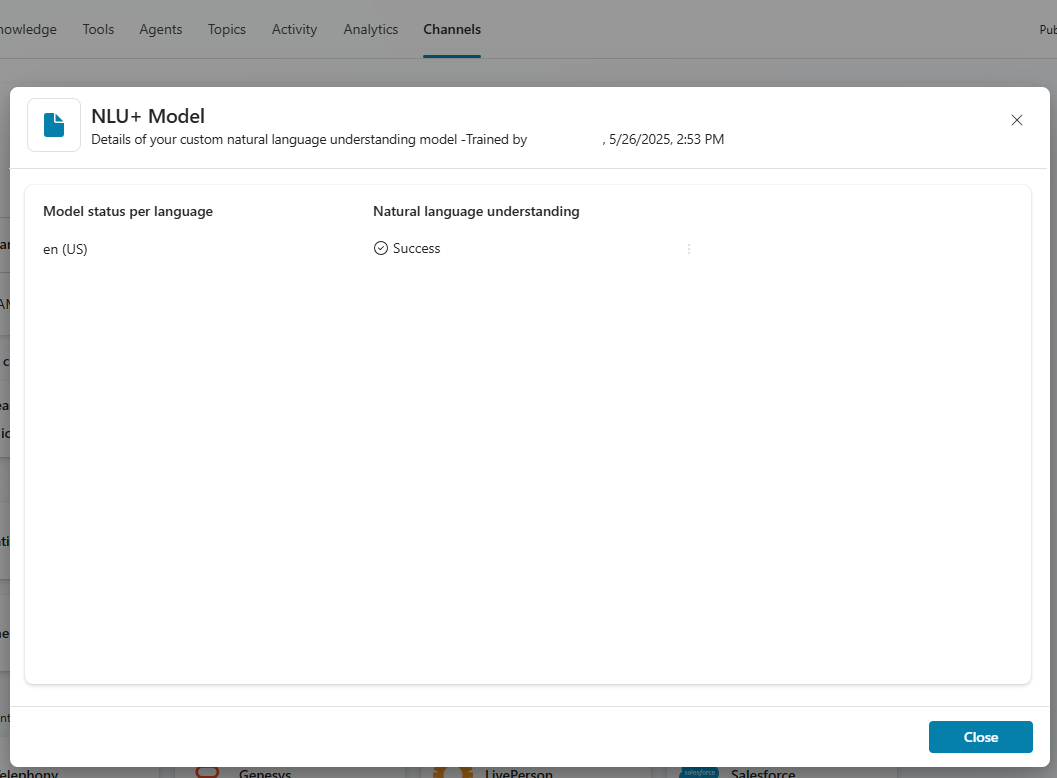
NLU+ model training times vary, based on the complexity of the model. The Channels page displays the model training status. Once training is completed, details about the trained model are displayed, including the user who initiated the training, when the training completed, and the status.

Select the NLU+ model training details in the Channels page to open the NLU+ training dialog. This dialog provides details about your model's training, such as information about each of your languages. If you have Optimize for voice turned on, you can view details of the ASR training. If the training had any errors or warnings for any region or locale, you can download the individual details file for more information about the specific issues.
Note
You must wait for training to complete before initiating another model training.
You can train the models as many times as you want. Copilot Studio only retains the last successfully trained model, and this model is used when testing or publishing your agent.
Publish your NLU+ agent
When you're ready to publish your agent and its NLU+ model, Copilot Studio uses the last successfully trained model. Select Publish, and the Publish dialog displays information about the last successfully trained model. This information allows the maker to know which version of the model is being published.
