Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article covers incremental data refresh in Dataflow Gen2 for Microsoft Fabric's Data Factory. When you use dataflows for data ingestion and transformation, sometimes you need to refresh only new or updated data—especially as your data grows larger.
Incremental refresh helps you:
- Reduce refresh times
- Make operations more reliable by avoiding long-running processes
- Use fewer resources
Prerequisites
To use incremental refresh in Dataflow Gen2, you need:
- A Fabric capacity
- A data source that supports folding (recommended) and contains a Date/DateTime column for filtering data
- A data destination that supports incremental refresh (see Destination support)
- Review the Limitations before you start
Destination support
These data destinations support incremental refresh:
- Fabric Lakehouse (preview)
- Fabric Warehouse
- Azure SQL Database
- Azure Synapse Analytics
You can use other destinations with incremental refresh too. Create a second query that references the staged data to update your destination. This approach still lets you use incremental refresh to reduce the data that needs processing from the source system.
However, you'll need to do a full refresh from the staged data to your final destination.
How to use incremental refresh
Create a new Dataflow Gen2 or open an existing one.
In the dataflow editor, create a new query that gets the data you want to refresh incrementally.
Check the data preview to make sure your query returns data with a DateTime, Date, or DateTimeZone column for filtering.
Make sure your query fully folds, which means the query gets pushed down to the source system. If it doesn't fully fold, modify your query so it does. You can check if your query fully folds by looking at the query steps in the query editor.
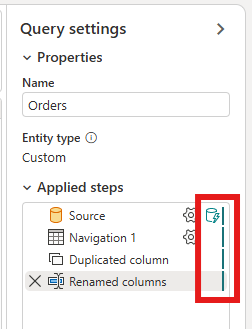
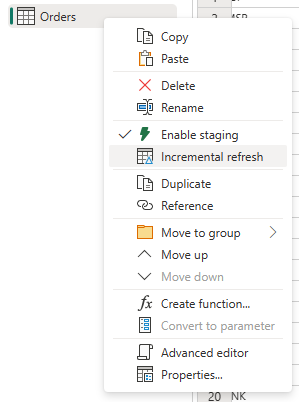
Right-click the query and select Incremental refresh.
Configure the required settings for incremental refresh.
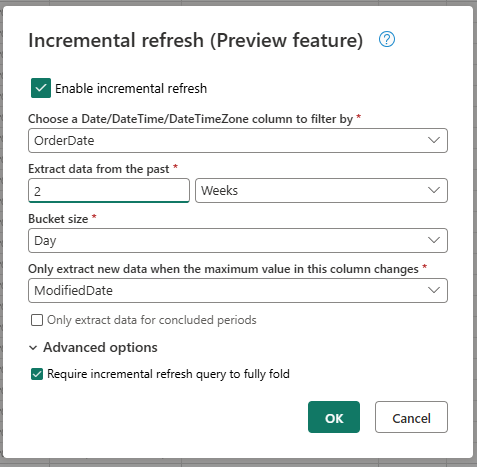
- Choose a DateTime column to filter by.
- Extract data from the past.
- Bucket size.
- Only extract new data when the maximum value in this column changes.
Configure the advanced settings if needed.
- Require incremental refresh query to fully fold.
Select OK to save your settings.
If you want, set up a data destination for the query. Do this before the first incremental refresh, or your destination will only contain the incrementally changed data since the last refresh.
Publish the Dataflow Gen2.
After you configure incremental refresh, the dataflow automatically refreshes data incrementally based on your settings. The dataflow only gets data that changed since the last refresh, so it runs faster and uses fewer resources.
How incremental refresh works behind the scenes
Incremental refresh divides your data into buckets based on the DateTime column. Each bucket contains data that changed since the last refresh. The dataflow knows what changed by checking the maximum value in the column you specified.
If the maximum value changed for that bucket, the dataflow gets the whole bucket and replaces the data in the destination. If the maximum value didn't change, the dataflow doesn't get any data. Here's how it works step by step.
First step: Evaluate the changes
When your dataflow runs, it first checks what's changed in your data source. It looks at the maximum value in your DateTime column and compares it to the maximum value from the last refresh.
If the maximum value changed (or if this is your first refresh), the dataflow marks that bucket as "changed" and will process it. If the maximum value is the same, the dataflow skips that bucket entirely.
Second step: Get the data
Now the dataflow gets the data for each bucket that changed. It processes multiple buckets at the same time to speed things up.
The dataflow loads this data into a staging area. It only gets data that falls within the bucket's time range—which means only the data that actually changed since your last refresh.
Last step: Replace the data in the destination
The dataflow updates your destination with the new data. It uses a "replace" approach: first it deletes the old data for that specific bucket, then it inserts the fresh data.
This process only affects data within the bucket's time range. Any data outside that range (like older historical data) stays untouched.
Incremental refresh settings explained
To configure incremental refresh, you need to specify these settings.
General settings
These settings are required and specify the basic configuration for incremental refresh.
Choose a DateTime column to filter by
This required setting specifies the column that dataflows use to filter the data. This column should be a DateTime, Date, or DateTimeZone column. The dataflow uses this column to filter the data and only gets data that changed since the last refresh.
Extract data from the past
This required setting specifies how far back in time the dataflow should extract data. This setting gets the initial data load. The dataflow gets all data from the source system within the specified time range. Possible values are:
- x days
- x weeks
- x months
- x quarters
- x years
For example, if you specify 1 month, the dataflow gets all new data from the source system within the last month.
Bucket size
This required setting specifies the size of the buckets that the dataflow uses to filter data. The dataflow divides data into buckets based on the DateTime column. Each bucket contains data that changed since the last refresh. The bucket size determines how much data gets processed in each iteration:
- A smaller bucket size means the dataflow processes less data in each iteration, but requires more iterations to process all the data.
- A larger bucket size means the dataflow processes more data in each iteration, but requires fewer iterations to process all the data.
Only extract new data when the maximum value in this column changes
This required setting specifies the column that the dataflow uses to determine if data changed. The dataflow compares the maximum value in this column to the maximum value from the previous refresh. If the maximum value changed, the dataflow gets the data that changed since the last refresh. If the maximum value didn't change, the dataflow doesn't get any data.
Only extract data for concluded periods
This optional setting specifies whether the dataflow should only extract data for concluded periods. If you enable this setting, the dataflow only extracts data for periods that concluded. The dataflow only extracts data for periods that are complete and don't contain any future data. If you disable this setting, the dataflow extracts data for all periods, including periods that aren't complete and contain future data.
For example, if you have a DateTime column that contains the date of the transaction and you only want to refresh complete months, you can enable this setting with the bucket size of month. The dataflow will only extract data for complete months and won't extract data for incomplete months.
Advanced settings
Some settings are considered advanced and aren't required for most scenarios.
Require incremental refresh query to fully fold
This setting controls whether your incremental refresh query must "fully fold." When a query fully folds, it gets pushed down entirely to your source system for processing.
If you enable this setting, your query must fully fold. If you disable it, the query can be partially processed by the dataflow instead of your source system.
We recommend enabling this setting. It improves performance and prevents your dataflow from pulling unnecessary, unfiltered data.
Limitations
Lakehouse support comes with additional caveats
When working with lakehouse as a data destination, be aware of these limitations:
Maximum number of concurrent evaluations is 10. This means the dataflow can only evaluate 10 buckets at the same time. If you have more than 10 buckets, you need to limit the number of buckets or limit the number of concurrent evaluations.
When you write to a lakehouse, the dataflow keeps track of which files it writes. This follows standard lakehouse practices.
But here's the catch: if other tools (like Spark) or processes also write to the same table, they can interfere with incremental refresh. We recommend avoiding other writers while using incremental refresh.
If you must use other writers, make sure they don't conflict with the incremental refresh process. Also, table maintenance like OPTIMIZE or REORG TABLE operations aren't supported for tables that use incremental refresh.
The data destination must be set to a fixed schema
The data destination must be set to a fixed schema, which means the schema of the table in the data destination must be fixed and can't change. If the schema of the table in the data destination is set to dynamic schema, you need to change it to fixed schema before you configure incremental refresh.
The only supported update method in the data destination is replace
The only supported update method in the data destination is replace, which means the dataflow replaces the data for each bucket in the data destination with the new data. However, data outside the bucket range isn't affected. If you have data in the data destination that's older than the first bucket, incremental refresh doesn't affect this data.
Maximum number of buckets is 50 for a single query and 150 for the whole dataflow
Each query can handle up to 50 buckets. If you have more than 50 buckets, you'll need to make your bucket size larger or reduce the time range to bring the count down.
For your entire dataflow, the limit is 150 buckets total. If you hit this limit, you can either reduce the number of queries using incremental refresh or increase the bucket size across your queries.
Differences between incremental refresh in Dataflow Gen1 and Dataflow Gen2
There are some differences in how incremental refresh works between Dataflow Gen1 and Dataflow Gen2. Here are the main differences:
First-class feature: Incremental refresh is now a first-class feature in Dataflow Gen2. In Dataflow Gen1, you configured incremental refresh after you published the dataflow. In Dataflow Gen2, you can configure it directly in the dataflow editor. This makes it easier to configure and reduces the risk of errors.
No historical data range: In Dataflow Gen1, you specified the historical data range when you configured incremental refresh. In Dataflow Gen2, you don't specify this range. The dataflow doesn't remove any data from the destination that's outside the bucket range. If you have data in the destination that's older than the first bucket, incremental refresh doesn't affect it.
Automatic parameters: In Dataflow Gen1, you specified the parameters for incremental refresh when you configured it. In Dataflow Gen2, you don't specify these parameters. The dataflow automatically adds the filters and parameters as the last step in the query.
FAQ
I got a warning that I used the same column for detecting changes and filtering. What does this mean?
If you get this warning, it means the column you specified for detecting changes is also used for filtering the data. We don't recommend this because it can lead to unexpected results.
Instead, use a different column for detecting changes and filtering the data. If data shifts between buckets, the dataflow might not detect the changes correctly and might create duplicated data in your destination.
You can resolve this warning by using a different column for detecting changes and filtering the data. Or you can ignore the warning if you're sure that data doesn't change between refreshes for the column you specified.
I want to use incremental refresh with a data destination that isn't supported. What can I do?
If you want to use incremental refresh with a data destination that doesn't support it, here's what you can do:
Enable incremental refresh on your query and create a second query that references the staged data. Then use that second query to update your final destination. This approach still reduces the data processing from your source system, but you'll need to do a full refresh from the staged data to your final destination.
Make sure you set up the window and bucket size correctly. We don't guarantee that staged data stays available outside the bucket range.
Another option is to use the incremental amass pattern. Check out our guide: Incremental amass data with Dataflow Gen2.
How do I know if my query has incremental refresh enabled?
You can see if your query has incremental refresh enabled by checking the icon next to the query in the dataflow editor. If the icon contains a blue triangle, incremental refresh is enabled. If the icon doesn't contain a blue triangle, incremental refresh isn't enabled.
My source gets too many requests when I use incremental refresh. What can I do?
You can control how many requests your dataflow sends to the source system. Here's how:
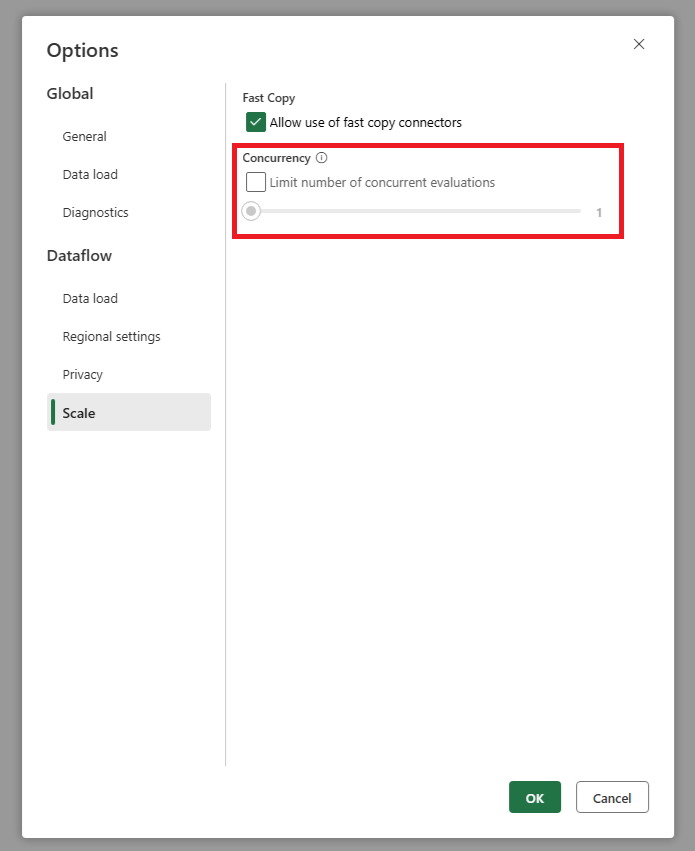
Go to your dataflow's global settings and look for the parallel query evaluations setting. Set this to a lower number to reduce the requests sent to your source system. This helps reduce the load on your source and can improve its performance.
To find this setting: go to global settings > Scale tab > set the maximum number of parallel query evaluations.
We recommend only using this limit if your source system can't handle the default number of concurrent requests.
I want to use incremental refresh but I see that after enablement, the dataflow takes longer to refresh. What can I do?
Incremental refresh should make your dataflow faster by processing less data. But sometimes the opposite happens. This usually means the overhead of managing buckets and checking for changes takes more time than you save by processing less data.
Here's what you can try:
Adjust your settings: Increase your bucket size to reduce the number of buckets. Fewer buckets mean less overhead from managing them.
Try a full refresh: If adjusting settings doesn't help, consider disabling incremental refresh. A full refresh might actually be more efficient for your specific scenario.