Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Queue Storage is a service for storing and distributing large numbers of messages. Queue Storage is commonly used to create a backlog of work to process asynchronously and provides reliable message delivery for loosely coupled application architectures. A queue message can be up to 64 KB in size, and a queue may contain millions of messages, up to the total capacity limit of a storage account.
Azure Queue Storage provides several reliability features through the underlying Azure Storage platform. As part of Azure Storage, Queue Storage inherits the same redundancy options, availability zone support, and geo-replication capabilities that ensure high availability and durability for your message queues.
This article describes reliability and availability zones support in Azure Queue Storage. For a more detailed overview of reliability in Azure, see Azure reliability.
Note
Azure Queue Storage is part of the Azure Storage platform. Some of the capabilities of Queue Storage are common across many Azure Storage services. In this document, we use "Azure Storage" to indicate these common capabilities.
Production deployment recommendations
For production environments:
Enable zone-redundant storage (ZRS) for the storage accounts that contain Queue Storage resources. ZRS provides higher availability by replicating your data synchronously across multiple availability zones in the primary region, protecting against availability zone failures.
If you need resilience to region outages and your storage account's primary region is paired, consider enabling geo-redundant storage, which replicates data asynchronously to the paired region. In supported regions, you can combine geo-redundancy with zone redundancy by using GZRS.
For advanced messaging requirements, consider using Azure Service Bus. To learn more about the differences between Queue Storage and Azure Service Bus, see Storage queues and Service Bus queues - compared and contrasted.
Reliability architecture overview
Azure Queue Storage operates as a distributed messaging service within the Azure Storage platform infrastructure. The service provides redundancy through multiple copies of your queue and message data, with the specific redundancy model depending on your storage account configuration.
Locally redundant storage (LRS) replicates the data within your storage accounts to one or more Azure availability zones located in the primary region of your choice. Although there's no option to choose your preferred availability zone, Azure may move or expand LRS accounts across zones to improve load balancing. There's no guarantee that your data will be spread across zones. LRS provides at least 99.999999999 (11 nines) durability of objects over a given year. For more information about availability zones, see What are Availability Zones?.

Zone-redundant storage (ZRS) and geo-redundant storage (GRS/GZRS) provide additional protections, and are described in detail in this article.
Transient faults
Transient faults are short, intermittent failures in components. They occur frequently in a distributed environment like the cloud, and they're a normal part of operations. Transient faults correct themselves after a short period of time. It's important that your applications can handle transient faults, usually by retrying affected requests.
All cloud-hosted applications should follow the Azure transient fault handling guidance when they communicate with any cloud-hosted APIs, databases, and other components. For more information, see Recommendations for handling transient faults.
Azure Queue Storage is commonly used in applications to be able to handle transient faults in other components. By using asynchronous messaging with a service like Azure Queue Storage, applications can recover from transient faults by reprocessing messages at a later time. To learn more, see Asynchronous Messaging Primer.
Within the service itself, Azure Queue Storage handles transient faults automatically through several mechanisms provided by the Azure Storage platform and client libraries. The service is designed to provide resilient message queuing capabilities even during temporary infrastructure issues.
Azure Queue Storage client libraries include built-in retry policies that automatically handle common transient failures such as network timeouts, temporary service unavailability (HTTP 503), and throttling responses (HTTP 429). When your application encounters these transient conditions, the client libraries automatically retry operations using exponential backoff strategies.
To manage transient faults effectively when using Azure Queue Storage:
- Configure appropriate timeouts in your Queue Storage client to balance responsiveness with resilience to temporary slowdowns. The default timeouts in Azure Storage client libraries are typically suitable for most scenarios.
- Implement circuit breaker patterns in your application when processing messages from queues to prevent cascading failures when downstream services are experiencing issues.
- Use visibility timeouts appropriately when receiving messages to ensure messages become available for retry if your application encounters failures during processing.
To learn more about the Azure Table Storage architecture and how to design resilient and high-scale applications, see Performance and scalability checklist for Queue Storage.
Availability zone support
Availability zones are physically separate groups of datacenters within each Azure region. When one zone fails, services can fail over to one of the remaining zones.
Azure Queue Storage is zone-redundant when deployed with ZRS configuration, meaning the service spreads replicas of your queue data synchronously across all of the availability zones in the region. This configuration ensures that your queues remain accessible even if an entire availability zone becomes unavailable. All write operations must be acknowledged across multiple zones before completing, providing strong consistency guarantees.
Zone redundancy is enabled at the storage account level and applies to all Queue Storage resources within that account. You cannot configure individual queues for different redundancy levels - the setting applies to the entire storage account. When an availability zone experiences an outage, Azure Storage automatically routes requests to healthy zones without requiring any intervention from your application.

Region support
Zone-redundant Azure Storage accounts can be deployed in any region that supports availability zones.
Requirements
You must use a Standard general-purpose v2 storage account to enable zone-redundant storage for Queue Storage. Premium storage accounts don't support Queue Storage.
Cost
When you enable ZRS, you're charged at a different rate than locally redundant storage due to the additional replication and storage overhead.
For detailed pricing information, see Azure Queue Storage pricing.
Configure availability zone support
Create a storage account and queue with zone redundancy:
Create a storage account and select ZRS, geo-zone-redundant storage (GZRS) or read-access geo-redundant storage (RA-GZRS) as the redundancy option during account creation.
Change replication type. To learn how to change an existing storage account to ZRS, as well as learn about configuration options and requirements, see Change how a storage account is replicated.
Disable zone redundancy. Convert ZRS accounts back to a nonzonal configuration (such as LRS) through the same redundancy configuration change process.
Normal operations
This section describes what to expect when a queue storage account is configured for zone redundancy and all availability zones are operational.
Traffic routing between zones: Storage with ZRS automatically distributes requests across storage clusters in multiple availability zones. Traffic distribution is transparent to applications and requires no client-side configuration.
Data replication between zones: All write operations to ZRS are replicated synchronously across all availability zones within the region. When you upload or modify data, the operation isn't considered complete until the data has been successfully replicated across all of the availability zones. This synchronous replication ensures strong consistency and zero data loss during zone failures.
Zone-down experience
When an availability zone becomes unavailable, Azure Queue Storage automatically handles the failover process with the following behavior:
Detection and response: Microsoft automatically detects zone failures and initiates recovery processes. No customer action is required for zone-redundant storage accounts.
If a zone becomes unavailable, Azure undertakes networking updates such as Domain Name System (DNS) repointing.
Notification: Zone failure events can be monitored through Azure Service Health and Resource Health. Set up alerts on these services to receive notifications of zone-level issues.
Active requests: In-flight requests might be dropped during the recovery process and should be retried. Applications should implement retry logic to handle these temporary interruptions.
Expected data loss: No data loss occurs during zone failures because data is synchronously replicated across multiple zones before write operations complete.
Expected downtime: A small amount of downtime - typically, a few seconds - may occur during automatic recovery as traffic is redirected to healthy zones. When designing applications for ZRS, follow practices for transient fault handling, including implementing retry policies with exponential back-off.
- Traffic rerouting. Azure automatically reroutes traffic to the remaining healthy availability zones. The service maintains full functionality using the surviving zones with no customer intervention required.
Failback
When the failed availability zone recovers, Azure Storage automatically restores normal operations across all of the availability zones. The service automatically ensures data consistency by synchronizing any operations that occurred during the outage period.
Testing for zone failures
When you use ZRS, Azure Storage manages replication, traffic routing, and zone-down responses automatically. Because this feature is fully managed, you don't need to initiate or validate availability zone failure processes.
Multi-region support
Azure Storage - whether that's for Blob, Files, Table, or Queue - provides a range of geo-redundancy and failover capabilities to suit different requirements.
Important
Geo-redundant storage only works within Azure paired regions. If your storage account's region isn't paired, consider using the alternative multi-region approaches.
Replication across paired regions
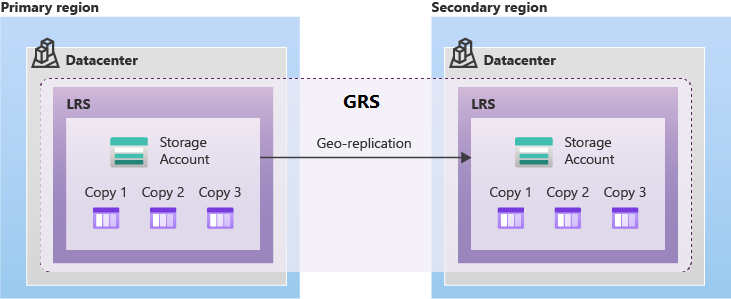
Azure Storage provides several types of geo-redundant storage in paired regions. Whichever type of geo-redundant storage you use, data in the secondary region is always replicated using locally redundant storage (LRS), providing protection against hardware failures within the secondary region.
Geo-redundant storage (GRS) provides support for planned and unplanned failovers to the Azure paired region when there's an outage in the primary region. GRS asynchronously replicates data from the primary region to the paired region.
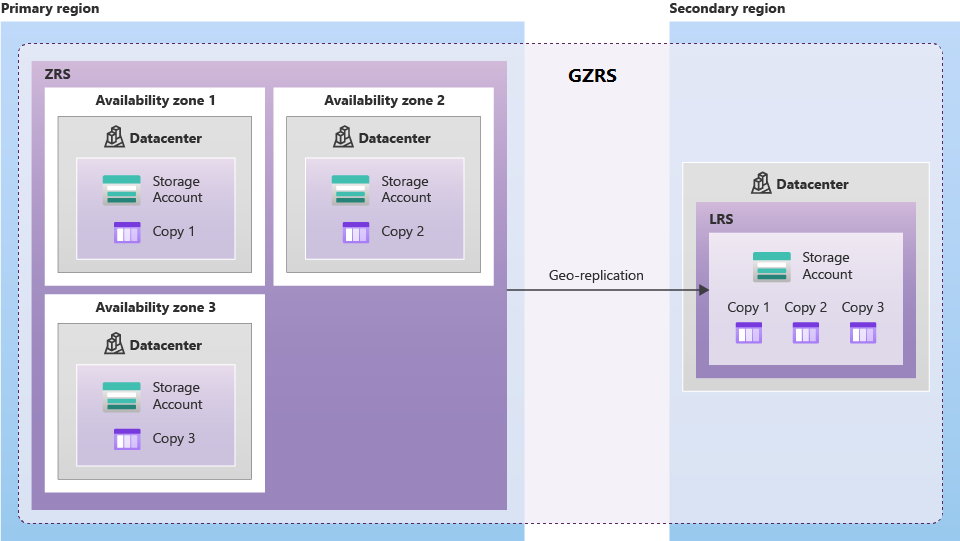
Geo-zone redundant storage (GZRS) replicates data in multiple availability zones in the primary region, and also into the paired region.


- Read-access geo-redundant storage (RA-GRS) and read-access geo-zone-redundant storage (RA-GZRS) extends GRS and GZRS, with the added benefit of read access to the secondary endpoint. These options are ideal for applications designed for high availability business-critical applications. In the unlikely event that the primary endpoint experiences an outage, applications configured for read access to the secondary region can continue to operate.
Failover types
Azure Storage supports three types of failover that are intended for different situations:
Customer-managed unplanned failover: You are responsible for initiating recovery if there's a region-wide storage failure in your primary region.
Customer-managed planned failover: You are responsible for initiating recovery if another part of your solution has a failure in your primary region, and you need to switch your whole solution over to a secondary region.
Microsoft-managed failover: In exceptional situations, Microsoft might initiate failover for all GRS storage accounts in a region. However, Microsoft-managed failover is a last resort and is expected to only be performed after an extended period of outage. You shouldn't rely on Microsoft-managed failover.
Geo-redundant storage accounts can use any of these failover types. You don't need to preconfigure a storage account to use any of the failover types ahead of time.
Region support
Azure Storage geo-redundant configurations use Azure paired regions for secondary region replication. The secondary region is automatically determined based on your primary region selection and cannot be customized. For a complete list of Azure paired regions, see Azure regions list.
If your storage account's region isn't paired, consider using the alternative multi-region approaches.
Requirements
Geo-redundant storage, as well as customer initiated failover and failback are available in all Azure paired regions that support general-purpose v2 storage accounts.
Considerations
When implementing multi-region Azure Queue Storage, consider the following important factors:
Asynchronous replication latency: Data replication to the secondary region is asynchronous, which means there's a lag between when data is written to the primary region and when it becomes available in the secondary region. This lag can result in potential data loss (measured as Recovery Point Objective or RPO) if a primary region failure occurs before recent data is replicated. The replication lag is expected to be less than 15 minutes, but this is an estimate and not guaranteed.
You can check the Last Sync time to understand how much data could be lost if your storage account has an unplanned failover.
Secondary region access: With GRS and GZRS configurations, the secondary region isn't accessible for reads until a failover occurs.
RA-GRS and RA-GZRS configurations provide read access to the secondary region during normal operations, but because of the asynchronous replication latency, might return slightly outdated data.
- Feature limitations: Some Azure Storage features are not supported or have limitations when using geo-redundant storage or when using customer-managed failover. Review feature compatibility documentation before implementing geo-redundancy.
Cost
Multi-region Azure Storage account configurations incur additional costs for cross-region replication and storage in the secondary region. Data transfer between Azure regions is charged based on standard inter-region bandwidth rates.
For detailed pricing information, see Azure Queue Storage pricing.
Configure multi-region support
- Create a new storage account with geo-redundancy. To create a storage account with geo-redundant configuration, see Create a storage account and select GRS, RA-GRS, GZRS, or RA-GZRS during account creation.
Migration. To convert an existing storage account to geo-redundant storage, see Change how a storage account is replicated for step-by-step conversion procedures.
Warning
After your account is reconfigured for geo-redundancy, it may take a significant amount of time before existing data in the new primary region is fully copied to the new secondary.
To avoid a major data loss, check the value of the Last Sync Time property before initiating an unplanned failover. To evaluate potential data loss, compare the last sync time to the last time at which data was written to the new primary.
Disable geo-redundancy. Convert geo-redundant storage accounts back to single-region configurations (LRS or ZRS) through the same redundancy configuration change process.
Normal operations
This section describes what to expect when a storage account is configured for geo-redundancy and all regions are operational.
Traffic routing between regions: Azure Storage uses an active/passive approach where all write operations and most read operations are directed to the primary region.
For RA-GRS and RA-GZRS configurations, applications can optionally read from the secondary region by accessing the secondary endpoint, but this requires explicit application configuration and is not automatic. Also, because of the asynchronous replication lag, data in the secondary region might be slightly outdated.
Data replication between regions: Write operations are first committed to the primary region using the configured redundancy type (LRS for GRS/RA-GRS, or ZRS for GZRS/RA-GZRS). After successful completion in the primary region, data is asynchronously replicated to the secondary region where it's stored using locally redundant storage (LRS).
The asynchronous nature of cross-region replication means there's typically a lag time between when data is written to primary and when it's available in the secondary region. You can monitor the replication time through the Last Sync Time property.
Region-down experience
This section describes what to expect when a storage account is configured for geo-redundancy and there's an outage in the primary region.
Customer-managed failover (unplanned): An unplanned failover is intended to be used when storage in the primary region is unavailable.
Detection and response: In the unlikely event that your storage account is unavailable in your primary region, you can consider initiating a customer-managed unplanned failover. To make this decision, consider the following factors:
- Whether Azure Resource Health shows problems accessing the storage account in your primary region.
- Whether Microsoft has advised you to perform failover to another region.
Warning
An unplanned failover can result in data loss. Before initiating a customer-managed failover, decide whether the risk of data loss is justified by the restoration of service.
Notification: Region failure events can be monitored through Azure Service Health and Resource Health. Set up alerts on these services to receive notifications of region-level issues.
Active requests: During the failover process, both the primary and secondary storage account endpoints become temporarily unavailable for both reads and writes. Any active requests might be dropped, and client applications need to retry after the failover completes.
Expected data loss: During an unplanned failover, it's likely that you will have some data loss. This is because of the asynchronous replication lag, which means that recent writes may not be replicated. You can check the Last Sync time to understand how much data could be lost during an unplanned failover. Typically the data loss is expected to be less than 15 minutes, but that's not guaranteed.
Expected downtime: Failover typically completes within 60 minutes, depending on the account size and complexity.
Traffic rerouting: As the failover completes, Azure automatically updates the storage account endpoints so that applications don't need to be reconfigured. If your application keeps DNS entries cached, it might be necessary to clear the cache to ensure that the application sends traffic to the new primary.
Post-failover configuration: After an unplanned failover completes, your storage account in the destination region uses the LRS tier. If you need to geo-replicate it again, you need to re-enable GRS and wait for the data to be replicated to the new secondary region.
For more information on initiating customer-managed failover, see How customer-managed (unplanned) failover works and Initiate a storage account failover.
Customer-managed failover (planned): A planned failover is intended to be used when storage remains operational in the primary region, but you need to fail over your whole solution to a secondary region for another reason.
Detection and response: You're responsible for deciding to fail over. You'd typically do so if you need to fail over between regions even though your storage account is healthy. For example, you might trigger a failover when there's a major outage of another application component that you can't recover from in the primary region.
Notification: Region failure events can be monitored through Azure Service Health and Resource Health. Set up alerts on these services to receive notifications of region-level issues.
Active requests: During the failover process, both the primary and secondary storage account endpoints become temporarily unavailable for both reads and writes. Any active requests might be dropped, and client applications need to retry after the failover completes.
Expected data loss: No data loss is expected because the failover process waits for all data to be synchronized.
Expected downtime: Failover typically completes within 60 minutes, depending on the account size and complexity. During the failover process, both the primary and secondary storage account endpoints become temporarily unavailable for both reads and writes.
Traffic rerouting: As the failover completes, Azure automatically updates the storage account endpoints so that applications don't need to be reconfigured. If your application keeps DNS entries cached, it might be necessary to clear the cache to ensure that the application sends traffic to the new primary.
Post-failover configuration: After a planned failover completes, your storage account in the destination region continues to be geo-replicated and remains on the GRS tier.
For more information on initiating customer-managed failover, see How customer-managed (planned) failover works and Initiate a storage account failover.
Microsoft-managed failover: In the rare case of a major disaster, where Microsoft determines the primary region is permanently unrecoverable, Microsoft might initiate automatic failover to the secondary region. This process is managed entirely by Microsoft and requires no customer action. The amount of time that elapses before failover occurs depends on the severity of the disaster and the time required to assess the situation.
- Notification: Region failure events can be monitored through Azure Service Health and Resource Health. Set up alerts on these services to receive notifications of region-level issues.
Important
Use customer-managed failover options to develop, test, and implement your disaster recovery plans. Do not rely on Microsoft-managed failover, which might only be used in extreme circumstances. A Microsoft-managed failover would likely be initiated for an entire region. It can't be initiated for individual storage accounts, subscriptions, or customers. Failover might occur at different times for different Azure services. We recommend you use customer-managed failover.
Failback
The failback process differs significantly between Microsoft-managed and customer-managed failover scenarios:
Customer-managed failover (unplanned): After an unplanned failover, the storage account is configured with locally redundant storage (LRS). In order to fail back, you need to re-establish the GRS relationship and wait for the data to be replicated.
Customer-managed failover (planned): After a planned failover, the storage account remains geo-replicated (GRS). You can initiate another customer-managed failover in order to fail back to the original primary region. The same failover considerations apply.
Microsoft-managed failover: If Microsoft initiates a failover, it's likely that a significant disaster has occurred in the primary region, and the primary region might not be recoverable. Any timelines or recovery plans depends on the extent of the regional disaster and recovery efforts. You should monitor Azure Service Health communications for details.
Testing for region failures
You can simulate regional failures to test your disaster recovery procedures:
Planned failover testing: For geo-redundant storage accounts, you can perform planned failover operations during maintenance windows to test the complete failover and failback process. Although planned failover doesn't require data loss it does involve downtime during both failover and failback.
Secondary endpoint testing: For RA-GRS and RA-GZRS configurations, regularly test read operations against the secondary endpoint to ensure your application can successfully read data from the secondary region.
Alternative multi-region approaches
It may be the case that the cross-region failover capabilities of Azure Storage are unsuitable for the following reasons:
Your storage account is in a nonpaired region.
Your business uptime goals aren't satisfied by the recovery time or data loss that the built-in failover options provide.
You need to fail over to a region that isn't your primary region's pair.
You need an active/active configuration across regions.
Instead, you can design a cross-region failover solution that's tailored to your needs. A complete treatment of deployment topologies for Azure Storage is outside the scope of this article, but you can consider a multi-region deployment model.
Note
For advanced multi-region requirements, consider using Azure Service Bus instead, which includes support for nonpaired regions.
Azure Storage can be deployed across multiple regions using separate storage accounts in each region. This approach provides flexibility in region selection, the ability to use non-paired regions, and more granular control over replication timing and data consistency. When implementing multiple storage accounts across regions, you need to configure cross-region data replication, implement load balancing and failover policies, and ensure data consistency across regions.
This approach requires you to manage message distribution, handle data synchronization between queues in the different storage accounts, and implement custom failover logic.
Backups
Azure Queue Storage doesn't provide traditional backup capabilities like point-in-time restore, because queues are designed for transient message storage rather than long-term data persistence. Messages are typically processed and removed from queues during normal application operations.
For scenarios requiring message durability beyond the built-in redundancy options, consider implementing your own application-level message logging or persistence to a permanent data store, like Azure Blob Storage or Azure SQL Database. This approach allows you to maintain message history while using Queue Storage for its intended purpose of temporary message buffering and processing coordination.
Service-level agreement
The service-level agreement (SLA) for Azure Storage describes the expected availability of the service and the conditions that must be met to achieve that availability expectation. The availability SLA you'll be eligible for depends on the storage tier and the replication type you use. For more information, see Service Level Agreements (SLA) for Online Services.