Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article explains retrieval-augmented generation (RAG) and what developers need to build a production-ready RAG solution.
To learn about two ways to build a "chat over your data" app—one of the top generative AI use cases for businesses—see Augment LLMs with RAG or fine-tuning.
The following diagram shows the main steps of RAG:
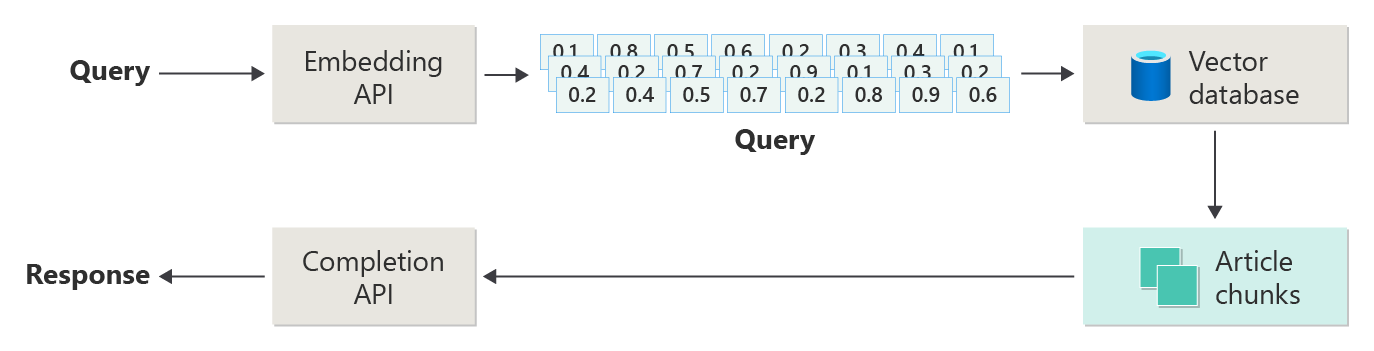
This process is called naive RAG. It helps you understand the basic parts and roles in a RAG-based chat system.
Real-world RAG systems need more preprocessing and post-processing to handle articles, queries, and responses. The next diagram shows a more realistic setup, called advanced RAG:

This article gives you a simple framework to understand the main phases in a real-world RAG-based chat system:
- Ingestion phase
- Inference pipeline phase
- Evaluation phase
Ingestion
Ingestion means saving your organization's documents so you can quickly find answers for users. The main challenge is to find and use the parts of documents that best match each question. Most systems use vector embeddings and cosine similarity search to match questions to content. You get better results when you understand the content type (like patterns and format) and organize your data well in the vector database.
When setting up ingestion, focus on these steps:
- Content preprocessing and extraction
- Chunking strategy
- Chunking organization
- Update strategy
Content preprocessing and extraction
The first step in the ingestion phase is to preprocess and extract the content from your documents. This step is crucial because it ensures that the text is clean, structured, and ready for indexing and retrieval.
Clean and accurate content makes a RAG-based chat system work better. Start by looking at the shape and style of the documents you want to index. Do they follow a set pattern, like documentation? If not, what questions could these documents answer?
At a minimum, set up your ingestion pipeline to:
- Standardize text formats
- Handle special characters
- Remove unrelated or old content
- Track different versions of content
- Handle content with tabs, images, or tables
- Extract metadata
Some of this information, like metadata, can help during retrieval and evaluation if you keep it with the document in the vector database. You can also combine it with the text chunk to improve the chunk's vector embedding.
Chunking strategy
As a developer, decide how to break up large documents into smaller chunks. Chunking helps send the most relevant content to the LLM so it can answer user questions better. Also, think about how you'll use the chunks after you get them. Try out common industry methods and test your chunking strategy in your organization.
When chunking, think about:
- Chunk size optimization: Pick the best chunk size and how to split it—by section, paragraph, or sentence.
- Overlapping and sliding window chunks: Decide if chunks should be separate or overlap. You can also use a sliding window approach.
- Small2Big: If you split by sentence, organize the content so you can find nearby sentences or the full paragraph. Giving this extra context to the LLM can help it answer better. For more, see the next section.
Chunking organization
In a RAG system, how you organize your data in the vector database makes it easier and faster to find the right information. Here are some ways to set up your indexes and searches:
- Hierarchical indexes: Use layers of indexes. A top-level summary index quickly finds a small set of likely chunks. A second-level index points to the exact data. This setup speeds up searches by narrowing down the options before looking in detail.
- Specialized indexes: Pick indexes that fit your data. For example, use graph-based indexes if your chunks connect to each other, like in citation networks or knowledge graphs. Use relational databases if your data is in tables, and filter with SQL queries.
- Hybrid indexes: Combine different indexing methods. For example, use a summary index first, then a graph-based index to explore connections between chunks.
Alignment optimization
Make retrieved chunks more relevant and accurate by matching them to the types of questions they answer. One way is to create a sample question for each chunk that shows what question it answers best. This approach helps in several ways:
- Improved matching: During retrieval, the system compares the user’s question to these sample questions to find the best chunk. This technique improves the relevance of the results.
- Training data for machine learning models: These question-chunk pairs help train the machine learning models in the RAG system. The models learn which chunks answer which types of questions.
- Direct query handling: If a user’s question matches a sample question, the system can quickly find and use the right chunk, speeding up the response.
Each chunk’s sample question acts as a label that guides the retrieval algorithm. The search becomes more focused and aware of context. This method works well when chunks cover many different topics or types of information.
Update strategies
If your organization updates documents often, you need to keep your database current so the retriever can always find the latest information. The retriever component is the part of the system that searches the vector database and returns results. Here are some ways to keep your vector database up to date:
Incremental updates:
- Regular intervals: Set updates to run on a schedule (like daily or weekly) based on how often documents change. This action keeps the database fresh.
- Trigger-based updates: Set up automatic updates when someone adds or changes a document. The system reindexes only the affected parts.
Partial updates:
- Selective reindexing: Update only the parts of the database that changed, not the whole thing. This technique saves time and resources, especially for large datasets.
- Delta encoding: Store just the changes between old and new documents, which reduces the amount of data to process.
Versioning:
- Snapshotting: Save versions of your document set at different times. This action lets you go back or restore earlier versions if needed.
- Document version control: Use a version control system to track changes and keep a history of your documents.
Real-time updates:
- Stream processing: Use stream processing to update the vector database in real time as documents change.
- Live querying: Use live queries to get up-to-date answers, sometimes mixing live data with cached results for speed.
Optimization techniques:
- Batch processing: Group changes and apply them together to save resources and reduce overhead.
- Hybrid approaches: Mix different strategies:
- Use incremental updates for small changes.
- Use full reindexing for significant updates.
- Track and document major changes to your data.
Pick the update strategy or mix that fits your needs. Think about:
- Document corpus size
- Update frequency
- Real-time data needs
- Available resources
Review these factors for your application. Each method has trade-offs in complexity, cost, and how quickly updates show up.
Inference pipeline
Your articles are now chunked, vectorized, and stored in a vector database. Next, focus on getting the best answers from your system.
To get accurate and fast results, think about these key questions:
- Is the user's question clear and likely to get the right answer?
- Does the question break any company rules?
- Can you rewrite the question to help the system find better matches?
- Do the results from the database match the question?
- Should you change the results before sending them to the LLM to make sure the answer is relevant?
- Does the LLM's answer fully address the user's question?
- Does the answer follow your organization's rules?
The whole inference pipeline works in real time. There’s no single right way to set up your preprocessing and post-processing steps. You use a mix of code and LLM calls. One of the biggest trade-offs is balancing accuracy and compliance with cost and speed.
Let’s look at strategies for each stage of the inference pipeline.
Query preprocessing steps
Query preprocessing starts right after the user sends a question:

These steps help make sure the user’s question fits your system and is ready to find the best article chunks using cosine similarity or "nearest neighbor" search.
Policy check: Use logic to spot and remove or flag unwanted content, like personal data, bad language, or attempts to break safety rules (called "jailbreaking").
Query rewriting: Change the question if needed—expand acronyms, remove slang, or rephrase it to focus on bigger ideas (step-back prompting).
A special version of step-back prompting is Hypothetical Document Embeddings (HyDE). HyDE has the LLM answer the question, makes an embedding from that answer, and then searches the vector database with it.
Subqueries
Subqueries break a long or complex question into smaller, easier questions. The system answers each small question, then combines the answers.
For example, if someone asks, "Who made more important contributions to modern physics, Albert Einstein or Niels Bohr?" you can split it into:
- Subquery 1: "What did Albert Einstein contribute to modern physics?"
- Subquery 2: "What did Niels Bohr contribute to modern physics?"
The answers might include:
- For Einstein: the theory of relativity, the photoelectric effect, and E=mc^2.
- For Bohr: the hydrogen atom model, work on quantum mechanics, and the principle of complementarity.
You can then ask follow-up questions:
- Subquery 3: "How did Einstein's theories change modern physics?"
- Subquery 4: "How did Bohr's theories change modern physics?"
These follow-ups look at each scientist’s effect, like:
- How Einstein’s work led to new ideas in cosmology and quantum theory
- How Bohr’s work helped us understand atoms and quantum mechanics
The system combines the answers to give a full response to the original question. This method makes complex questions easier to answer by breaking them into clear, smaller parts.
Query router
Sometimes, your content lives in several databases or search systems. In these cases, use a query router. A query router picks the best database or index to answer each question.
A query router works after the user asks a question but before the system searches for answers.
Here’s how a query router works:
- Query analysis: The LLM or another tool looks at the question to figure out what kind of answer is needed.
- Index selection: The router picks one or more indexes that fit the question. Some indexes are better for facts, others for opinions or special topics.
- Query dispatch: The router sends the question to the chosen index or indexes.
- Results aggregation: The system collects and combines the answers from the indexes.
- Answer generation: The system creates a clear answer using the information it found.
Use different indexes or search engines for:
- Data type specialization: Some indexes focus on news, others on academic papers, or on special databases like medical or legal info.
- Query type optimization: Some indexes are fast for simple facts (like dates), while others handle complex or expert questions.
- Algorithmic differences: Different search engines use different methods, like vector search, keyword search, or advanced semantic search.
For example, in a medical advice system, you might have:
- A research paper index for technical details
- A case study index for real-world examples
- A general health index for basic questions
If someone asks about the effects of a new drug, the router sends the question to the research paper index. If the question is about common symptoms, it uses the general health index for a simple answer.
Post-retrieval processing steps
Post-retrieval processing happens after the system finds content chunks in the vector database:

Next, check if these chunks are useful for the LLM prompt before sending them to the LLM.
Keep these things in mind:
- Extra information can hide the most important details.
- Irrelevant information can make the answer worse.
Watch out for the needle in a haystack problem: LLMs often pay more attention to the start and end of a prompt than the middle.
Also, remember the LLM’s maximum context window and the number of tokens needed for long prompts, especially at scale.
To handle these issues, use a post-retrieval processing pipeline with steps like:
- Filtering results: Only keep chunks that match the query. Ignore the rest when building the LLM prompt.
- Re-ranking: Put the most relevant chunks at the beginning and end of the prompt.
- Prompt compression: Use a small, cheap model to summarize and combine chunks into a single prompt before sending it to the LLM.
Post-completion processing steps
Post-completion processing happens after the user’s question and all content chunks go to the LLM:

After the LLM gives an answer, check its accuracy. A post-completion processing pipeline can include:
- Fact check: Look for statements in the answer that claim to be facts, then check if they’re true. If a fact check fails, you can ask the LLM again or show an error message.
- Policy check: Make sure the answer doesn’t include harmful content for the user or your organization.
Evaluation
Evaluating a system like this is more complex than running regular unit or integration tests. Think about these questions:
- Are users happy with the answers?
- Are the answers accurate?
- How do you collect user feedback?
- Are there rules about what data you can collect?
- Can you see every step the system took when answers are wrong?
- Do you keep detailed logs for root cause analysis?
- How do you update the system without making things worse?
Capturing and acting on feedback from users
Work with your organization's privacy team to design feedback capture tools, system data, and logging for forensics and root cause analysis of a query session.
The next step is to build an assessment pipeline. An assessment pipeline makes it easier and faster to review feedback and find out why the AI gave certain answers. Check every response to see how the AI produced it, if the right content chunks were used, and how the documents were split up.
Also, look for extra preprocessing or post-processing steps that could improve results. This close review often finds content gaps, especially when no good documentation exists for a user's question.
You need an assessment pipeline to handle these tasks at scale. A good pipeline uses custom tools to measure answer quality. It helps you see why the AI gave a specific answer, which documents it used, and how well the inference pipeline worked.
Golden dataset
One way to check how well a RAG chat system works is to use a golden dataset. A golden dataset is a set of questions with approved answers, helpful metadata (like topic and question type), links to source documents, and different ways users might ask the same thing.
A golden dataset shows the "best case scenario." Developers use it to see how well the system works and to run tests when they add new features or updates.
Assessing harm
Harms modeling helps you spot possible risks in a product and plan ways to reduce them.
A harms assessment tool should include these key features:
- Stakeholder identification: Helps you list and group everyone affected by the technology, including direct users, people affected indirectly, future generations, and even the environment.
- Harm categories and descriptions: Lists possible harms, like privacy loss, emotional distress, or economic harm. Guides you through examples and helps you think about both expected and unexpected problems.
- Severity and probability assessments: Helps you judge how serious and likely each harm is, so you can decide what to fix first. You can use data to support your choices.
- Mitigation strategies: Suggests ways to reduce risks, like changing the system design, add safeguards, or use other technology.
- Feedback mechanisms: Lets you collect feedback from stakeholders so you can keep improving the process as you learn more.
- Documentation and reporting: Makes it easy to create reports that show what you found and what you did to reduce risks.
These features help you find and fix risks, and they also help you build more ethical and responsible AI by thinking about all possible impacts from the start.
For more information, see these articles:
Testing and verifying the safeguards
Red-teaming is key—it means to act like an attacker to find weak spots in the system. This step is especially important to stop jailbreaking. For tips on planning and managing red teaming for responsible AI, see Planning red teaming for large language models (LLMs) and their applications.
Developers should test RAG system safeguards in different scenarios to make sure they work. This step makes the system stronger and also helps fine-tune responses to follow ethical standards and rules.
Final considerations for application design
Here are some key things to remember from this article that can help you design your app:
- Generative AI unpredictability
- User prompt changes and their effect on time and cost
- Parallel LLM requests for faster performance
To build a generative AI app, check out Get started with chat by using your own data sample for Python. The tutorial is also available for .NET, Java, and JavaScript.