Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
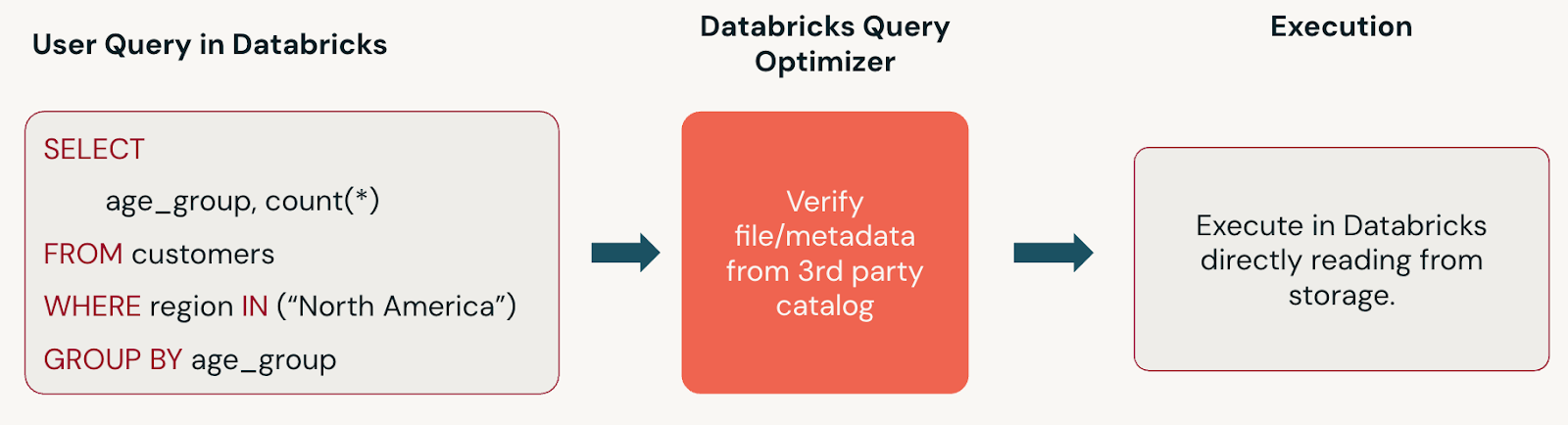
With catalog federation, you directly access the foreign table in object storage. The query is only executed using Databricks compute and is therefore more cost-effective and performance-optimized. Catalog federation is used to federate to platforms that have catalog services and support open table formats like external Hive metastores, legacy Databricks Hive metastores, AWS Glue, Salesforce Data Cloud, and Snowflake.
Common use cases
Common use cases include:
- As a step in the migration path to Unity Catalog, enabling incremental migration without code adaptation, with some of your workloads continuing to use data registered in your external catalog while others are migrated.
- To provide a longer-term hybrid model for organizations that must maintain some data in an external catalog alongside their data that is registered in Unity Catalog.
Overview of catalog federation
With catalog federation, you create a connection from your Databricks workspace to your external catalog, and Unity Catalog crawls the external catalog to populate a foreign catalog, sometimes called a federated catalog, that enables your organization to work with your external catalog tables in Unity Catalog, providing centralized access controls, lineage, search, and more.
Federated external catalogs that are external to your Databricks workspace, including AWS Glue, allow reads using Unity Catalog. Internal Hive metastores allow reads and writes, updating the Hive metastore metadata as well as the Unity Catalog metadata when you modify metadata.
When you query foreign tables in a federated external catalog, Unity Catalog provides the governance layer, performing functions such as access control checks and auditing, while queries are executed using external catalog semantics. For example, if a user queries a table stored in Parquet format in a foreign catalog:
- Unity Catalog checks if the user has access to the table and infers lineage for the query.
- The query itself runs against the underlying external catalog, leveraging the latest metadata and partition information stored there.
What are authorized paths?
When you create a foreign catalog backed by Hive metastore federation, you are prompted to provide authorized paths to the cloud storage where the Hive metastore tables are stored. Any table that you want to access using Hive metastore federation must be covered by these paths. Databricks recommends that your authorized paths be sub-paths that are common across a large number of tables. For example, if you have tables at s3://bucket/table1, s3://bucket/table2, and s3://bucket/table3, you should provide s3://bucket/ as an authorized path.
Authorized paths add an extra layer of security to foreign catalogs backed by Hive metastore federation. They enable the catalog owner to apply guardrails to the data that users can access using federation. This is useful if your Hive metastore allows users to update metadata and arbitrarily alter table locations, updates that would otherwise be synchronized into the foreign catalog. In this scenario, users could potentially redefine tables that they already have access to so that they point to new locations that they would otherwise not have access to.
Example: Unsecured Hive metastore
The following example demonstrates how a malicious user could bypass Unity Catalog permissions and access sensitive data in a federated catalog by manipulating paths in an unsecured Hive metastore.
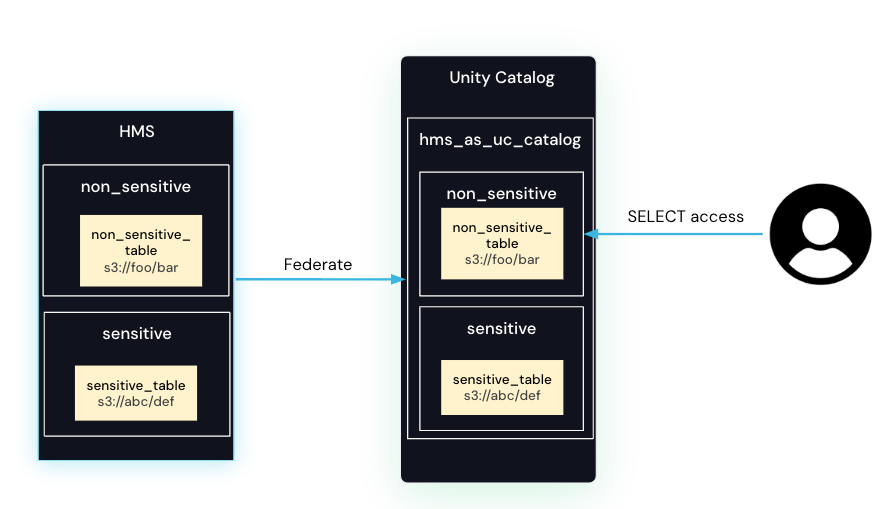
An admin sets up Hive metastore federation and grants Paul access to the non_sensitive schema in Unity Catalog. Paul does not have access to the sensitive_table schema in Unity Catalog.
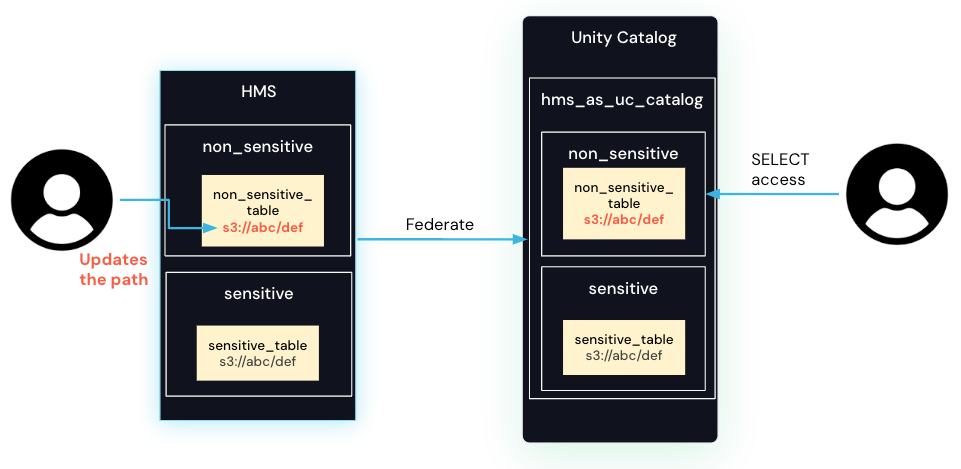
Although Unity Catalog is secure, the Hive metastore is not secure. Paul has the ability to change the path of the table non_sensitive_table in the Hive metastore to s3://abc/def. On the next refresh of the federated catalog, the path of the federated table in Unity Catalog is updated. Because Unity Catalog has a storage credential to access s3://abc/def already, and Paul has SELECT access, Paul can now access the data from the table sensitive_table.
To add authorized paths at scale, you can use the following tools:
Unity Catalog Migration Assistant built-in helper functions
Automation tools like Terraform
Pre-built helper functions in the following notebook:
Authorized paths helper functions