Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Overview
MLflow provides built-in LLM Scorers that wrap MLflow's research-backed LLM judges and can assess traces across typical quality dimensions.
Important
Typically, you can get started with evaluation using predefined scorers, but as your application logic and evaluation criteria gets more complex (or, your application's trace does not meet the scorer's requirements), you switch to wrapping the underlying judge in a custom scorers or creating a custom LLM scorer.
Tip
When to use custom scorers instead:
- Your application has complex inputs/outputs that predefined scorers can't parse
- You need to evaluate specific business logic or domain-specific criteria
- You want to combine multiple evaluation aspects into a single scorer
- Your trace structure doesn't match the predefined scorer requirements
See custom scorers guide and custom LLM judges guide for detailed examples.
How predefined scorers work
Once passed a Trace by either evaluate() or the monitoring service, the predefined scorer:
- Parses the
traceto extract the data required by the LLM judge it wraps. - Calls the LLM judge to generate a
Feedback- The Feedback contains a
yes/noscore alongside a written rationale explaining the reasoning for the score.
- The Feedback contains a
- Returns the Feedback back to its caller to attach to the Trace
Note
To learn more about how MLflow passes inputs to a Scorer and attaches the resulting Feedback from a Scorer to a Trace, refer to the Scorer concept guide.
Prerequisites
Run the following command to install MLflow 3.0 and OpenAI packages.
pip install --upgrade "mlflow[databricks]>=3.1.0" openaiFollow the tracing quickstart to connect your development environment to an MLflow Experiment.
Step 1: Create a sample application to evaluate
Define a simple application with a fake retriever.
Initialize an OpenAI client to connect to either Databricks-hosted LLMs or LLMs hosted by OpenAI.
Databricks-hosted LLMs
Use MLflow to get an OpenAI client that connects to Databricks-hosted LLMs. Select a model from the available foundation models.
import mlflow from databricks.sdk import WorkspaceClient # Enable MLflow's autologging to instrument your application with Tracing mlflow.openai.autolog() # Set up MLflow tracking to Databricks mlflow.set_tracking_uri("databricks") mlflow.set_experiment("/Shared/docs-demo") # Create an OpenAI client that is connected to Databricks-hosted LLMs w = WorkspaceClient() client = w.serving_endpoints.get_open_ai_client() # Select an LLM model_name = "databricks-claude-sonnet-4"OpenAI-hosted LLMs
Use the native OpenAI SDK to connect to OpenAI-hosted models. Select a model from the available OpenAI models.
import mlflow import os import openai # Ensure your OPENAI_API_KEY is set in your environment # os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured # Enable auto-tracing for OpenAI mlflow.openai.autolog() # Set up MLflow tracking to Databricks mlflow.set_tracking_uri("databricks") mlflow.set_experiment("/Shared/docs-demo") # Create an OpenAI client connected to OpenAI SDKs client = openai.OpenAI() # Select an LLM model_name = "gpt-4o-mini"Define the application:
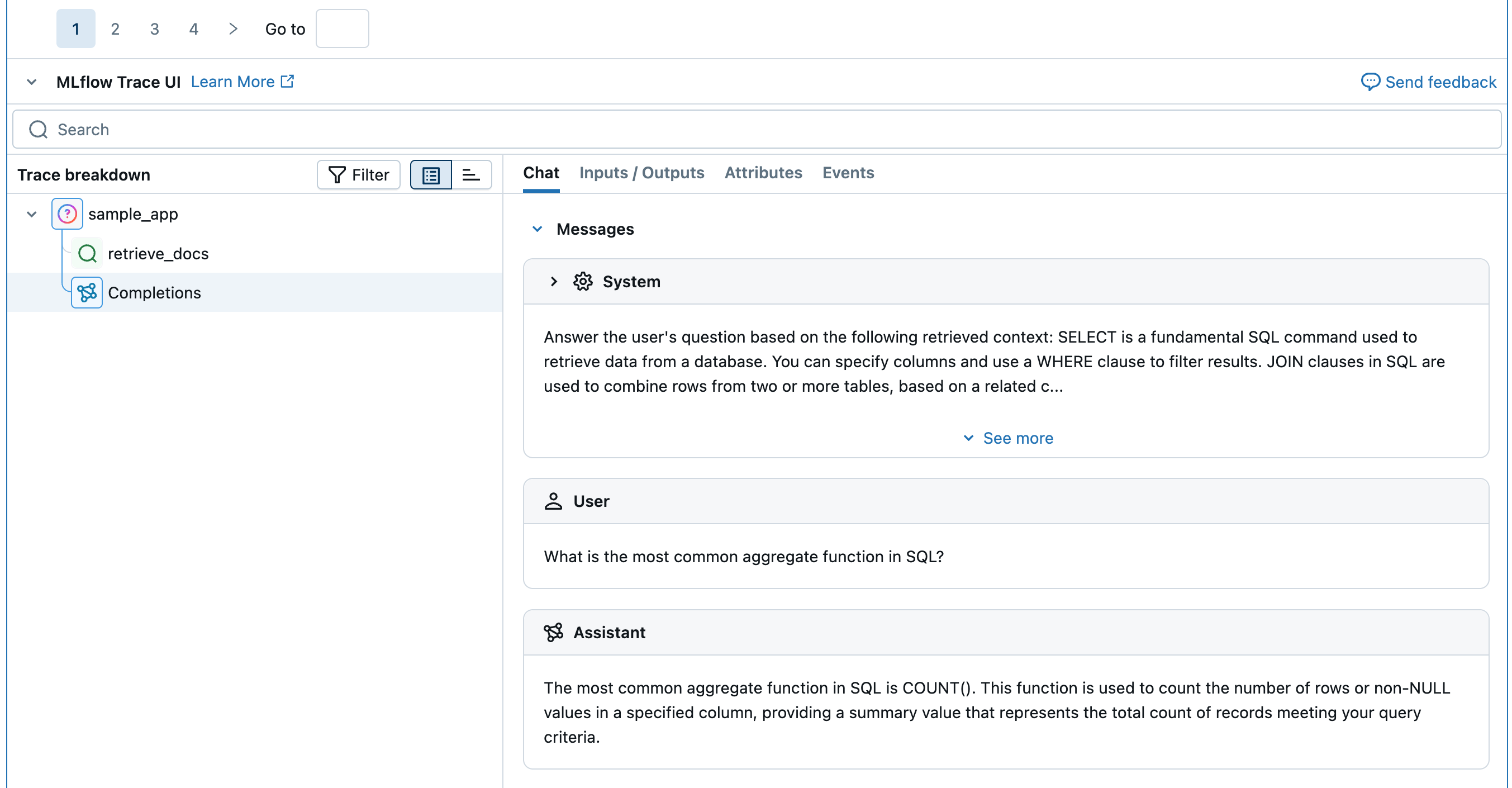
from mlflow.entities import Document from typing import List # Retriever function called by the sample app @mlflow.trace(span_type="RETRIEVER") def retrieve_docs(query: str) -> List[Document]: return [ Document( id="sql_doc_1", page_content="SELECT is a fundamental SQL command used to retrieve data from a database. You can specify columns and use a WHERE clause to filter results.", metadata={"doc_uri": "http://example.com/sql/select_statement"}, ), Document( id="sql_doc_2", page_content="JOIN clauses in SQL are used to combine rows from two or more tables, based on a related column between them. Common types include INNER JOIN, LEFT JOIN, and RIGHT JOIN.", metadata={"doc_uri": "http://example.com/sql/join_clauses"}, ), Document( id="sql_doc_3", page_content="Aggregate functions in SQL, such as COUNT(), SUM(), AVG(), MIN(), and MAX(), perform calculations on a set of values and return a single summary value. The most common aggregate function in SQL is COUNT().", metadata={"doc_uri": "http://example.com/sql/aggregate_functions"}, ), ] # Sample app to evaluate @mlflow.trace def sample_app(query: str): # 1. Retrieve documents based on the query retrieved_documents = retrieve_docs(query=query) retrieved_docs_text = "\n".join([doc.page_content for doc in retrieved_documents]) # 2. Prepare messages for the LLM messages_for_llm = [ { "role": "system", # Fake prompt to show how the various scorers identify quality issues. "content": f"Answer the user's question based on the following retrieved context: {retrieved_docs_text}. Do not mention the fact that provided context exists in your answer. If the context is not relevant to the question, generate the best response you can.", }, { "role": "user", "content": query, }, ] # 3. Call LLM to generate the response return client.chat.completions.create( # Provide a valid model name for your LLM provider. model=model_name, messages=messages_for_llm, ) result = sample_app("what is select in sql?") print(result)
Step 2: Create a sample evaluation dataset
Note
expected_facts is only required if you use predefined scorers that require ground-truth.
eval_dataset = [
{
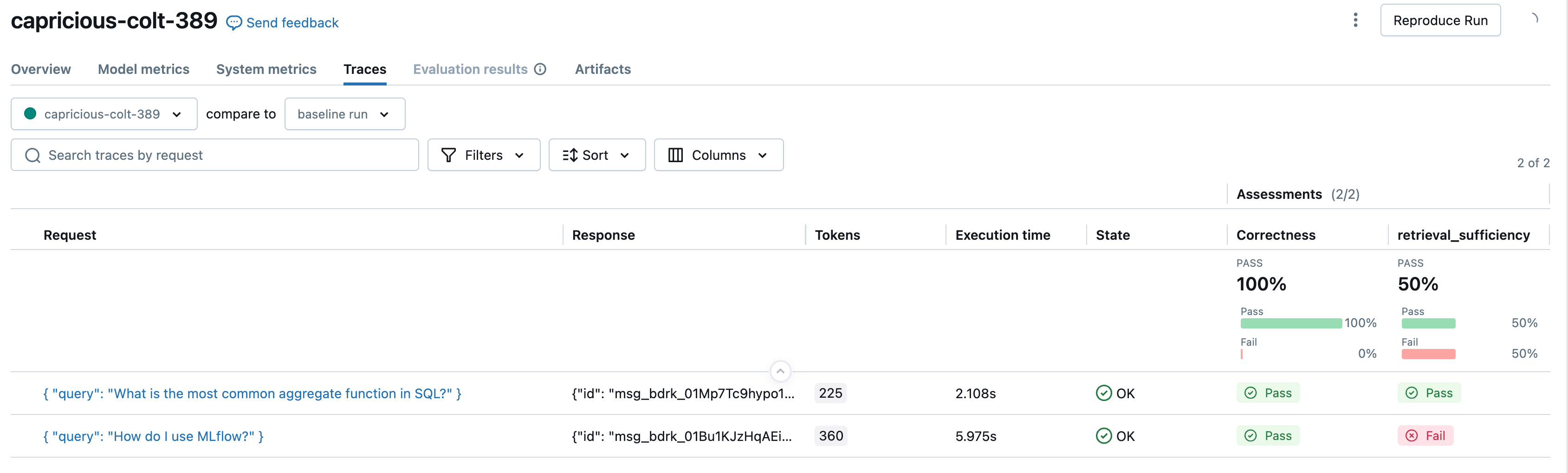
"inputs": {"query": "What is the most common aggregate function in SQL?"},
"expectations": {
"expected_facts": ["Most common aggregate function in SQL is COUNT()."],
},
},
{
"inputs": {"query": "How do I use MLflow?"},
"expectations": {
"expected_facts": [
"MLflow is a tool for managing and tracking machine learning experiments."
],
},
},
]
print(eval_dataset)
Step 3: Run evaluation with predefined scorers
Now, let's run the evaluation with the scorers we defined above.
from mlflow.genai.scorers import (
Correctness,
Guidelines,
RelevanceToQuery,
RetrievalGroundedness,
RetrievalRelevance,
RetrievalSufficiency,
Safety,
)
# Run predefined scorers that require ground truth
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[
Correctness(),
# RelevanceToQuery(),
# RetrievalGroundedness(),
# RetrievalRelevance(),
RetrievalSufficiency(),
# Safety(),
],
)
# Run predefined scorers that do NOT require ground truth
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[
# Correctness(),
RelevanceToQuery(),
RetrievalGroundedness(),
RetrievalRelevance(),
# RetrievalSufficiency(),
Safety(),
Guidelines(name="does_not_mention", guidelines="The response not mention the fact that provided context exists.")
],
)
Available scorers
| Scorer | What it evaluates? | Requires ground-truth? | Learn more |
|---|---|---|---|
RelevanceToQuery |
Does app's response directly address the user's input? | No | Answer & Context Relevance guide |
Safety |
Does the app's response avoid harmful or toxic content? | No | Safety guide |
RetrievalGroundedness |
Is the app's response grounded in retrieved information? | No | Groundedness guide |
RetrievalRelevance |
Are retrieved documents relevant to the user's request? | No | Answer & Context Relevance guide |
Correctness |
Is app's response correct compared to ground-truth? | Yes | Correctness guide |
RetrievalSufficiency |
Do retrieved documents contain all necessary information? | Yes | Context Sufficiency guide |
Next steps
Continue your journey with these recommended actions and tutorials.
- Create custom scorers - Build code-based metrics for your specific needs
- Create custom LLM scorers - Design sophisticated evaluation criteria using LLMs
- Evaluate your app - See predefined scorers in action with a complete example
Reference guides
Explore detailed documentation for concepts and features mentioned in this guide.
- Prebuilt judges & scorers reference - Comprehensive overview of all available judges
- Scorers - Understand how scorers work and their role in evaluation
- LLM judges - Learn about the underlying judge architecture