Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
This feature is currently in public preview. This preview is provided without a service-level agreement, and is not recommended for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
In this article, you learn how to use voice live with generative AI and Azure AI Speech in the Azure AI Foundry portal.
You create and run an application to use voice live directly with generative AI models for real-time voice agents.
Using models directly allows specifying custom instructions (prompts) for each session, offering more flexibility for dynamic or experimental use cases.
Models may be preferable when you want fine-grained control over session parameters or need to frequently adjust the prompt or configuration without updating an agent in the portal.
The code for model-based sessions is simpler in some respects, as it does not require managing agent IDs or agent-specific setup.
Direct model use is suitable for scenarios where agent-level abstraction or built-in logic is unnecessary.
To instead use the voice live API with agents, see the voice live agents quickstart.
Prerequisites
- An Azure subscription. Create one for free.
- An Azure AI Foundry resource created in one of the supported regions. For more information about region availability, see the voice live overview documentation.
Tip
To use voice live, you don't need to deploy an audio model with your Azure AI Foundry resource. Voice live is fully managed, and the model is automatically deployed for you. For more information about models availability, see the voice live overview documentation.
Try out voice live in the Speech playground
To try out the voice live demo, follow these steps:
Go to your project in Azure AI Foundry.
Select Playgrounds from the left pane.
In the Speech playground tile, select Try the Speech playground.
Select Speech capabilities by scenario > Voice live.
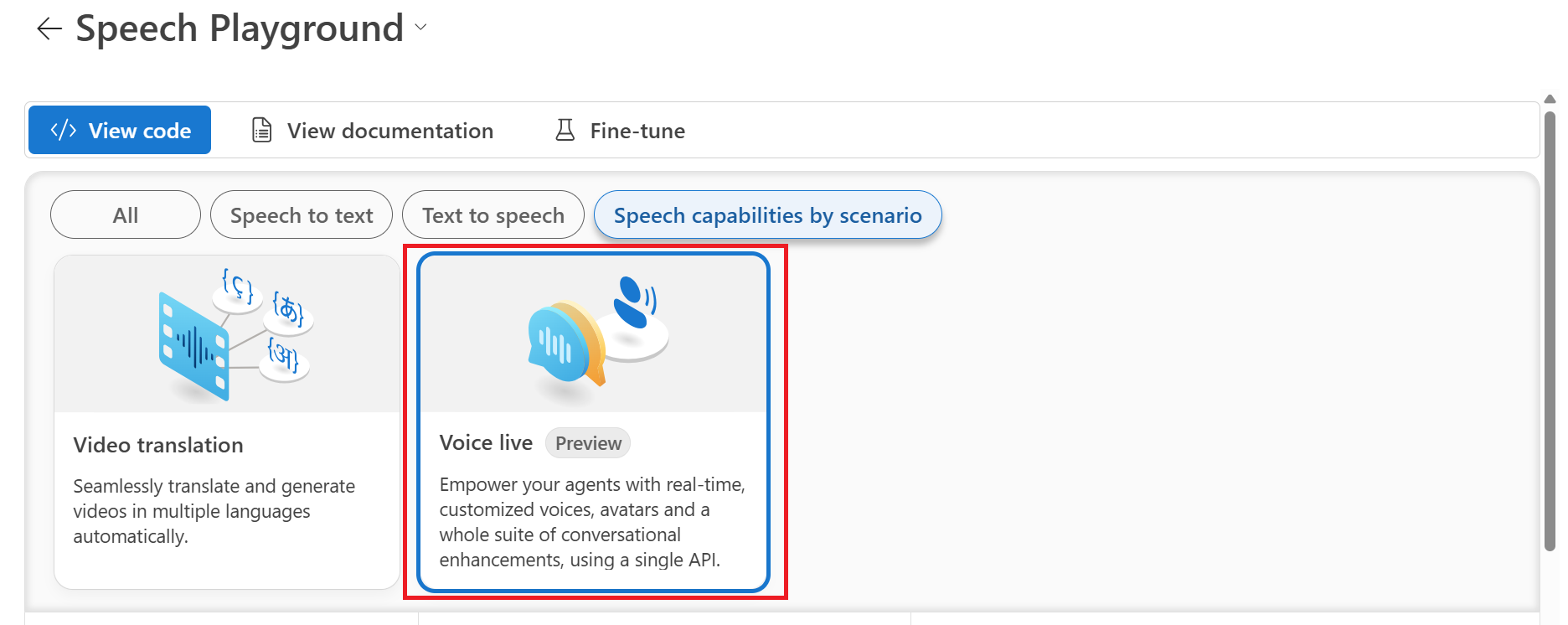
Select a sample scenario, such as Casual chat.
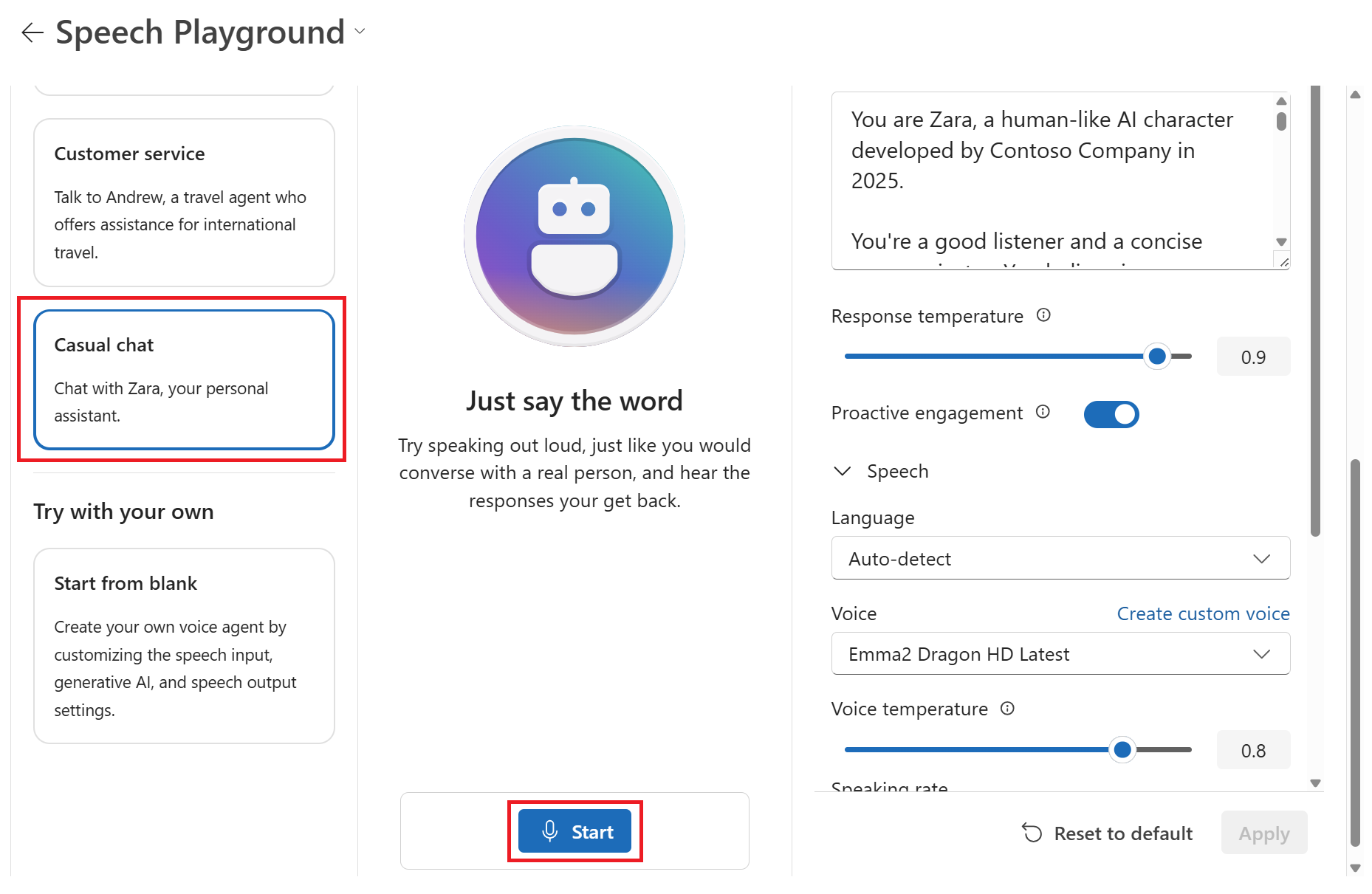
Select Start to start chatting with the chat agent.
Select End to end the chat session.
Select a new generative AI model from the drop-down list via Configuration > GenAI > Generative AI model.
Note
You can also select an agent that you configured in the Agents playground. For more information, see the voice live with Foundry agents quickstart.
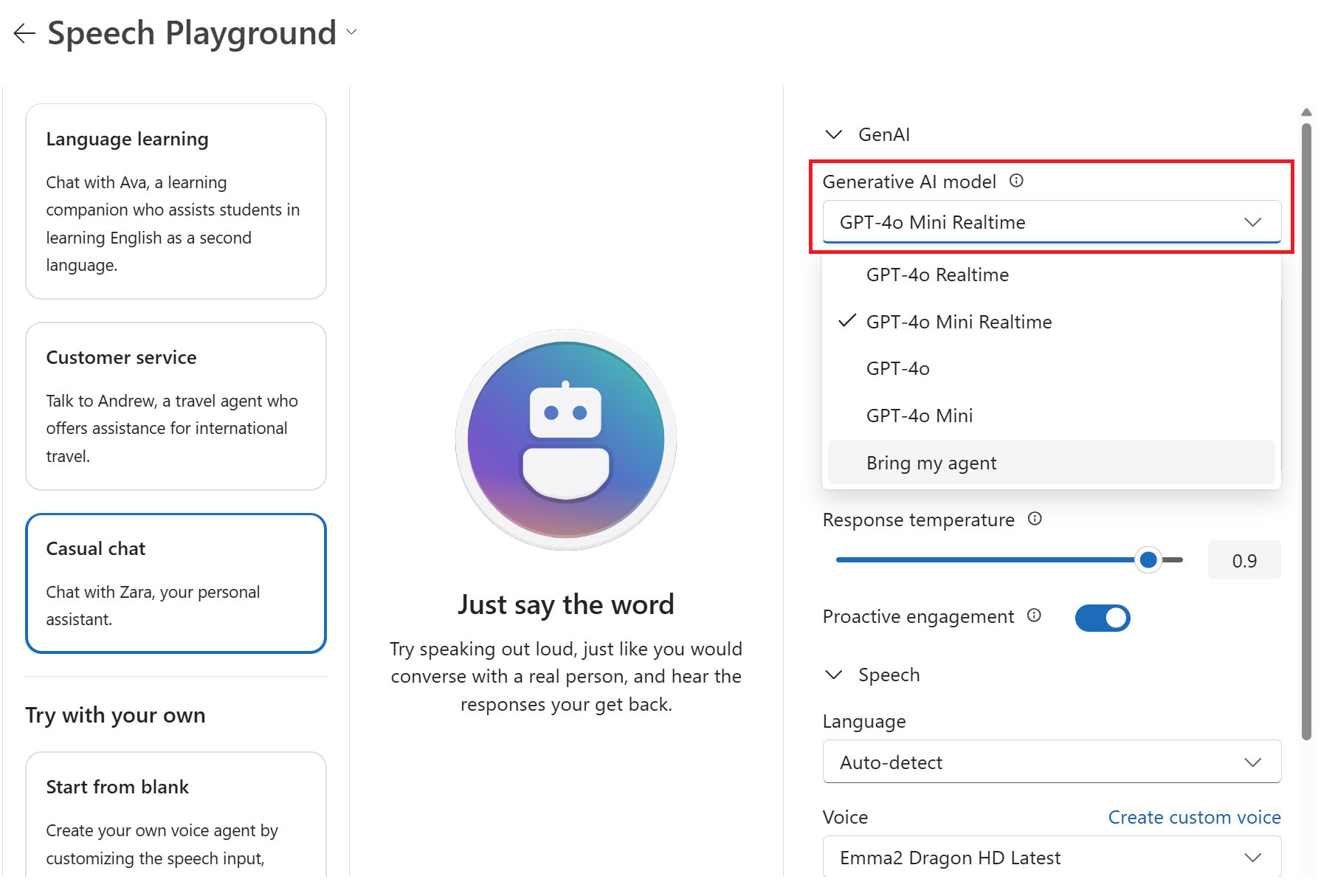
Edit other settings as needed, such as the Response instructions, Voice, and Speaking rate.
Select Start to start speaking again and select End to end the chat session.



In this article, you learn how to use Azure AI Speech voice live with Azure AI Foundry models using Python code.
You create and run an application to use voice live directly with generative AI models for real-time voice agents.
Using models directly allows specifying custom instructions (prompts) for each session, offering more flexibility for dynamic or experimental use cases.
Models may be preferable when you want fine-grained control over session parameters or need to frequently adjust the prompt or configuration without updating an agent in the portal.
The code for model-based sessions is simpler in some respects, as it does not require managing agent IDs or agent-specific setup.
Direct model use is suitable for scenarios where agent-level abstraction or built-in logic is unnecessary.
To instead use the voice live API with agents, see the voice live agents quickstart.
Prerequisites
- An Azure subscription. Create one for free.
- Python 3.10 or later version. If you don't have a suitable version of Python installed, you can follow the instructions in the VS Code Python Tutorial for the easiest way of installing Python on your operating system.
- An Azure AI Foundry resource created in one of the supported regions. For more information about region availability, see the voice live overview documentation.
Tip
To use voice live, you don't need to deploy an audio model with your Azure AI Foundry resource. Voice live is fully managed, and the model is automatically deployed for you. For more information about models availability, see the voice live overview documentation.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
voice-live-quickstartand go to the quickstart folder with the following command:mkdir voice-live-quickstart && cd voice-live-quickstartCreate a virtual environment. If you already have Python 3.10 or higher installed, you can create a virtual environment using the following commands:
Activating the Python environment means that when you run
pythonorpipfrom the command line, you then use the Python interpreter contained in the.venvfolder of your application. You can use thedeactivatecommand to exit the python virtual environment, and can later reactivate it when needed.Tip
We recommend that you create and activate a new Python environment to use to install the packages you need for this tutorial. Don't install packages into your global python installation. You should always use a virtual or conda environment when installing python packages, otherwise you can break your global installation of Python.
Create a file named requirements.txt. Add the following packages to the file:
aiohttp==3.11.18 azure-core==1.34.0 azure-identity==1.22.0 certifi==2025.4.26 cffi==1.17.1 cryptography==44.0.3 numpy==2.2.5 pycparser==2.22 python-dotenv==1.1.0 requests==2.32.3 sounddevice==0.5.1 typing_extensions==4.13.2 urllib3==2.4.0 websocket-client==1.8.0Install the packages:
pip install -r requirements.txtFor the recommended keyless authentication with Microsoft Entra ID, install the
azure-identitypackage with:pip install azure-identity
Retrieve resource information
Create a new file named .env in the folder where you want to run the code.
In the .env file, add the following environment variables for authentication:
AZURE_VOICE_LIVE_ENDPOINT=<your_endpoint>
VOICE_LIVE_MODEL=<your_model>
AZURE_VOICE_LIVE_API_VERSION=2025-05-01-preview
AZURE_VOICE_LIVE_API_KEY=<your_api_key> # Only required if using API key authentication
Replace the default values with your actual endpoint, model, API version, and API key.
| Variable name | Value |
|---|---|
AZURE_VOICE_LIVE_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_VOICE_LIVE_MODEL |
The model you want to use. For example, gpt-4o or gpt-4o-mini-realtime-preview. For more information about models availability, see the Voice Live API overview documentation. |
AZURE_VOICE_LIVE_API_VERSION |
The API version you want to use. For example, 2025-05-01-preview. |
Learn more about keyless authentication and setting environment variables.
Start a conversation
The sample code in this quickstart uses Microsoft Entra ID for the recommended keyless authentication. If you prefer to use an API key, you can set the api_key variable instead of the token variable.
client = AzureVoiceLive(
azure_endpoint = endpoint,
api_version = api_version,
token = token.token,
# api_key = api_key,
)
Create the
voice-live-quickstart.pyfile with the following code:#Speech example to test the Azure Voice Live API import os import uuid import json import time import base64 import logging import threading import numpy as np import sounddevice as sd import queue import signal import sys from collections import deque from dotenv import load_dotenv from azure.core.credentials import TokenCredential from azure.identity import DefaultAzureCredential from typing import Dict, Union, Literal, Set from typing_extensions import Iterator, TypedDict, Required import websocket from websocket import WebSocketApp from datetime import datetime # Global variables for thread coordination stop_event = threading.Event() connection_queue = queue.Queue() # This is the main function to run the Voice Live API client. def main() -> None: # Set environment variables or edit the corresponding values here. endpoint = os.environ.get("AZURE_VOICE_LIVE_ENDPOINT") or "<https://your-endpoint.azure.com/>" model = os.environ.get("AZURE_VOICE_LIVE_MODEL") or "<your_model>" api_version = os.environ.get("AZURE_VOICE_LIVE_API_VERSION") or "2025-05-01-preview" api_key = os.environ.get("AZURE_VOICE_LIVE_API_KEY") or "<your_api_key>" # For the recommended keyless authentication, get and # use the Microsoft Entra token instead of api_key: credential = DefaultAzureCredential() scopes = "https://ai.azure.com/.default" token = credential.get_token(scopes) client = AzureVoiceLive( azure_endpoint = endpoint, api_version = api_version, token = token.token, # api_key = api_key, ) connection = client.connect(model = model) session_update = { "type": "session.update", "session": { "instructions": "You are a helpful AI assistant responding in natural, engaging language.", "turn_detection": { "type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": False, "end_of_utterance_detection": { "model": "semantic_detection_v1", "threshold": 0.01, "timeout": 2, }, }, "input_audio_noise_reduction": { "type": "azure_deep_noise_suppression" }, "input_audio_echo_cancellation": { "type": "server_echo_cancellation" }, "voice": { "name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8, }, }, "event_id": "" } connection.send(json.dumps(session_update)) print("Session created: ", json.dumps(session_update)) # Create and start threads send_thread = threading.Thread(target=listen_and_send_audio, args=(connection,)) receive_thread = threading.Thread(target=receive_audio_and_playback, args=(connection,)) keyboard_thread = threading.Thread(target=read_keyboard_and_quit) print("Starting the chat ...") send_thread.start() receive_thread.start() keyboard_thread.start() # Wait for any thread to complete (usually the keyboard thread when user quits) keyboard_thread.join() # Signal other threads to stop stop_event.set() # Wait for other threads to finish send_thread.join(timeout=2) receive_thread.join(timeout=2) connection.close() print("Chat done.") # --- End of Main Function --- logger = logging.getLogger(__name__) AUDIO_SAMPLE_RATE = 24000 class VoiceLiveConnection: def __init__(self, url: str, headers: dict) -> None: self._url = url self._headers = headers self._ws = None self._message_queue = queue.Queue() self._connected = False def connect(self) -> None: def on_message(ws, message): self._message_queue.put(message) def on_error(ws, error): logger.error(f"WebSocket error: {error}") def on_close(ws, close_status_code, close_msg): logger.info("WebSocket connection closed") self._connected = False def on_open(ws): logger.info("WebSocket connection opened") self._connected = True self._ws = websocket.WebSocketApp( self._url, header=self._headers, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open ) # Start WebSocket in a separate thread self._ws_thread = threading.Thread(target=self._ws.run_forever) self._ws_thread.daemon = True self._ws_thread.start() # Wait for connection to be established timeout = 10 # seconds start_time = time.time() while not self._connected and time.time() - start_time < timeout: time.sleep(0.1) if not self._connected: raise ConnectionError("Failed to establish WebSocket connection") def recv(self) -> str: try: return self._message_queue.get(timeout=1) except queue.Empty: return None def send(self, message: str) -> None: if self._ws and self._connected: self._ws.send(message) def close(self) -> None: if self._ws: self._ws.close() self._connected = False class AzureVoiceLive: def __init__( self, *, azure_endpoint: str | None = None, api_version: str | None = None, token: str | None = None, api_key: str | None = None, ) -> None: self._azure_endpoint = azure_endpoint self._api_version = api_version self._token = token self._api_key = api_key self._connection = None def connect(self, model: str) -> VoiceLiveConnection: if self._connection is not None: raise ValueError("Already connected to the Voice Live API.") if not model: raise ValueError("Model name is required.") azure_ws_endpoint = self._azure_endpoint.rstrip('/').replace("https://", "wss://") url = f"{azure_ws_endpoint}/voice-live/realtime?api-version={self._api_version}&model={model}" auth_header = {"Authorization": f"Bearer {self._token}"} if self._token else {"api-key": self._api_key} request_id = uuid.uuid4() headers = {"x-ms-client-request-id": str(request_id), **auth_header} self._connection = VoiceLiveConnection(url, headers) self._connection.connect() return self._connection class AudioPlayerAsync: def __init__(self): self.queue = deque() self.lock = threading.Lock() self.stream = sd.OutputStream( callback=self.callback, samplerate=AUDIO_SAMPLE_RATE, channels=1, dtype=np.int16, blocksize=2400, ) self.playing = False def callback(self, outdata, frames, time, status): if status: logger.warning(f"Stream status: {status}") with self.lock: data = np.empty(0, dtype=np.int16) while len(data) < frames and len(self.queue) > 0: item = self.queue.popleft() frames_needed = frames - len(data) data = np.concatenate((data, item[:frames_needed])) if len(item) > frames_needed: self.queue.appendleft(item[frames_needed:]) if len(data) < frames: data = np.concatenate((data, np.zeros(frames - len(data), dtype=np.int16))) outdata[:] = data.reshape(-1, 1) def add_data(self, data: bytes): with self.lock: np_data = np.frombuffer(data, dtype=np.int16) self.queue.append(np_data) if not self.playing and len(self.queue) > 0: self.start() def start(self): if not self.playing: self.playing = True self.stream.start() def stop(self): with self.lock: self.queue.clear() self.playing = False self.stream.stop() def terminate(self): with self.lock: self.queue.clear() self.stream.stop() self.stream.close() def listen_and_send_audio(connection: VoiceLiveConnection) -> None: logger.info("Starting audio stream ...") stream = sd.InputStream(channels=1, samplerate=AUDIO_SAMPLE_RATE, dtype="int16") try: stream.start() read_size = int(AUDIO_SAMPLE_RATE * 0.02) while not stop_event.is_set(): if stream.read_available >= read_size: data, _ = stream.read(read_size) audio = base64.b64encode(data).decode("utf-8") param = {"type": "input_audio_buffer.append", "audio": audio, "event_id": ""} # print("sending - ", param) data_json = json.dumps(param) connection.send(data_json) else: time.sleep(0.001) # Small sleep to prevent busy waiting except Exception as e: logger.error(f"Audio stream interrupted. {e}") finally: stream.stop() stream.close() logger.info("Audio stream closed.") def receive_audio_and_playback(connection: VoiceLiveConnection) -> None: last_audio_item_id = None audio_player = AudioPlayerAsync() logger.info("Starting audio playback ...") try: while not stop_event.is_set(): raw_event = connection.recv() if raw_event is None: continue try: event = json.loads(raw_event) print(f"Received event:", {event.get("type")}) if event.get("type") == "session.created": session = event.get("session") logger.info(f"Session created: {session.get('id')}") elif event.get("type") == "response.audio.delta": if event.get("item_id") != last_audio_item_id: last_audio_item_id = event.get("item_id") bytes_data = base64.b64decode(event.get("delta", "")) if bytes_data: logger.debug(f"Received audio data of length: {len(bytes_data)}") audio_player.add_data(bytes_data) elif event.get("type") == "input_audio_buffer.speech_started": print("Speech started") audio_player.stop() elif event.get("type") == "error": error_details = event.get("error", {}) error_type = error_details.get("type", "Unknown") error_code = error_details.get("code", "Unknown") error_message = error_details.get("message", "No message provided") raise ValueError(f"Error received: Type={error_type}, Code={error_code}, Message={error_message}") except json.JSONDecodeError as e: logger.error(f"Failed to parse JSON event: {e}") continue except Exception as e: logger.error(f"Error in audio playback: {e}") finally: audio_player.terminate() logger.info("Playback done.") def read_keyboard_and_quit() -> None: print("Press 'q' and Enter to quit the chat.") while not stop_event.is_set(): try: user_input = input() if user_input.strip().lower() == 'q': print("Quitting the chat...") stop_event.set() break except EOFError: # Handle case where input is interrupted break if __name__ == "__main__": try: # Change to the directory where this script is located os.chdir(os.path.dirname(os.path.abspath(__file__))) # Add folder for logging if not os.path.exists('logs'): os.makedirs('logs') # Add timestamp for logfiles timestamp = datetime.now().strftime("%Y-%m-%d_%H-%M-%S") # Set up logging logging.basicConfig( filename=f'logs/{timestamp}_voicelive.log', filemode="w", level=logging.DEBUG, format='%(asctime)s:%(name)s:%(levelname)s:%(message)s' ) # Load environment variables from .env file load_dotenv("./.env", override=True) # Set up signal handler for graceful shutdown def signal_handler(signum, frame): print("\nReceived interrupt signal, shutting down...") stop_event.set() sys.exit(0) signal.signal(signal.SIGINT, signal_handler) signal.signal(signal.SIGTERM, signal_handler) main() except Exception as e: print(f"Error: {e}") stop_event.set()Sign in to Azure with the following command:
az loginRun the Python file.
python voice-live-quickstart.pyThe Voice Live API starts to return audio with the model's initial response. You can interrupt the model by speaking. Enter "q" to quit the conversation.
Output
The output of the script is printed to the console. You see messages indicating the status of the connection, audio stream, and playback. The audio is played back through your speakers or headphones.
Session created: {"type": "session.update", "session": {"instructions": "You are a helpful AI assistant responding in natural, engaging language.","turn_detection": {"type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": false, "end_of_utterance_detection": {"model": "semantic_detection_v1", "threshold": 0.1, "timeout": 4}}, "input_audio_noise_reduction": {"type": "azure_deep_noise_suppression"}, "input_audio_echo_cancellation": {"type": "server_echo_cancellation"}, "voice": {"name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8}}, "event_id": ""}
Starting the chat ...
Received event: {'session.created'}
Press 'q' and Enter to quit the chat.
Received event: {'session.updated'}
Received event: {'input_audio_buffer.speech_started'}
Received event: {'input_audio_buffer.speech_stopped'}
Received event: {'input_audio_buffer.committed'}
Received event: {'conversation.item.input_audio_transcription.completed'}
Received event: {'conversation.item.created'}
Received event: {'response.created'}
Received event: {'response.output_item.added'}
Received event: {'conversation.item.created'}
Received event: {'response.content_part.added'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
q
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Quitting the chat...
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Chat done.
The script that you ran creates a log file named <timestamp>_voicelive.log in the logs folder.
logging.basicConfig(
filename=f'logs/{timestamp}_voicelive.log',
filemode="w",
level=logging.DEBUG,
format='%(asctime)s:%(name)s:%(levelname)s:%(message)s'
)
The log file contains information about the connection to the Voice Live API, including the request and response data. You can view the log file to see the details of the conversation.
2025-05-09 06:56:06,821:websockets.client:DEBUG:= connection is CONNECTING
2025-05-09 06:56:07,101:websockets.client:DEBUG:> GET /voice-live/realtime?api-version=2025-05-01-preview&model=gpt-4o HTTP/1.1
<REDACTED FOR BREVITY>
2025-05-09 06:56:07,551:websockets.client:DEBUG:= connection is OPEN
2025-05-09 06:56:07,551:websockets.client:DEBUG:< TEXT '{"event_id":"event_5a7NVdtNBVX9JZVuPc9nYK","typ...es":null,"agent":null}}' [1475 bytes]
2025-05-09 06:56:07,552:websockets.client:DEBUG:> TEXT '{"type": "session.update", "session": {"turn_de....8}}, "event_id": null}' [551 bytes]
2025-05-09 06:56:07,557:__main__:INFO:Starting audio stream ...
2025-05-09 06:56:07,810:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,824:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,844:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,905:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,926:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...///7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,974:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,004:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
<REDACTED FOR BREVITY>
2025-05-09 06:56:42,957:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:42,984:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,005:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,055:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,084:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...9//3/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...DAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,134:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,165:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,184:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+//7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,245:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,264:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:43,297:websockets.client:DEBUG:= connection is CLOSING
2025-05-09 06:56:43,346:__main__:INFO:Audio stream closed.
2025-05-09 06:56:43,388:__main__:INFO:Playback done.
2025-05-09 06:56:44,512:websockets.client:DEBUG:< CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:44,514:websockets.client:DEBUG:< EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:> EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:= connection is CLOSED
2025-05-09 06:56:44,514:websockets.client:DEBUG:x closing TCP connection
2025-05-09 06:56:44,514:asyncio:ERROR:Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x00000266DD8E5400>
Related content
- Try the Voice live agents quickstart
- Learn more about How to use the voice live API
- See the audio events reference