Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Azure AI Content Understanding is available in preview. Public preview releases provide early access to features that are in active development. Features, approaches, and processes can change or have limited capabilities before general availability. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Content Understanding offers sophisticated document analysis capabilities. Organizations can use these capabilities to convert unstructured content into actionable and organized data. Content Understanding can use customizable analyzers to expertly extract essential information, fields, and relationships from a diverse range of documents and forms.
Business use cases
Document analyzers can process complex documents in various formats and templates:
- Contract lifecycle management: Extract key fields, clauses, and obligations from various contract types.
- Loan and mortgage applications: Automate processing to enable quicker handling by banks, lenders, and government entities.
- Financial services: Analyze complex documents like financial reports and asset management reports.
- Expense management: Parse receipts and invoices from various retailers to validate expenses across different formats and templates.
- Document sets and knowledge base scenarios: Extract key fields from document sets as a whole. Add reference data that handles tasks like validation and enrichment by applying multistep reasoning.
Document analyzer capabilities
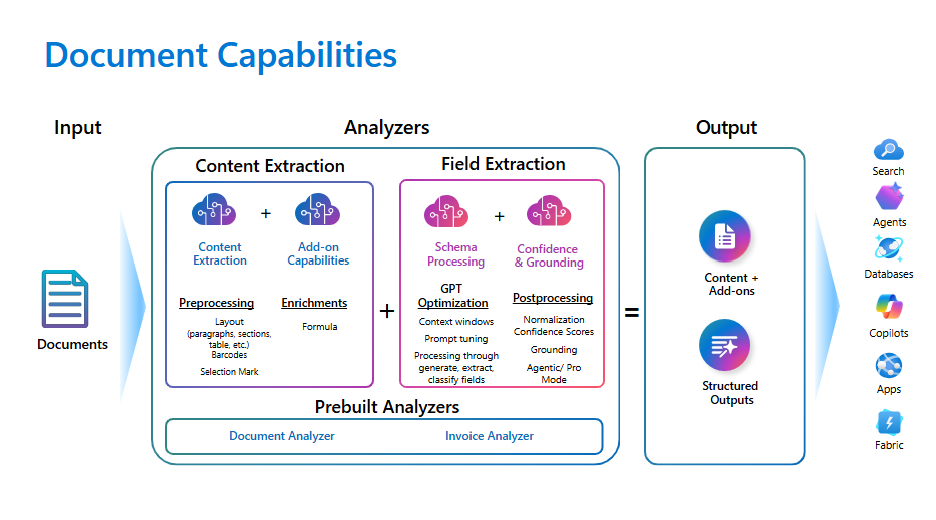
Content extraction
Content extraction forms the foundation of Content Understanding document analysis capabilities. This process transforms unstructured documents into structured, machine-readable data. Content extraction precisely captures printed and handwritten text while it preserves the document's structure through advanced layout analysis:
- Content analysis
- Text: Processes multilingual content, including both machine-printed and handwritten text from hundreds of languages.
- Selection marks: Identifies and extracts selection indicators such as checkboxes, buttons, and similar markers.
- Barcode detection: Scans and decodes information from over a dozen types of linear and two-dimensional barcodes.
- Mathematical formulas: Captures and preserves complex mathematical expressions in LaTeX format.
- Image elements: Locates and extracts images, diagrams, and charts along with their related captions and annotations.
- Structure analysis
- Paragraphs: Detects and categorizes text segments based on their document context and role.
- Tabular data: Recognizes and extracts table structures, including complex formats with spanning cells and multipage layouts.
- Hierarchical sections: Maps content organization through section headers and nested content relationships.
- Retrieval-augmented generation (RAG)
- RAG solutions: Content extraction forms the foundation of effective RAG systems by transforming raw multimodal data into structured, searchable formats that are optimized for retrieval. To learn more about building RAG solutions, see Retrieval-augmented generation.
Field extraction
With field extraction, you can extract, classify, and generate structured data from various documents and forms that are customized to meet your requirements. The process of transforming unstructured content into organized, actionable information simplifies data management, improves searchability, and supports automated workflows.
For instance, you can seamlessly extract customer details, billing addresses, and itemized charges from invoices. You can also identify contractual parties, renewal dates, and payment terms in legal agreements. To maximize efficiency, you can use prebuilt analyzer templates, such as templates that are tailored for invoices. You can also design bespoke analyzers from scratch to enhance precision through the labeling of more sample documents.
The confidence and grounding API is an opt-in feature. To opt in for confidence and grounding for field extraction, set estimateFieldSourceAndConfidence as true.
Field extraction methods
Content Understanding provides versatile methods for field extraction, which enables precise and tailored processing of document content:
- Extract: Extract specific data, like transaction dates from receipts or line items from invoices, for precise and focused information capture.
- Classify: Categorize document content into predefined categories, such as classifying sentiment in customer call transcripts or classifying hotel receipt items.
- Generate: Produce new insights or summaries from your documents, including document summaries, and chapter overviews to enhance content accessibility and comprehension.
Key benefits
Content Understanding delivers powerful document analysis capabilities that are designed to address critical enterprise and business scenarios, such as RAG and robotic process automation. Key benefits include:
- Intelligent search enablement: Transform unstructured documents into structured, searchable data assets to improve information discoverability and accessibility across your organization.
- Grounded data extraction: Maintain clear traceability and localization of extracted data to facilitate efficient human-in-the-loop review processes and ensure transparency and compliance.
- Confidence-driven automation: Use built-in confidence scoring to intelligently automate document processing tasks to help you optimize resource allocation, reduce operational costs, and enhance decision-making accuracy.
- Flexible customization: Easily adapt and tailor document analyzers to align with specific business processes and workflows. Customization enables precise extraction and classification tailored to your organization's specific requirements.
- Enhanced accuracy and reliability: Achieve precise extraction and classification of critical business data to reduce errors and improve operational efficiency across automated workflows.
- Agents ready: Process your diverse input and deliver output in a standard format that's ready for an agent's workflow. Outputs can give your application an understanding of user intent, with data supported by a
strongly-typedschema that makes it easier to quickly get data in a format ready for your code.
Input requirements
For more information on supported input document formats, see Service quotas and limits.
Supported languages and regions
For a list of supported languages and regions, see Language and region support.
Data privacy and security
Developers who use Content Understanding should review the Microsoft policies on customer data. For more information, see Data, protection, and privacy.
Related content
- Try processing your document content by using Content Understanding in Azure AI Foundry.
- Learn to analyze document content analyzer templates.
- Review code samples with visual document search.