Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Azure AI Content Understanding is available in preview. Public preview releases provide early access to features that are in active development. Features, approaches, and processes can change or have limited capabilities before general availability. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Overview
Azure AI Content Understanding analysis capabilities help you transform unstructured data into structured, machine-readable information. By precisely identifying and extracting elements while preserving their structural relationships, you can build powerful processing workflows for a wide range of applications.
The contents object with the kind document supports output for a range of different input files, including document, image, text, and structured files. You can use these outputs to extract meaningful content from your files, preserve document structures, and unlock the full potential of your data.
The document content kind includes output for input files like:
- Documents: PDFs, Word documents, PowerPoint presentations, and Excel spreadsheets
- Figures: Photos, scanned documents, charts, and diagrams
- Text files: Plain text, HTML, Markdown, and RTF
- Structured content: XML, JSON, CSV, and TSV files
- Email: EML and MSG message formats
For more information about supported file types, file size limits, and other constraints, see Service quotas and limits.
JSON response structure
The Content Understanding API returns analysis results in a structured JSON format. Here's the overall container structure:
{
"id": "10a01d32-e21e-46e3-bb5c-361375f184de",
"status": "Succeeded",
"result": {
"analyzerId": "my-analyzer",
"apiVersion": "2025-05-01-preview",
"createdAt": "2025-06-18T22:50:34Z",
"warnings": [],
"contents": [
{
"markdown": "# Example Document\n\n...",
"fields": { /* extracted field values */ },
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 2,
"unit": "inch",
"pages": [ /* page-level elements */ ],
"paragraphs": [ /* paragraph elements */ ],
"sections": [ /* section elements */ ],
"tables": [ /* table elements */ ],
"figures": [ /* figure elements */ ]
}
]
}
}
Document elements
You can extract the following document elements through content extraction:
- Markdown
- Content elements
- Layout elements
Not all content and layout elements are applicable or currently supported by all document file types.
Markdown content elements
Content Understanding generates richly formatted Markdown that preserves the original document's structure. For this reason, large language models can better comprehend document context and hierarchical relationships for AI-powered analysis and generation tasks. In addition to words, selection marks, barcodes, formulas, and images as content, the Markdown also includes sections, tables, and page metadata for both visual rendering and machine processing. Learn more about how Content Understanding represents content and layout elements in Markdown.
Words
A word is a content element composed of a sequence of characters. Unicode Standard Annex #29 defines the word boundaries. For Latin languages, words might be split from punctuation even without intervening spaces. In some languages, such as Chinese, supplemental word dictionaries are used to enable word breaking at semantic boundaries. For more information, see Boundary analysis.
JSON example:
{
"words": [
{
"content": "Example",
"span": {
"length": 7
},
"confidence": 0.992,
"source": "D(1,1.265,1.0836,2.4972,1.0816,2.4964,1.4117,1.2645,1.4117)"
}
]
}

Selection marks
A selection mark is a content element that represents a visual glyph that indicates the state of a selection. Selection marks might appear in the document as checkboxes, check marks, or buttons. You can select or clear a selection mark, with different visual representation to indicate the state. Selection marks are encoded as words in the document analysis result by using the Unicode characters ☒ (selected) and ☐ (cleared).
Content Understanding detects check marks inside a table cell as selection marks in the selected state. It doesn't detect empty table cells as selection marks in the cleared state.
JSON example:
{
"words": [
{
"content": "☒",
"span": {
"length": 1
},
"confidence": 0.983,
"source": "D(1,1.258,2.7952,1.3705,2.7949,1.371,2.9098,1.2575,2.9089)"
}
]
}

Barcodes
A barcode is a content element that describes both linear (for example, UPC or EAN) and two-dimensional (for example, QR or MaxiCode) barcodes. Content Understanding represents barcodes by using its detected type and extracted value. The following barcode formats are currently supported:
| Barcode type | Description |
|---|---|
QRCode |
QR code, as defined in ISO/IEC 18004:2015 |
PDF417 |
PDF417, as defined in ISO 15438 |
UPCA |
GS1 12-digit Universal Product Code |
UPCE |
GS1 6-digit Universal Product Code |
Code39 |
Code 39 barcode, as defined in ISO/IEC 16388:2007 |
Code128 |
Code 128 barcode, as defined in ISO/IEC 15417:2007 |
EAN8 |
GS1 8-digit International Article Number (European Article Number) |
EAN13 |
GS1 13-digit International Article Number (European Article Number) |
DataBar |
GS1 DataBar barcode |
Code93 |
Code 93 barcode, as defined in ANSI/AIM BC5-1995 |
Codabar |
Codabar barcode, as defined in ANSI/AIM BC3-1995 |
DataBarExpanded |
GS1 DataBar Expanded barcode |
ITF |
"Interleaved 2 of 5 barcode (ITF)" as defined in ANSI/AIM BC2-1995 |
MicroQRCode |
Micro QR code, as defined in ISO/IEC 23941:2022 |
Aztec |
Aztec code, as defined in ISO/IEC 24778:2008 |
DataMatrix |
Data matrix code, as defined in ISO/IEC 16022:2006 |
MaxiCode |
MaxiCode, as defined in ISO/IEC 16023:2000 |
JSON example:
{
"barcodes": [
{
"kind": "Code39",
"value": "Hello World",
"source": "D(1,2.5738,4.8186,3.8617,4.8153,3.8621,4.9894,2.5743,4.9928)",
"span": {"offset": 192, "length": 10 },
"confidence": 0.977
}
]
}
Formulas
A formula is a content element that represents mathematical expressions in the document. It might be an inline formula embedded with other text or a display formula that takes up an entire line. Multiline formulas are represented as multiple display formula elements grouped into paragraphs to preserve mathematical relationships.
JSON example:
{
"formulas": [
{
"confidence": 0.708,
"source": "D(1,3.4282,7.0195,4.0452,7.0307,4.0425,7.1803,3.4255,7.1691)",
"span": {
"offset": 394,
"length": 51
}
}
]
}
Figures
A figure is a content element that represents an embedded image, figure, or chart in the document. Content Understanding extracts any embedded text from the images and any associated captions and footnotes.
JSON example:
{
"figures": [
{
"source": "D(2,1.3465,1.8481,3.4788,1.8484,3.4779,3.8286,1.3456,3.8282)",
"span": {
"offset": 658,
"length": 42
},
"elements": [
"/paragraphs/14"
],
"id": "2.1"
}
]
}
Layout elements
Document layout elements are visual and structural components, such as pages, tables, paragraphs, lines, tables, sections, and overall structure, that help to interpret content. Extracting these elements enables tools to analyze documents efficiently for tasks like information retrieval, semantic understanding, and data structuring.
Pages
A page is a grouping of content that typically corresponds to one side of a sheet of paper. A rendered page is characterized via width and height in the specified unit. In general, images use pixels while PDFs use inches. The angle property describes the overall text angle in degrees for pages that might be rotated.
For spreadsheets like Excel, each sheet is mapped to a page. For presentations, like PowerPoint, each slide is mapped to a page. For file formats like HTML or Word documents, which lack a native page concept without rendering, the entire main content is treated as a single page.
JSON example:
{
"pages": [
{
"pageNumber": 1,
"angle": 0.0739153,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 0,
"length": 620
}
],
"words": [ /* array of word objects */ ],
"barcodes": [ /* details of barcodes */ ],
"lines": [ /* array of line objects */ ],
"formulas": [ /* array of formula objects */ ]
}
]
}
Paragraphs
A paragraph is an ordered sequence of lines that form a logical unit. Typically, the lines share common alignment and spacing between lines. Paragraphs are often delimited via indentation, added spacing, or bullets/numbering. Some paragraphs have special functional roles in the document. Currently supported roles include page header, page footer, page number, title, section heading, footnote, and formula block.
JSON example:
{
"paragraphs": [
{
"role": "title",
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1584,1.0795,4.1589,1.4083,1.2644,1.4124)",
"span": {
"offset": 0,
"length": 18
}
}
]
}
Lines
A line is an ordered sequence of consecutive content elements, which are often separated by visual spaces. Content elements in the same horizontal plane (row) but that are separated by more than a single visual space are most often split into multiple lines. This feature sometimes splits semantically contiguous content into separate lines. It also enables the representation of textual content split into multiple columns or cells. Lines in vertical writing are detected in the vertical direction.
JSON example:
{
"lines": [
{
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1583,1.0795,4.1589,1.4083,1.2645,1.4117)",
"span": {
"offset": 0,
"length": 16
}
}
]
}
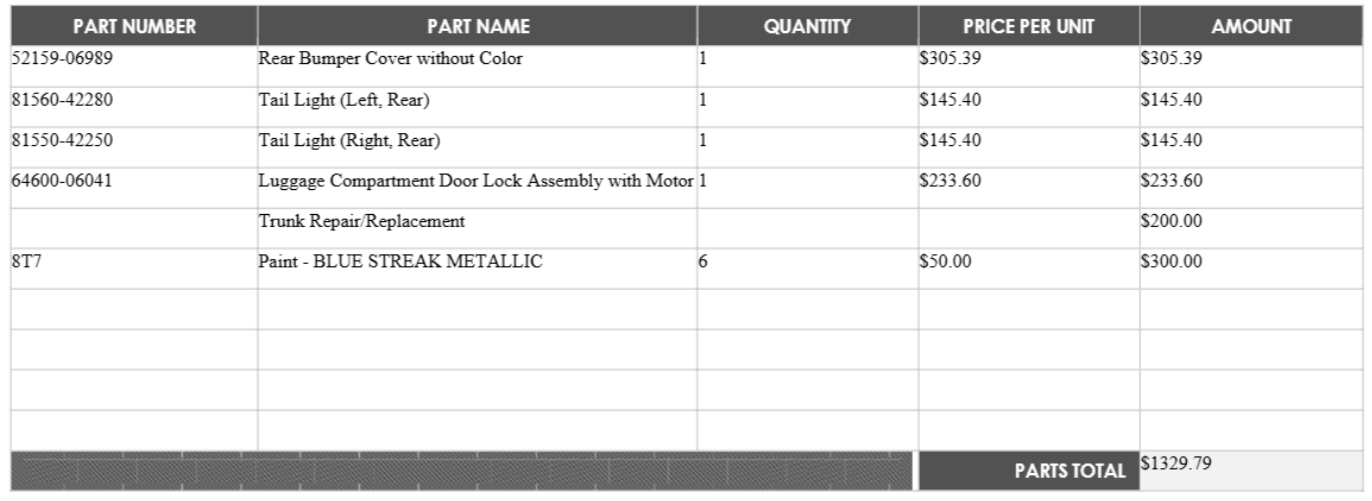
Tables
A table organizes content into a group of cells in a grid layout. The rows and columns might be visually separated by grid lines, color banding, or greater spacing. The position of a table cell is specified via its row and column indices. A cell can span across multiple rows and columns.
Based on its position and styling, a cell is classified as general content, row header, column header, stub head, or description:
- A row header cell is typically the first cell in a row that describes the other cells in the row.
- A column header cell is typically the first cell in a column that describes the other cells in a column.
- A row or column can contain multiple header cells to describe hierarchical content.
- A stub head cell is typically the cell in the first row and first column position. The cell is either empty or describes the values in the header cells in the same row/column.
- A description cell generally appears at the uppermost or lowermost area of a table and describes the overall table content. It can sometimes appear in the middle of a table to break the table into sections. Typically, description cells span across multiple cells in a single row.
A table caption specifies content that explains the table. A table can also have a set of footnotes. Unlike a description cell, a caption typically lies outside the grid layout. Table footnotes annotate content inside the table and are often marked with footnote symbols. They're often found underneath the table grid.
A table might span across consecutive pages of a document. In this situation, table continuations in subsequent pages generally maintain the same column count, width, and styling. They often repeat the column headers. Typically, no intervening content comes between the initial table and its continuations except for page headers, footers, and page numbers.
The span for tables covers only the core content and excludes associated captions and footnotes.
A table might span across consecutive pages of a document. In this situation, table continuations in subsequent pages generally maintain the same column count, width, and styling. They often repeat the column headers. Other than page headers, footers, and page numbers, there's generally no intervening content between the initial table and its continuations.
Note
The span for tables covers only the core content and excludes associated captions and footnotes.
JSON example:
{
"tables": [
{
"rowCount": 6,
"columnCount": 2,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"rowSpan": 1,
"columnSpan": 1,
"content": "Category",
"source": "D(2,1.1674,5.0483,4.1733,5.0546,4.1733,5.2358,1.1674,5.2358)",
"span": {
"offset": 798,
"length": 8
}
}
],
"source": "D(2,1.1566,5.0425,7.1855,5.0428,7.1862,6.1853,1.1574,6.1858)",
"span": {
"offset": 781,
"length": 280
}
}
]
}
Sections
A section is a logical grouping of related content elements that form a hierarchical structure within the document. It often starts with a section heading as the first paragraph. A section might contain subsections to create a nested document structure that preserves semantic relationships.
JSON example:
{
"sections": [
{
"span": {
"offset": 113,
"length": 77
},
"elements": [
"/paragraphs/3",
"/paragraphs/4"
]
}
]
}
Element properties
Documents consist of various components that are categorized into structural, textual, and form-related elements. These elements define the organization and presentation of the document. You can systematically identify and extract the elements for further analysis or application.
Spans
The span property specifies the logical position of the element in the document via the character offset and length into the top-level markdown string property. By default, character offsets and lengths are returned in Unicode code points, which are used by Python 3. To accommodate different development environments that use different character units, you can specify the stringEncoding query parameter to return span offsets and lengths in UTF16 code units (Java, JavaScript, or .NET) or UTF8 bytes (Go, Rust, Ruby, or PHP).
Source
The source property describes the visual position of the element in the file by using an encoded string. For documents, the source string is in one of the following formats:
- Bounding polygon:
D({pageNumber},{x1},{y1},{x2},{y2},{x3},{y3},{x4},{y4}) - Axis-aligned bounding box:
D({pageNumber},{left},{top},{width},{height})
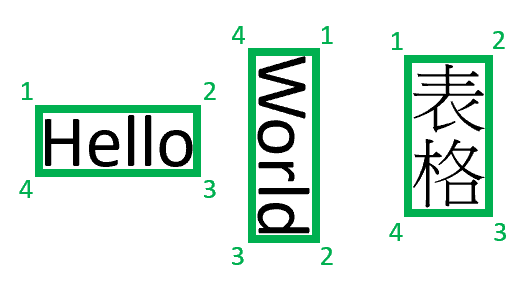
Page numbers are one indexed. The bounding polygon describes a sequence of points, clockwise from the left relative to the natural orientation of the element. For quadrilaterals, the points represent the upper-left, upper-right, lower-right, and lower-left corners. Each point represents the x,y coordinate in the length unit specified by the unit property. In general, the unit of measure for images is pixels. PDFs use inches.
Note
Currently, Content Understanding returns only a four-point quadrilateral as a bounding polygon. Future versions might return a different number of points to describe more complex shapes, such as curved lines or nonrectangular images. Currently, source is returned only for elements from rendered files (PDF/image).
Related content
- Process your document content by using Content Understanding in Azure AI Foundry.
- Learn to analyze document content with analyzer templates.
- Review code samples with visual document search.
- Review the code sample analyzer templates.
Complete JSON example
The following example shows the complete JSON response structure from analyzing a document. This JSON represents the full output from Content Understanding when you process a PDF document with multiple element types:

{
"id": "10a01d32-e21e-46e3-bb5c-361375f184de",
"status": "Succeeded",
"result": {
"analyzerId": "auto-labeling-model-1750287025291-104",
"apiVersion": "2025-05-01-preview",
"createdAt": "2025-06-18T22:50:34Z",
"warnings": [],
"contents": [
{
"markdown": "# Example Document\n\n\n## 1. Selection Marks (Checkboxes)\n\nEmployee Preferences Form\n☐\nRemote\n☒\nHybrid\n☐\nOn-site\n\n\n## 2. Barcodes\n\nGo check out Azure AI Content Understanding at the below link\n\n\n## 3. Formulas\n\nBayesian Inference (Posterior Probability):\n\n$$P \\left( \\theta \\mid D \\right) = \\frac { P \\left( D \\mid \\theta \\right) \\cdot P \\left( \\theta \\right) } { P \\left( D \\right) }$$\n\nWhere:\n\n$$P \\left( \\theta \\mid D \\right)$$\nis the posterior\n\n$P \\left( D \\mid \\theta \\right)$ is the likelihood\n$P \\left( \\theta \\right)$ is the prior\n\n$$P \\left( D \\right) i s \\quad t h e \\quad e v i d e n c e$$\n\n<!-- PageBreak -->\n\n\n## 4. Images\n\nSample Product Image\n\n\n<figure>\n\nContent\nUnderstanding\n\n</figure>\n\n\nImage Description: \"A ceramic coffee mug with company logo.\"\n\n\n## 5. Tables\n\n\n<table>\n<tr>\n<th>Category</th>\n<th>Amount ($)</th>\n</tr>\n<tr>\n<td>Rent</td>\n<td>1,200</td>\n</tr>\n<tr>\n<td>Utilities</td>\n<td>150</td>\n</tr>\n<tr>\n<td>Groceries</td>\n<td>300</td>\n</tr>\n<tr>\n<td>Transportation</td>\n<td>100</td>\n</tr>\n<tr>\n<td>Total</td>\n<td>1,750</td>\n</tr>\n</table>\n\n\n## 6. Paragraphs\n\nOur company is committed to fostering a productive and inclusive work environment. All\nemployees are expected to comply with the outlined policies and demonstrate mutual\nrespect in day-to-day operations. Regular reviews will ensure that these policies remain\nrelevant and effective.\n",
"fields": {
"EmployeePreferences": {
"type": "string",
"valueString": "Hybrid",
"spans": [
{
"offset": 94,
"length": 6
}
],
"confidence": 0.987,
"source": "D(1,1.4104,2.7836,1.8760,2.7823,1.8760,2.9377,1.4110,2.9396)"
},
"ImageDescription": {
"type": "string",
"valueString": "\"A ceramic coffee mug with company logo.\"",
"spans": [
{
"offset": 722,
"length": 41
}
],
"confidence": 0.958,
"source": "D(2,2.5222,4.2511,5.3236,4.2497,5.3237,4.4422,2.5223,4.4436)"
}
},
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 2,
"unit": "inch",
"pages": [
{
"pageNumber": 1,
"angle": 0.0739153,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 0,
"length": 620
}
],
"words": [
{
"content": "Example",
"span": {
"length": 7
},
"confidence": 0.992,
"source": "D(1,1.265,1.0836,2.4972,1.0816,2.4964,1.4117,1.2645,1.4117)"
},
{
"content": "Document",
"span": {
"length": 8
},
"confidence": 0.996,
"source": "D(1,2.6252,1.084,4.1615,1.0886,4.1615,1.3993,2.6241,1.4117)"
},
{
"content": "☒",
"span": {
"length": 1
},
"confidence": 0.983,
"source": "D(1,1.258,2.7952,1.3705,2.7949,1.371,2.9098,1.2575,2.9089)"
},
{
"content": "Hybrid",
"span": {
"length": 6
},
"confidence": 0.996,
"source": "D(1,1.4104,2.7836,1.876,2.7823,1.876,2.9377,1.411,2.9396)"
}
],
"lines": [
{
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1583,1.0795,4.1589,1.4083,1.2645,1.4117)",
"span": {
"offset": 0,
"length": 16
}
}
],
"formulas": [
{
"confidence": 0.583
},
{
"confidence": 0.708
}
]
},
{
"pageNumber": 2,
"angle": 0.1008425,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 620,
"length": 744
}
],
"words": [
{
"content": "Images",
"source": "D(2,1.4516,1.0434,2.0254,1.0463,2.0254,1.229,1.4506,1.224)"
},
{
"content": "ceramic",
"source": "D(2,2.5230,4.2539,2.6591,4.2543,2.6584,4.4392,2.5223,4.4407)"
}
],
"lines": [
{
"content": "4. Images",
"source": "D(2,1.24,1.0409,2.0238,1.0463,2.0226,1.2284,1.2387,1.223)"
}
]
}
],
"paragraphs": [
{
"role": "title",
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1584,1.0795,4.1589,1.4083,1.2644,1.4124)",
"span": {
"offset": 0,
"length": 18
}
},
{
"role": "sectionHeading",
"content": "1. Selection Marks (Checkboxes)",
"source": "D(1,1.2461,1.8719,3.8532,1.8731,3.8531,2.065,1.246,2.0638)",
"span": {
"offset": 21,
"length": 34
}
},
{
"content": "Employee Preferences Form ☐ Remote ☒ Hybrid ☐ On-site",
"source": "D(1,1.246,2.0993,3.1019,2.1007,3.101,3.2724,1.2451,3.2709)",
"span": {
"offset": 57,
"length": 53
}
}
],
"sections": [
{
"span": {
"offset": 0,
"length": 1364
},
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/3",
"/sections/4",
"/sections/5",
"/sections/6"
]
},
{
"span": {
"offset": 21,
"length": 89
},
"elements": [
"/paragraphs/1",
"/paragraphs/2"
]
}
],
"tables": [
{
"rowCount": 6,
"columnCount": 2,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"rowSpan": 1,
"columnSpan": 1,
"content": "Category",
"source": "D(2,1.1674,5.0483,4.1733,5.0546,4.1733,5.2358,1.1674,5.2358)",
"span": {
"offset": 798,
"length": 8
}
},
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 1,
"rowSpan": 1,
"columnSpan": 1,
"content": "Amount ($)",
"source": "D(2,4.1733,5.0546,7.1668,5.0546,7.1668,5.2358,4.1733,5.2358)",
"span": {
"offset": 816,
"length": 10
}
}
],
"source": "D(2,1.1566,5.0425,7.1855,5.0428,7.1862,6.1853,1.1574,6.1858)",
"span": {
"offset": 781,
"length": 280
}
}
],
"figures": [
{
"source": "D(2,1.3465,1.8481,3.4788,1.8484,3.4779,3.8286,1.3456,3.8282)",
"span": {
"offset": 658,
"length": 42
},
"elements": [
"/paragraphs/14"
],
"id": "2.1"
}
]
}
]
}
}
This complete example demonstrates how Content Understanding extracts and structures all the different element types from a document. It provides both the raw content and the detailed positional and structural information that enables advanced document processing workflows.