Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
- Foundry Local is available in preview. Public preview releases provide early access to features that are in active deployment.
- Features, approaches, and processes can change or have limited capabilities, before General Availability (GA).
Foundry Local enables efficient, secure, and scalable AI model inference directly on your devices. This article explains the core components of Foundry Local and how they work together to deliver AI capabilities.
Key benefits of Foundry Local include:
- Low Latency: Run models locally to minimize processing time and deliver faster results.
- Data Privacy: Process sensitive data locally without sending it to the cloud, helping meet data protection requirements.
- Flexibility: Support for diverse hardware configurations lets you choose the optimal setup for your needs.
- Scalability: Deploy across various devices, from laptops to servers, to suit different use cases.
- Cost-Effectiveness: Reduce cloud computing costs, especially for high-volume applications.
- Offline Operation: Work without an internet connection in remote or disconnected environments.
- Seamless Integration: Easily incorporate into existing development workflows for smooth adoption.
Key components
The Foundry Local architecture consists of these main components:
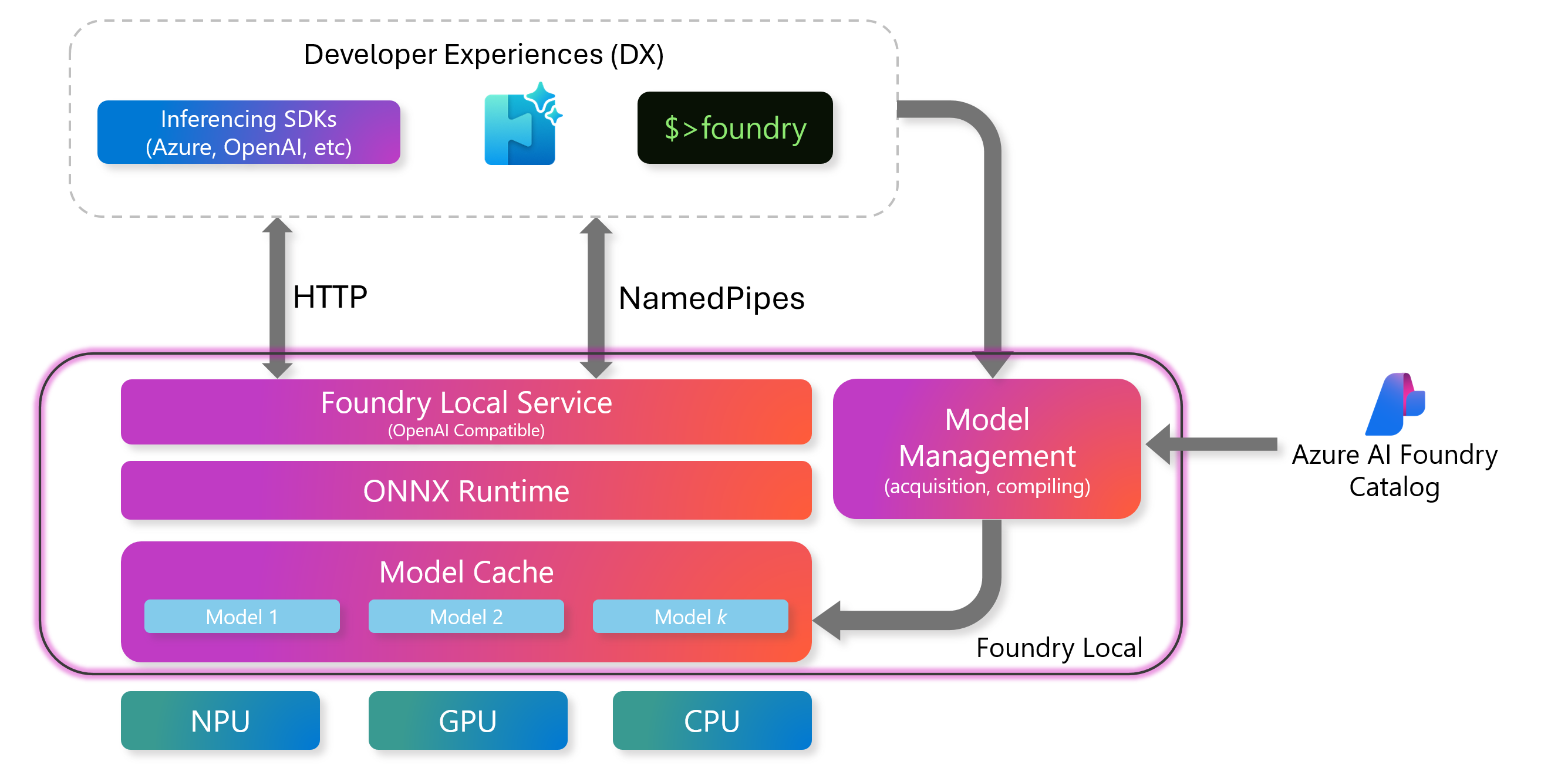
Foundry Local service
The Foundry Local Service includes an OpenAI-compatible REST server that provides a standard interface for working with the inference engine. It's also possible to manage models over REST. Developers use this API to send requests, run models, and get results programmatically.
- Endpoint: The endpoint is dynamically allocated when the service starts. You can find the endpoint by running the
foundry service statuscommand. When using Foundry Local in your applications, we recommend using the SDK that automatically handles the endpoint for you. For more details on how to use the Foundry Local SDK, read the Integrated inferencing SDKs with Foundry Local article. - Use Cases:
- Connect Foundry Local to your custom applications
- Execute models through HTTP requests
ONNX runtime
The ONNX Runtime is a core component that executes AI models. It runs optimized ONNX models efficiently on local hardware like CPUs, GPUs, or NPUs.
Features:
- Works with multiple hardware providers (NVIDIA, AMD, Intel, Qualcomm) and device types (NPUs, CPUs, GPUs)
- Offers a consistent interface for running across models different hardware
- Delivers best-in-class performance
- Supports quantized models for faster inference
Model management
Foundry Local provides robust tools for managing AI models, ensuring that they're readily available for inference and easy to maintain. Model management is handled through the Model Cache and the Command-Line Interface (CLI).
Model cache
The model cache stores downloaded AI models locally on your device, which ensures models are ready for inference without needing to download them repeatedly. You can manage the cache using either the Foundry CLI or REST API.
- Purpose: Speeds up inference by keeping models locally available
- Key Commands:
foundry cache list: Shows all models in your local cachefoundry cache remove <model-name>: Removes a specific model from the cachefoundry cache cd <path>: Changes the storage location for cached models
Model lifecycle
- Download: Download models from the Azure AI Foundry model catalog and save them to your local disk.
- Load: Load models into the Foundry Local service memory for inference. Set a TTL (time-to-live) to control how long the model stays in memory (default: 10 minutes).
- Run: Execute model inference for your requests.
- Unload: Remove models from memory to free up resources when no longer needed.
- Delete: Remove models from your local cache to reclaim disk space.
Model compilation using Olive
Before models can be used with Foundry Local, they must be compiled and optimized in the ONNX format. Microsoft provides a selection of published models in the Azure AI Foundry Model Catalog that are already optimized for Foundry Local. However, you aren't limited to those models - by using Olive. Olive is a powerful framework for preparing AI models for efficient inference. It converts models into the ONNX format, optimizes their graph structure, and applies techniques like quantization to improve performance on local hardware.
Tip
To learn more about compiling models for Foundry Local, read How to compile Hugging Face models to run on Foundry Local.
Hardware abstraction layer
The hardware abstraction layer ensures that Foundry Local can run on various devices by abstracting the underlying hardware. To optimize performance based on the available hardware, Foundry Local supports:
- multiple execution providers, such as NVIDIA CUDA, AMD, Qualcomm, Intel.
- multiple device types, such as CPU, GPU, NPU.
Developer experiences
The Foundry Local architecture is designed to provide a seamless developer experience, enabling easy integration and interaction with AI models. Developers can choose from various interfaces to interact with the system, including:
Command-Line Interface (CLI)
The Foundry CLI is a powerful tool for managing models, the inference engine, and the local cache.
Examples:
foundry model list: Lists all available models in the local cache.foundry model run <model-name>: Runs a model.foundry service status: Checks the status of the service.
Tip
To learn more about the CLI commands, read Foundry Local CLI Reference.
Inferencing SDK integration
Foundry Local supports integration with various SDKs in most languages, such as the OpenAI SDK, enabling developers to use familiar programming interfaces to interact with the local inference engine.
Tip
To learn more about integrating with inferencing SDKs, read Integrate inferencing SDKs with Foundry Local.
AI Toolkit for Visual Studio Code
The AI Toolkit for Visual Studio Code provides a user-friendly interface for developers to interact with Foundry Local. It allows users to run models, manage the local cache, and visualize results directly within the IDE.
Features:
- Model management: Download, load, and run models from within the IDE.
- Interactive console: Send requests and view responses in real-time.
- Visualization tools: Graphical representation of model performance and results.
Prerequisites:
- You have installed Foundry Local and have a model service running.
- You have installed the AI Toolkit for Visual Studio Code extension.
Connect Foundry Local model to AI Toolkit:
- Add model in AI Toolkit: Open AI Toolkit from the activity bar of Visual Studio Code. In the 'My Models' panel, click the 'Add model for remote interface' button and then select 'Add a custom model' from the dropdown menu.
- Enter the chat compatible endpoint URL: Enter
http://localhost:PORT/v1/chat/completionswhere PORT is replaced with the port number of your Foundry Local service endpoint. You can see the port of your locally running service using the CLI commandfoundry service status. Foundry Local dynamically assigns a port, so it might not always the same. - Provide model name: Enter the exact model name you which to use from Foundry Local, for example
phi-3.5-mini. You can list all previously downloaded and locally cached models using the CLI commandfoundry cache listor usefoundry model listto see all available models for local use. You’ll also be asked to enter a display name, which is only for your own local use, so to avoid confusion it’s recommended to enter the same name as the exact model name. - Authentication: If your local setup doesn't require authentication (which is the default for a Foundry Local setup), you can leave the authentication headers field blank and press Enter.
After completing these steps, your Foundry Local model will appear in the 'My Models' list in AI Toolkit and is ready to be used by right-clicking on your model and select 'Load in Playground'.